


本篇内容转载自「锦秋集」
semianalysis写了一篇文章,通过深入分析DeepSeek和Anthropic两家公司的策略选择,揭示了一个行业共同面临的根本挑战:计算资源的稀缺。
DeepSeek R1发布128天后的数据呈现出一个看似矛盾的现象:官方平台用户流失,但第三方托管的模型使用量却暴增20倍。为什么用户会抛弃价格极低的官方服务,转而选择第三方平台?
本文通过Token经济学这一分析框架找到了答案。
文章指出,AI服务的定价本质上是三个性能指标的权衡游戏。
第一是延迟,即用户发送请求到收到第一个字符的等待时间;
第二是吞吐量,即模型每秒能生成多少个token,直接影响对话的流畅度;
第三是上下文窗口,决定了模型能”记住”多少对话历史,对于分析长文档或大型代码库至关重要。
关键洞察在于:通过调整这三个参数,服务商可以实现任何价格水平。
DeepSeek选择了极端配置——数秒的延迟、每秒仅25个token的输出速度、业界最小的64K上下文窗口,换取了极低的价格和最大化的研发资源。
有趣的是,作为西方AI领军企业的Anthropic也面临着相似的困境。Claude在编程领域的巨大成功反而加剧了计算资源的紧张,导致API输出速度下降30%。为了应对这一挑战,Anthropic不得不向亚马逊和Google寻求大规模的计算支持。
本文超越了表面的价格战和市场份额之争,深入剖析了AI公司在计算资源、用户体验和技术发展之间的复杂权衡。
DeepSeek选择牺牲用户体验换取研发资源,通过开源策略扩大影响力;Anthropic则通过提升”智能密度”来优化资源利用效率。这两种截然不同却同样理性的策略,恰恰反映了计算资源作为AI时代”新石油”的根本性制约作用。
