


自 Anthropic 推出 Claude Computer Use,打响电脑智能体(Computer Use Agent)的第一枪后,OpenAI 也相继推出 Operator,用强化学习(RL)算法把电脑智能体的能力推向新高,引发全球范围广泛关注。
业界普遍认为,需要海量的轨迹数据或复杂的强化学习才能实现电脑智能体的水平突破——这可能意味着大量的人工轨迹标注,以及大规模虚拟机环境的构建,以支撑智能体的学习与优化。
然而,来自上海交通大学和 SII 的最新研究却给出了一个非共识答案:仅需 312 条人类标注轨迹,使用 Claude 3.7 Sonnet 合成更丰富的动作决策,就能激发模型 241% 的性能,甚至超越 Claude 3.7 Sonnet extended thinking 模式,成为 Windows 系统上开源电脑智能体的新一代 SOTA。

-
论文标题:Efficient Agent Training for Computer Use
-
论文地址:https://arxiv.org/abs/2505.13909
-
代码地址:https://github.com/GAIR-NLP/PC-Agent-E
-
模型地址:https://huggingface.co/henryhe0123/PC-Agent-E
-
数据地址:https://huggingface.co/datasets/henryhe0123/PC-Agent-E
这一发现传递出一个关键信号:当前大模型已经具备了使用电脑完成任务的基础能力,其性能瓶颈主要在于长程推理(long-horizon planning)能力的激发,而这一能力使用极少量高质量轨迹即可显著提升。
PC Agent-E:如何用极少量轨迹训练出强大的电脑智能体?
数据从哪来?人类提供原始操作轨迹
与以往依赖大规模人工标注或复杂自动化合成的方式不同,团队的方法只需 312 条真实的人类操作轨迹。这些轨迹由团队开发的工具 PC Tracker 收集而来,仅由两位作者花一天时间操作自己的电脑,就完成了原始轨迹数据的收集。每条轨迹包含任务描述、屏幕截图以及键盘鼠标操作,并确保了数据的正确性。
