

机器之心PRO · 会员通讯 Week 21
— 本周为您解读 ② 个值得细品的 AI & Robotics 业内要事 —
1. Now, Scaling What?
「Scaling What」的阶段性答案是什么?如何从确定「What to Scale」到搞定「How to Scale」?「Tuning」和「Inference」在后训练中为何同等重要?Scaling Law 正在继续蔓延到哪些领域?…
「蒸馏工厂」是什么?为什么「蒸馏工厂」是开源最大的魅力之一?为何说当前 AI 浪潮是新一轮技术平台革命?微软如何在开源与闭源 AI 模型之间找到战略平衡?…

要事解读① Now, Scaling What?
引言:自 2024 年起,Scaling 范式开始转移,业界在预训练环节的 Scaling Law 边际效益递减、文本数据告罄的限制限制下围绕「Scaling What?」的目标探索不同的范式,并在近期取得了阶段性进展。
预训练之后,What to Scale Now?
1、Scaling Law 在发展中经历了多次质疑和反驳后,业界对「预训练 Scaling Law 的收益在递减」的现状逐步达成共识,「Scaling What」成为了 AI 领域在探索提高模型能力的共同课题。
① 以 2024 年下半年有关「Scaling Law 撞墙」争议为起点,包含 OpenAI 团队、Ilya Sutskever、Anthropic 团队后续在多个场合均阐述了对 Scaling Law 的乐观态度,下一步的主要目标是寻正确的 Scaling 对象。(详见 Pro 会员通讯 2024 Week 48 期)
② 期间,也有 Densing Law(密度定律)、「50%任务完成时间」等工作尝试从不同视角判断模型能力的变化,并对其进行推演。(详见 Pro 会员通讯 2024 Week 50 期)
2、在此趋势下,研究者开始探索新的 Scaling 目标,进而衍生出有关「Self-Play RL+ LLM 」、「Post-Training Scaling Law」、「Test-Time Training」等路线。(详见 Pro 会员通讯 2024 Week 50 期)
① 谷歌 DeepMind 团队在 2024 年 8 月发布了「Scaling LLM Test-Time Compute」论文,是较早公开的探索增加额外的推理时间计算来改进模型输出质量的工作。
② 后续,OpenAI 发布 o1 模型时,有关「更多的强化学习(训练时计算)和更多的思考时间(测试时计算)能让 o1 的性能持续提高」的描述;DeepSeek-R1 用 GRPO 替代 PPO 等工作均吸引了大量的关注,也推动了业界在该路径下的许多探索。
3、伴随 AI 领域开始流行用这种在推理阶段增加计算资源的方法来增强模型的性能,香港城市大学、麦吉尔大学、Mila 和斯坦福等高效的研究者在 2025 年 5 月的综述中将其统称为 TTS(Test-Time Scaling),并通过四个维度对此类工作进行系统性的划分。[1-1]
① 在综述《A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well》中,研究者提出了「What-How-Where-How Well」四轴分类框架,尝试系统拆解推理优化技术。
② 基于四轴分类法,该工作发现当前 AI 领域的研究重点正在从预训练阶段的计算扩展转向推理阶段的计算优化。由此衍生的 TTS 方法也在从简单的重复采样逐渐发展到更复杂的混合扩展和内部扩展策略。
③ 在此之上,TTS 方法的应用范围从特定领域(如数学推理)扩展到更广泛的通用任务(如开放式问答)。
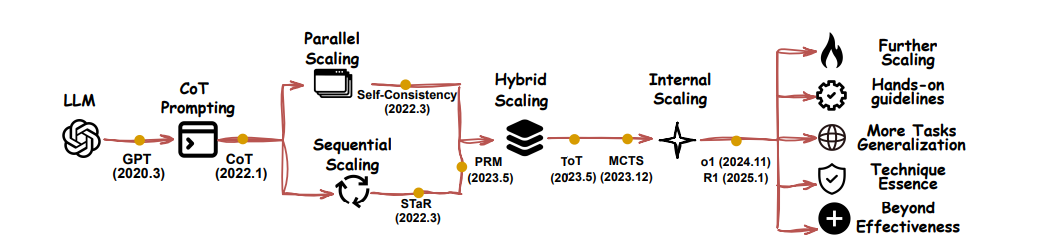
图:Test-Time Scaling 技术的演进路线[1-1]
5、从「What to Scale」的维度出发,研究者以提升 LLM 性能的经验性假设为出发点,尝试梳理哪些 Scaling 对象( 如 CoT 长度、样本数、路径深度、模型内在状态)能够带来帮助,并得到了四条路线。
① Parallel Scaling 策略通过让模型并行生成多个输出,然后将其汇总为最终答案,从而提高测试时性能。其有效性依赖于覆盖度(生成至少一个正确响应的可能性)和聚合质量(能否成功识别出正确响应),具体实现方法则涵盖但模型重采样、扩模型采样、调整超参数和修改输入等。
② Sequential Scaling 策略让模型逐步更新中间状态,用于明确指导后面的计算。这种方式类似于人类的「系统 2」思维,通过分步骤解决问题、细化响应或系统分解问题来提升准确性。
③ Hybrid Scaling 策略结合了 Parallel 和 Sequential 的互补优势,先在迭代中并行候选解,再通过选择函数进行序贯筛选,最终由聚合函数挑选最终解。
④ Internal Scaling 策略让模型自主确定在测试阶段分配多少计算资源用于推理,而不是依赖外部策略(如人类指导)。这种方式(如 OpenAI-o1 和 DeepSeek-R1 等)通过训练过程,让模型学会模仿人类的长推理链,或在测试时自主扩展推理过程。
都是后训练,「微调」 与 「推理」 同等重要?
1、传统的观点认为,预训练奠定了模型的基础能力,而微调则在此基础上对模型进行领域适应,使其更好地服务于特定应用。指令微调、监督式微调(SFT)以及基于人类反馈的强化学习(RLHF)等技术,都旨在通过引入高质量的特定数据来「塑造」模型行为,使其输出更符合预期。
(文:机器之心)