随着推理云服务的崛起和AI应用的普及,如何在有限的计算资源下实现技术突破和商业成功的平衡,将成为决定AI公司命运的关键。这份报告为理解这一核心议题提供了极具洞察力的分析框架。
以下为原文内容。
原文:https://semianalysis.com/2025/07/03/deepseek-debrief-128-days-later/
超 9000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

-
最新、最值得关注的 AI 新品资讯;
-
不定期赠送热门新品的邀请码、会员码;
-
最精准的AI产品曝光渠道
尽管 AI 的进步通常被归功于 transformers、RNNs 或 diffusion 等里程碑式的研究,但这种看法忽略了人工智能的根本瓶颈:数据。拥有好的数据意味着什么?
如果我们真心希望推动 AI 的发展,那我们应该研究的不是深度学习优化,而是互联网本身。互联网才是真正解锁了 AI 模型规模化扩展(scaling)的技术。
DeepSeek R1发布至今已过去150多天。当时,它作为首个公开发布的、能与OpenAI推理能力相匹配的模型,震撼了整个股市和西方AI界。
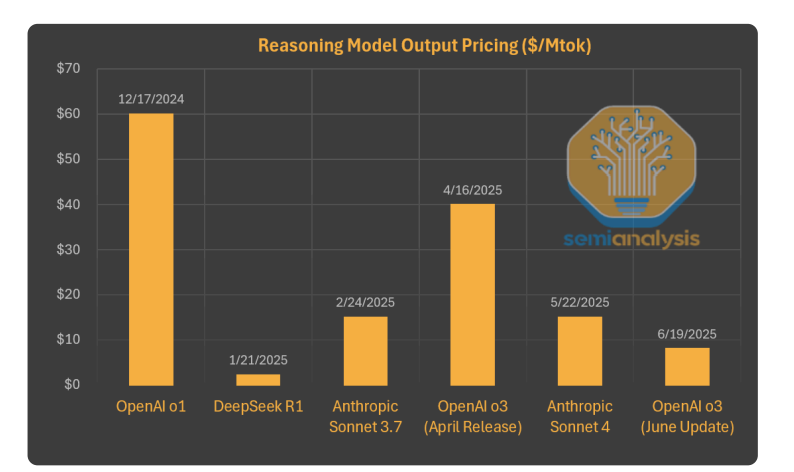
然而,真正引发恐慌的是其极低的定价策略——输入仅需0.55美元/百万token,输出仅需2.19美元/百万token,比当时最先进的o1模型便宜了90%以上。市场担心DeepSeek(乃至整个中国)会让AI模型彻底商品化。
此后,推理模型的价格战愈演愈烈,OpenAI最近也将旗舰模型降价80%。