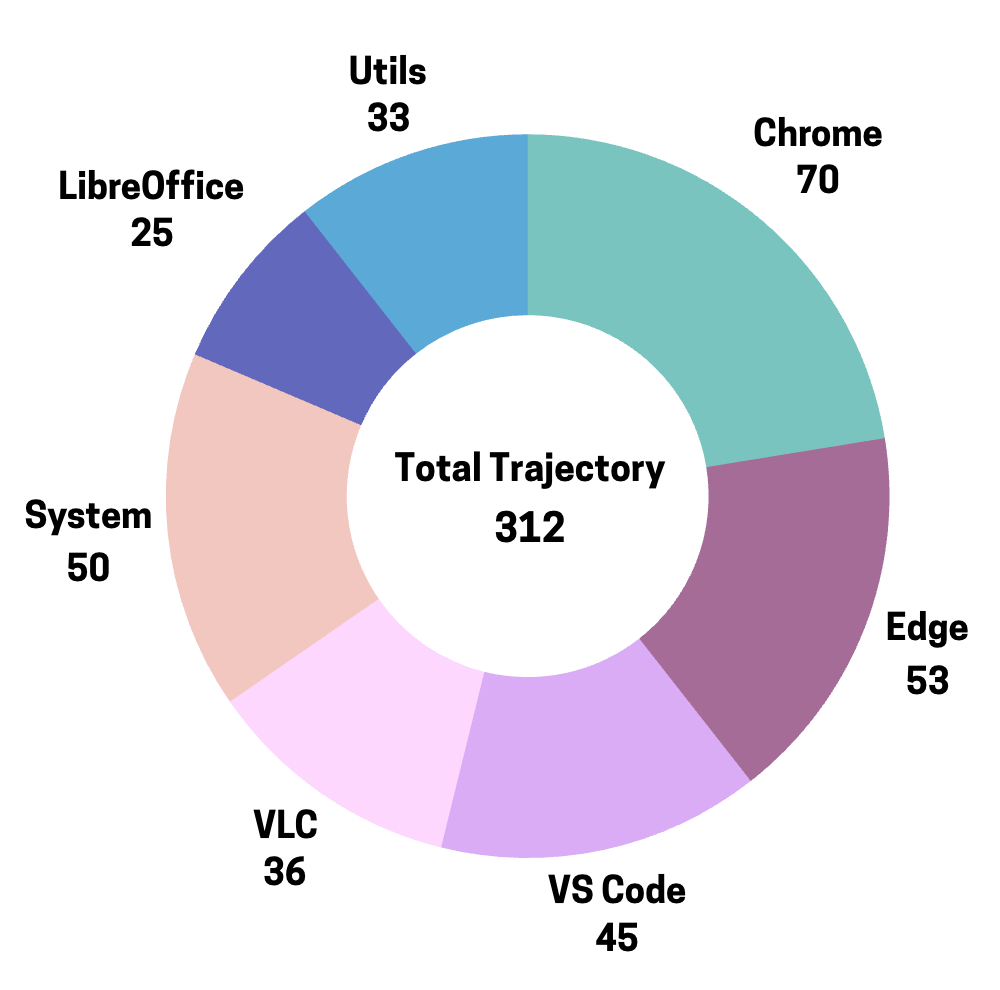
312 条轨迹在不同软件上的分布
思维链补全:让「动作」有「思考」的支撑
人类执行每一个动作,往往都有一定的理由或「思考过程」。但在收集的原始轨迹数据中,这部分「思维链」是缺失的。于是,团队对人类动作进行了「思维链补全」(Thought Completion),为每一个动作步骤添加了背后的思考逻辑(符合于 ReAct 范式)。此时的数据已足以用于智能体训练,但团队并未止步于此——接下来的关键一步,进一步大幅提升了轨迹质量。
轨迹增强:让 AI 帮你「脑洞大开」
接下来,团队提出了一个关键创新点:轨迹增强(Trajectory Boost),这正是使用极少轨迹让模型超越 Claude 3.7 Sonnet(thinking)的关键。
其核心观察为:每个电脑任务其实可以通过多种路径完成。也就是说,除了人类采取的动作以外,轨迹中的每一步其实都有多个「合理的动作决策」。为了捕捉这种轨迹内在的多样性,团队利用前沿模型 Claude 3.7 Sonnet,为轨迹的每一步合成更多的动作决策。团队注意到,轨迹中每一步记录的数据,作为「环境快照(environment snapshot)」,已足以为人类或智能体提供决策信息。于是,团队将这些快照提供给 Claude 3.7 Sonnet,采样多个包含思考过程的动作决策。这一过程极大丰富了轨迹数据的多样性。

思维链补全与轨迹增强
模型训练:少量数据也能训出强大模型
最终,团队在开源模型 Qwen2.5-VL-72B 的基础上进行训练,得到 PC Agent-E 智能体。作为一款原生智能体模型(native agent model),PC Agent-E 无需依赖复杂的工作流设计,即可实现端到端的任务执行。令人惊喜的是,在仅使用 312 条人工标注轨迹的情况下,模型性能便达到了训练前的 241%,展现出极高的样本效率。