值得注意的是,DeepSeek在发布后继续通过强化学习(RL)不断迭代升级。模型在多个领域都有显著提升,尤其是编程能力。这种持续迭代改进正是我们之前分析过的AI发展新范式的典型特征。
今天,我们将深入分析DeepSeek对AI模型竞赛格局的影响,以及当前AI市场份额的变化情况。
01
AI热潮之后的冷静
用户增长的昙花一现
DeepSeek刚发布时,消费端应用流量确实出现了爆发式增长,市场份额急剧攀升。但需要注意的是,由于难以准确追踪中国用户数据,加上西方AI实验室在中国无法访问,以下数据实际上低估了DeepSeek的真实覆盖范围。
尽管如此,这种爆发式增长并未持续。与其他AI应用相比,DeepSeek的增长势头明显放缓,市场份额开始下滑。
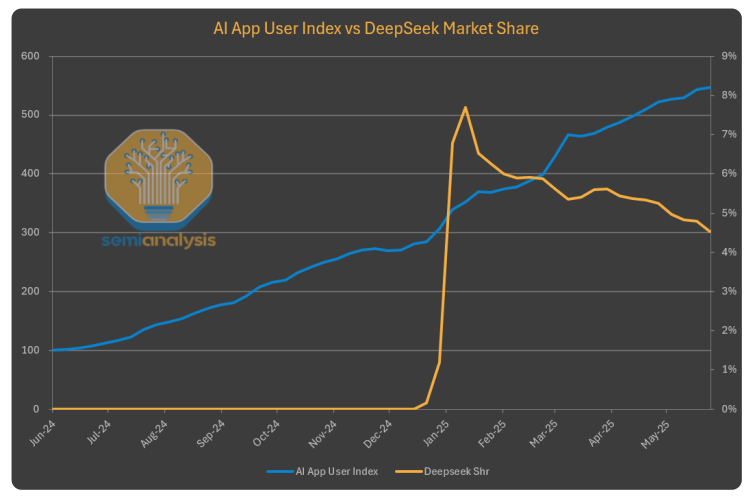
网页端的数据更能说明问题——DeepSeek的流量自发布以来持续下降,而同期其他主要AI服务商的用户数量都在稳步增长。
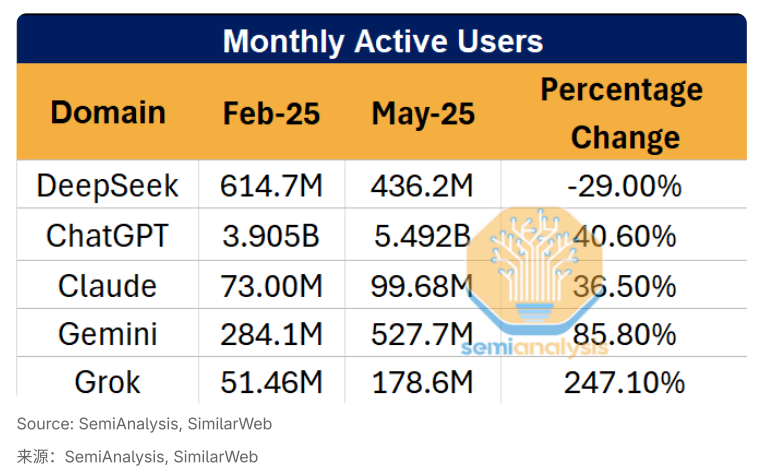
第三方平台的逆势增长
有趣的是,虽然DeepSeek自有平台表现不佳,但在第三方平台上托管的DeepSeek模型却呈现完全不同的景象。R1和V3在第三方平台的使用量持续飙升,比R1刚发布时增长了近20倍。
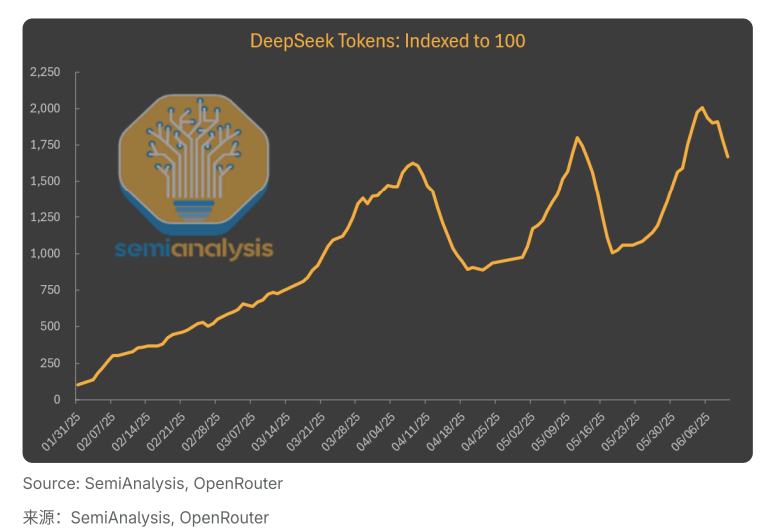
进一步分析数据发现,如果只看DeepSeek自己托管的token使用量,其在总token中的占比每月都在下降。
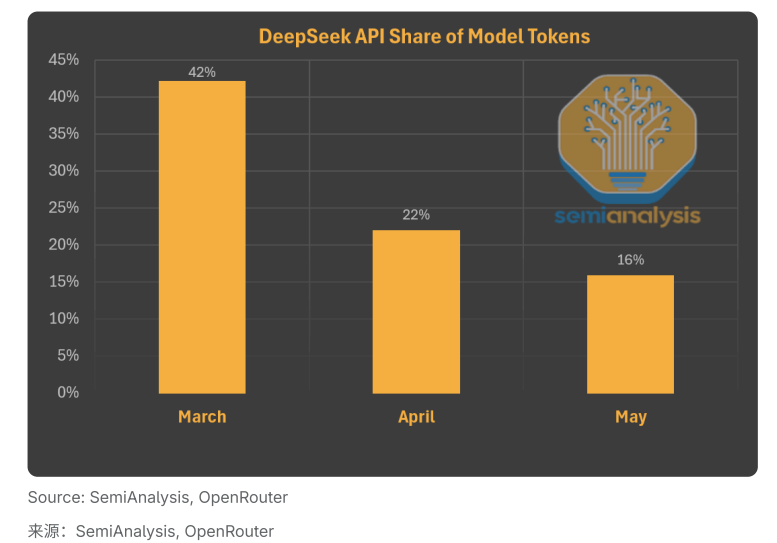
这就引出了一个关键问题:既然DeepSeek的模型越来越受欢迎,价格又极具竞争力,为什么用户纷纷放弃官方平台,转向其他开源服务商?
答案就在token经济学中。
02
Token经济学的奥秘
理解AI服务的本质
在AI世界里,token是最基本的单位。AI模型通过阅读互联网上的token来学习,然后输出文本、音频、图像或动作token。简单来说,token就是文本的最小单位(比如”fan”、”tas”、”tic”),大语言模型处理的是这些小单位,而不是完整的词或字母。
当黄仁勋(Jensen)谈到数据中心变成AI工厂时,这些工厂的原料和产品都是token。就像传统工厂一样,AI工厂的盈利模式也遵循P×Q公式:P是每个token的价格,Q是输入输出token的总量。
但与传统工厂不同的是,token价格并非固定不变。模型服务商可以根据以下三个关键指标来灵活调整定价:
三大关键性能指标(KPI)
-
延迟(Time-to-First-Token) 指模型生成第一个token需要多长时间。技术上说,这是模型完成prefix阶段(将输入token编码到KV Cache)并开始在decode阶段产生第一个token所需的时间。
-
吞吐量(Throughput)或交互性 指token的生成速度,通常以”每秒每用户token数”来衡量。有些服务商也用TPOT(Time Per Output Token)这个反向指标。作为参考,人类阅读速度约为每秒3-5个词,而大多数模型的输出速度设定在每秒20-30个token。
-
上下文窗口(Context Window) 指模型的”短期记忆”容量——在遗忘早期对话内容之前,能保存多少token。不同应用场景需要不同大小的上下文窗口。比如,分析大型文档或代码库就需要更大的上下文窗口,这样模型才能完整理解并推理整个内容。
关键在于:通过调整这三个指标,服务商可以实现任何价格水平。因此,单纯比较每百万token的价格($/Mtok)意义不大,因为这忽略了实际应用场景和用户需求。
03
DeepSeek的策略选择
价格背后的真相
让我们通过token经济学的视角,分析DeepSeek为何在自家模型上逐渐失去市场份额。
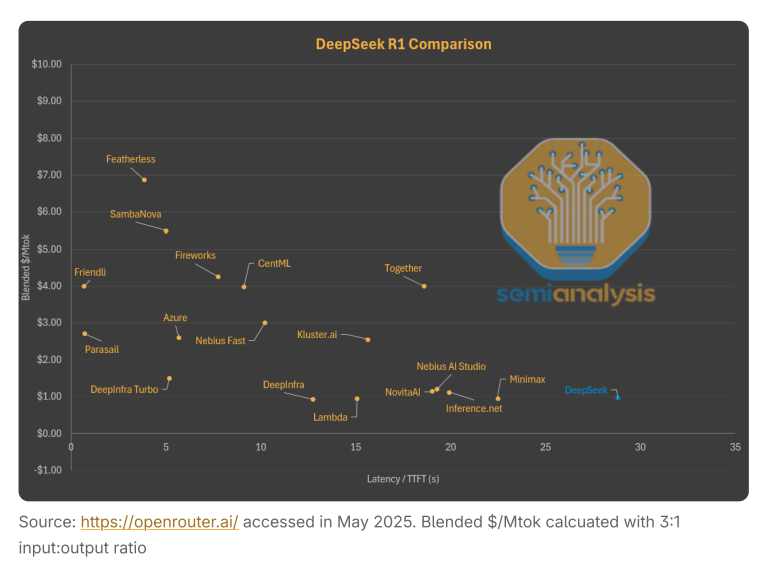