团队在 WindowsAgentArena-V2 上进行评测——这是对原始 WindowsAgentArena 存在问题进行改进后的新版本。实验结果显示,PC Agent-E 的表现甚至超过了 Claude 3.7 Sonnet 的「extended thinking」模式,而用于数据合成的 Claude 3.7 Sonnet 并未启用这一模式。这标志着 PC Agent-E 成为当前 Windows 系统上开源电脑智能体的新一代 SOTA!与此同时,PC Agent-E 在 OSWorld 上也表现出不俗的跨平台泛化性能。
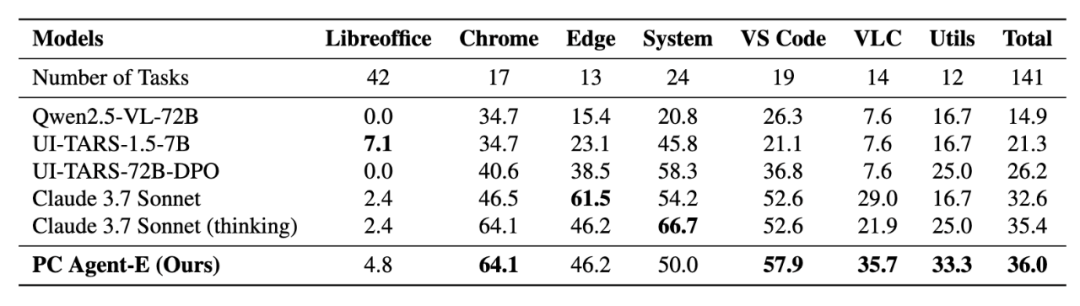
不同电脑智能体在 WindowsAgentArena-V2 上的评估结果
轨迹增强方法的有力验证
论文的关键创新之一——轨迹增强方法在人类轨迹的每一步补充了 9 个合成动作决策。为了进一步验证该方法的效果,团队调整训练时使用的合成动作数量,并观察其对模型性能的影响。
如图所示,随着合成动作数量的增加,模型性能显著提升,并展现出良好的拓展趋势。相比仅使用人类轨迹训练(性能提升仅 15%),PC Agent-E 在引入合成动作后实现了高达 141% 的性能飞跃,充分证明了轨迹增强方法对智能体能力突破的关键作用。
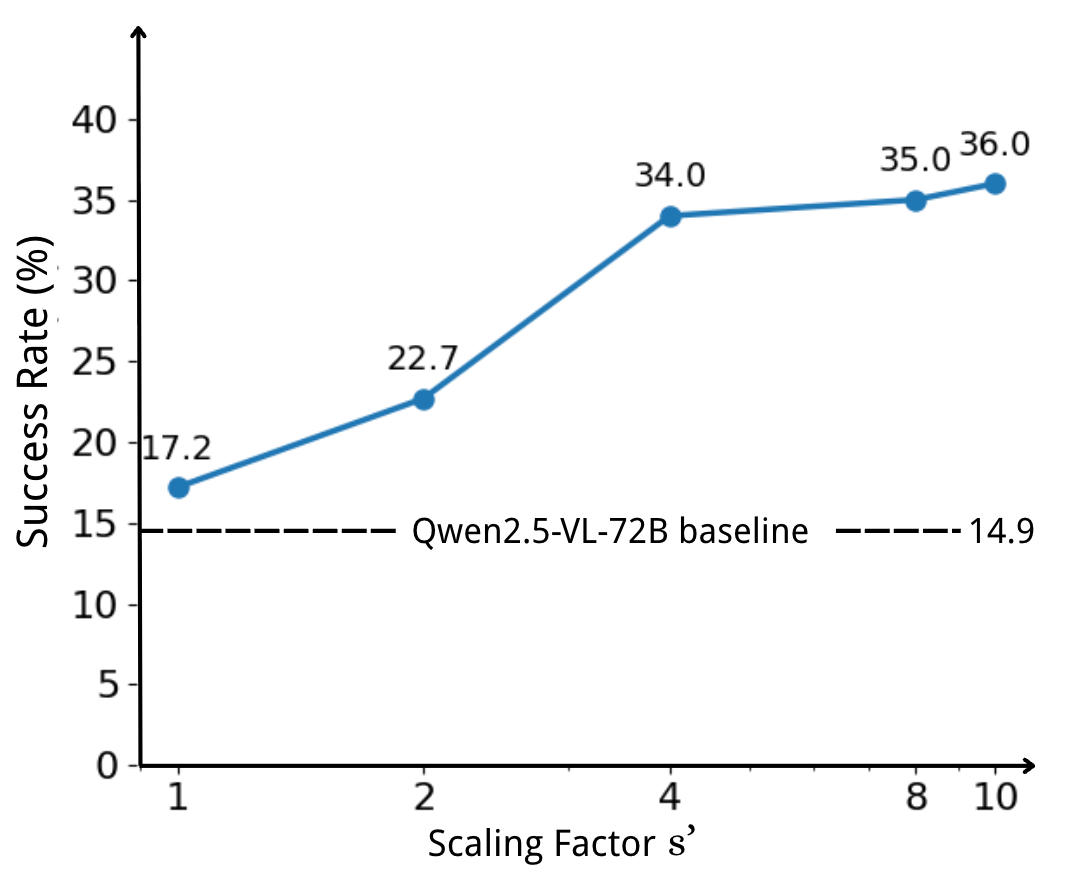
模型能力随训练数据中动作决策的扩展倍数的变化
结论与展望
实验结果有力证明了一个关键观点:少量高质量轨迹,就足以激发智能体强大的长程推理(long-horizon planning)能力。无需海量人类标注,就能训练出当前最优(SOTA)的电脑智能体。
目前,即使是最前沿的电脑智能体,其能力与人类相比仍有明显差距。在这种情况下,在预训练和监督微调阶段引入一定的人类认知,仍然是为后续强化学习打下坚实基础的必要步骤。
团队方法提供了一种新的思路:在人类标注轨迹注定有限的情况下,可以通过提高轨迹质量来实现高效的性能提升。这不仅降低了数据需求,也为未来构建更智能、更自主的数字代理铺平了道路。PC Agent-E 只是一个开始。通往真正能理解并自如操作数字世界的智能代理之路,仍在继续。
©
(文:机器之心)