从延迟与价格的关系图可以看出,DeepSeek的官方服务已经不是同等延迟下最便宜的选择。实际上,DeepSeek之所以能提供如此低价,主要是因为他们让用户等待数秒才能收到第一个token的响应。相比之下,其他服务商以同样的价格提供服务,但响应时间快得多。
用户可以选择向Perplexity AI或Friendli支付2-3美元,获得几乎零延迟的服务。微软Azure的价格虽然是DeepSeek的2.5倍,但延迟少了25秒。更糟糕的是,现在几乎所有R1 0528实例都由延迟低于5秒的服务商托管。
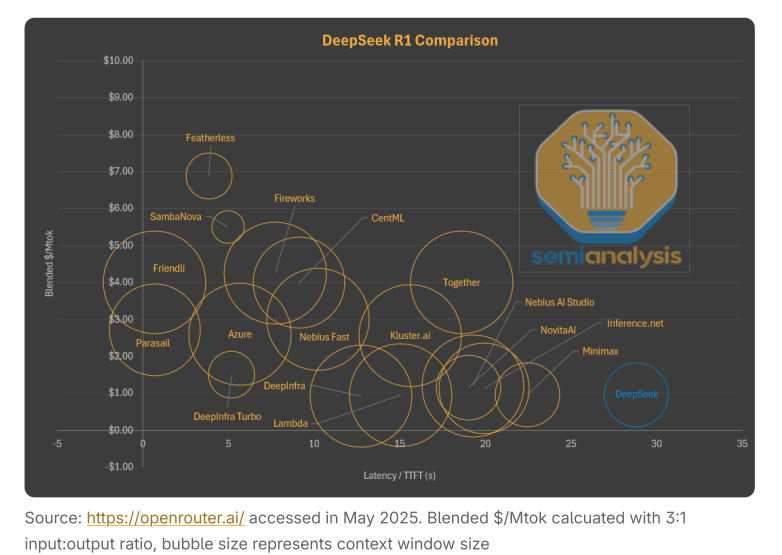
如果我们再加入context window这个维度,DeepSeek的另一个妥协就显而易见了。为了在有限的推理计算资源下提供超低价服务,他们只提供64K的context window——这是主流服务商中最小的。
较小的context window严重限制了编程等应用场景,因为这些场景需要模型记住大量代码片段才能进行有效推理。在同样的价格下,Lambda和Nebius等服务商能提供2.5倍大的context window。
硬件层面的权衡
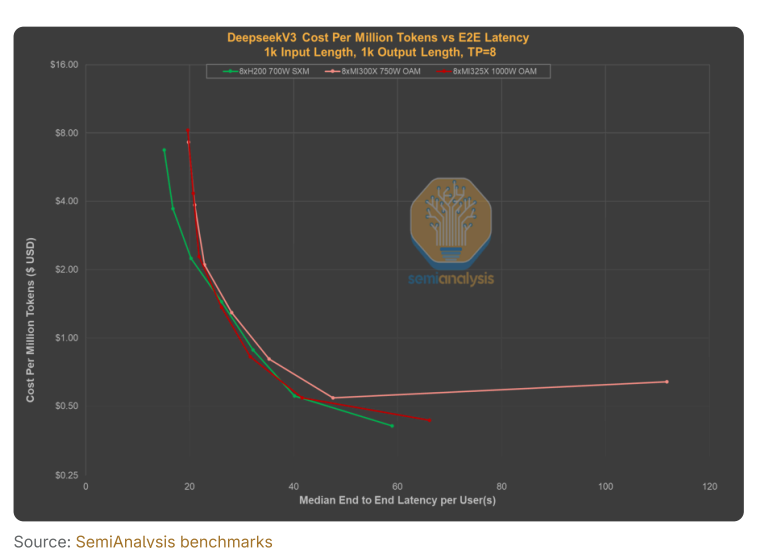
通过对DeepSeek V3在AMD和NVIDIA芯片上的benchmark测试,我们可以看到服务商是如何优化每token成本的:通过在单个GPU或GPU集群上同时处理更多用户请求(batching),服务商可以降低每token的成本,代价是用户需要忍受更高的延迟和更慢的响应速度。
Batch size越大、throughput越低,每token成本就越低,但用户体验会大打折扣。
DeepSeek的真实意图
需要明确的是,这是DeepSeek的主动选择。他们并不想通过用户服务赚钱,也不想通过聊天应用或API服务大量输出token。公司的唯一目标是实现AGI(通用人工智能),对终端用户体验并不关心。
通过极高的batch率,他们将推理和对外服务所需的计算资源降到最低,从而将最大量的计算资源保留用于内部研发。正如我们之前分析的,出口管制确实限制了中国在大规模模型服务方面的能力。
在这种情况下,开源成为DeepSeek的最佳选择。他们将计算资源留在内部,让其他云服务商托管他们的模型,从而赢得全球影响力和市场采用率。虽然出口管制严重限制了中国大规模部署推理服务的能力,但并未同等程度地阻碍他们训练优秀模型的能力——腾讯、阿里巴巴、百度甚至小红书最近发布的成果都证明了这一点。
04
Anthropic的相似困境
计算资源的普遍瓶颈
在AI领域,计算资源就是一切。和DeepSeek一样,Anthropic也面临计算资源紧张的问题。
Anthropic将产品重点放在了编程领域,在Cursor等编程应用中获得了广泛采用。我们认为Cursor的使用情况是最好的评判标准,因为它反映了用户最关心的两个要素:成本和体验。Anthropic在这方面已经保持领先地位超过一年——在AI行业,这相当于几十年。
看到Cursor等token消费应用的成功后,Anthropic推出了Claude Code——一个集成在终端中的编程工具。Claude Code的使用量迅速增长,把OpenAI的Codex远远甩在了后面。
Google随后也推出了类似工具:Gemini CLI。虽然功能相似,但Google凭借TPU的计算优势,能够免费为用户提供超大的请求配额。

成功的代价
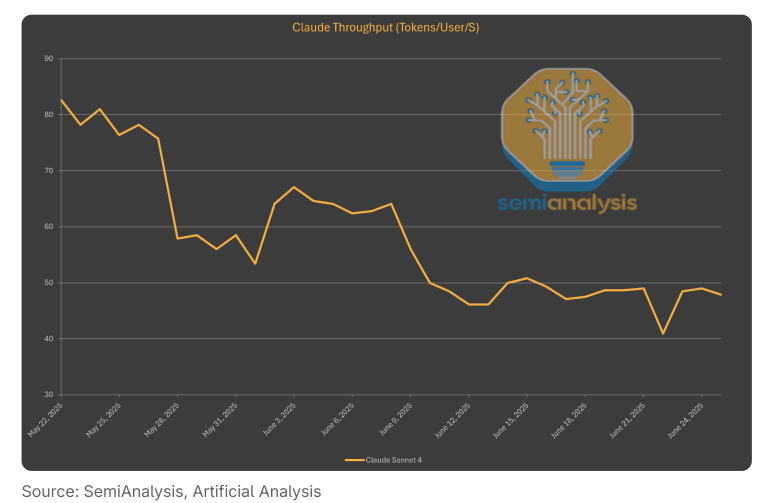
Claude Code虽然性能出色、设计精良,但成本高昂。从某种程度上说,Anthropic在编程领域的成功反而给公司带来了巨大压力——他们的计算资源捉襟见肘。
这一点在Claude 3.5 Sonnet的API输出速度上表现得最为明显。自发布以来,速度下降了30%,现在仅略高于每秒55个token。原因和DeepSeek如出一辙:为了用有限的计算资源处理海量请求,不得不提高batch处理规模。
编程应用通常需要更长的对话(更多token),这比普通聊天应用更加消耗计算资源。相比之下,o3和Gemini 2.5 Pro等竞品的运行速度明显更快,这反映出OpenAI和Google拥有更充足的计算资源。
寻求更多计算资源
Anthropic正在积极获取更多计算资源,已经与亚马逊达成了一项重大合作。
Anthropic将获得超过50万片Trainium芯片用于推理和训练。不过这项合作仍在推进中——尽管外界普遍认为Claude 4是在AWS Trainium上预训练的,但实际上它是用GPU和TPU训练的。
Anthropic还向另一个主要投资方Google寻求计算支持,从GCP租用了大量计算资源,特别是TPU。看到这种模式的成功后,Google Cloud正在向其他AI公司推广类似服务,最近还与OpenAI达成了协议。不过需要澄清的是,Google只向OpenAI提供GPU,而非TPU。
05
效率可以弥补速度
少即是多
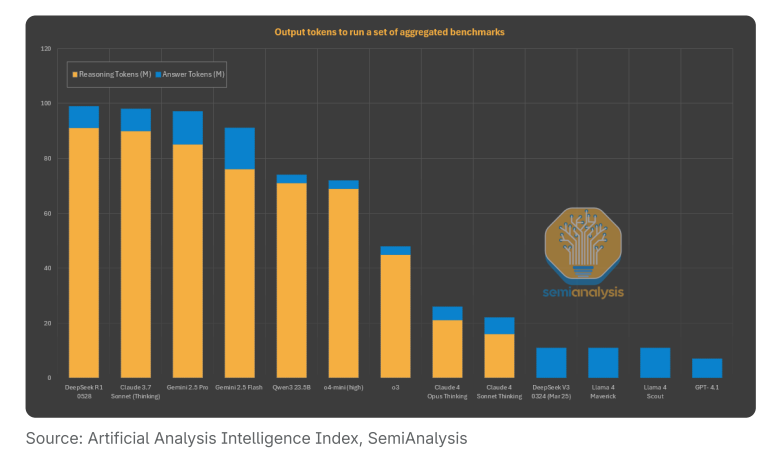
虽然Claude的速度反映了计算资源限制,但Anthropic的整体用户体验仍优于DeepSeek。首先,虽然速度不快,但每秒55个token还是比DeepSeek的25个要好。其次,也是更重要的一点:Anthropic的模型回答问题所需的token数量远少于其他模型。
这意味着尽管单个token的生成速度较慢,但用户获得完整答案的总时间反而更短。
虽然不同任务的情况有所不同,但Gemini 2.5 Pro和DeepSeek R1-0528的输出量是Claude的3倍以上。在运行Artificial Analysis的综合智能指数评测时,Gemini 2.5 Pro、Grok 3和DeepSeek R1使用的token数量明显更多。Claude在所有主流推理模型中输出token数最少,相比Claude 3.5 Sonnet有了显著改进。
这个现象揭示了token经济学的另一个维度:服务商不仅在提升模型智能,更在提升每个token的”智能密度”。
06
推理云服务的崛起
随着Cursor、Windsurf、Replit、Perplexity等”GPT Wrappers”或AI驱动应用走向主流,越来越多公司开始效仿Anthropic的模式——将token作为服务直接销售,而不是像ChatGPT那样打包成月度订阅。
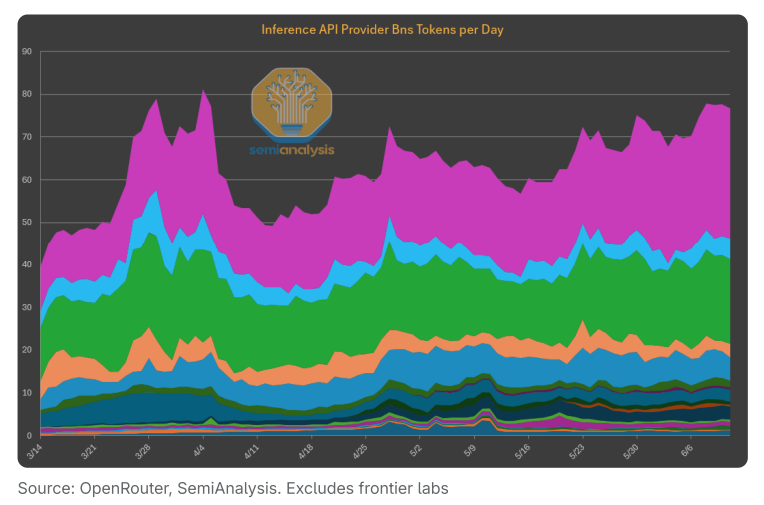
我们相信,随着廉价计算资源的普及以及软硬件的快速创新,这个封闭模式之外的长尾市场将持续增长,成为创新和AI普及的重要推动力。
以代码生成为例,DeepSeek R1能力的提升极大地推动了应用普及。最新的R1版本0528在编程性能上比1月版本有了显著提升。其他实验室的推理模型也在稳步改进。
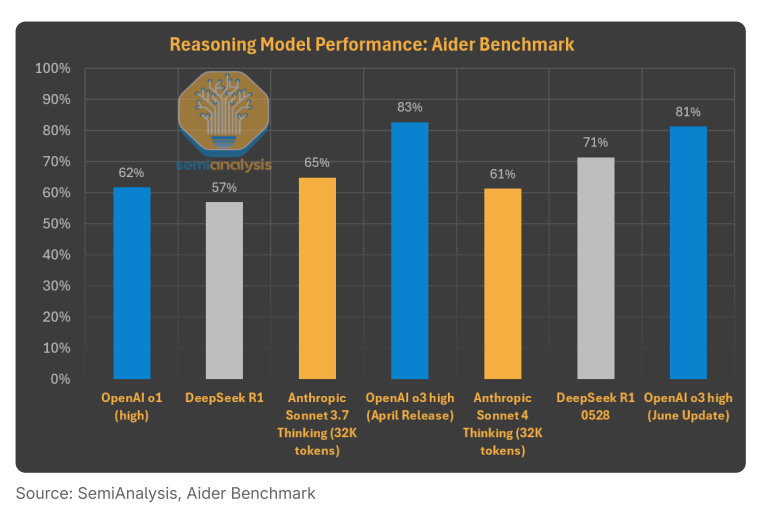
虽然OpenAI在这项特定benchmark中继续保持领先,但R1在成本效益上的巨大优势不容忽视。对于预算有限或需要处理大量任务的用户来说,R1无疑值得一试。
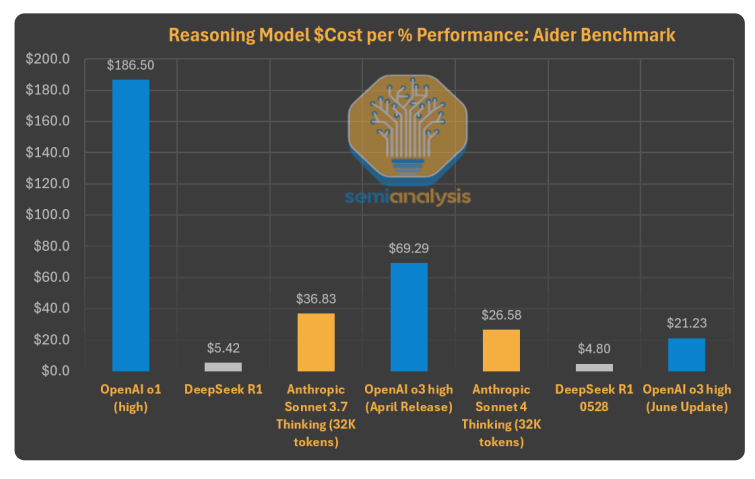
OpenAI在6月将o3 API价格下调80%,可能是对封闭模式与开源方案之间价值差距日益扩大的默认。在Aider benchmark中,这将相对于R1的价格性能比从8-9倍降到了3-5倍。不过我们推测,这次降价的真正目标可能是Anthropic。
07
关于DeepSeek R2延期的真相
组织调整与发展
突如其来的关注让DeepSeek措手不及。公司已将所有研发团队从杭州迁至北京,运营人员数量翻了一倍多,以加强安全保障并应对媒体需求。
虽然组织结构发生了重大变化,但他们保持了核心团队的高效运转。比如,他们的招聘速度仍然远超任何中国大型竞争对手。
延期的真正原因
有报道称DeepSeek R2因出口管制而延期。虽然我们详细讨论过出口管制对中国AI生态的限制作用,但我们认为R2训练延期并非因为出口管制——真正受限的是服务能力。
事实上,R1-0528相比之前版本取得了显著进步,特别是在编程领域。这正是通过扩展RL(强化学习)计算实现的——OpenAI也是通过同样的方法从o1发展到o3。DeepSeek的进步速度依然很快,特别是考虑到他们将大部分计算资源保留用于内部研究。
此外,训练进度放缓可能还有其他原因,比如需要满足额外的审查和安全要求。在中国,DeepSeek仍被视为”国家队”——他们最近还为华为开发最新的Pangu(盘古)模型提供了技术支持。他们依然是开源模型领域的领军者。
08
结语
这份分析揭示了AI行业在计算资源、商业模式和技术发展之间的复杂平衡。DeepSeek选择了一条独特的道路:通过牺牲用户体验来最大化研发资源,通过开源策略扩大全球影响力。而Anthropic等公司则在资源限制下努力优化效率,提供更好的用户体验。
随着推理云服务的兴起和开源生态的发展,AI行业的竞争格局正在重塑。价格战只是表象,真正的较量在于如何在有限资源下实现技术突破,以及如何在商业成功与技术理想之间找到平衡。

(文:Founder Park)