
“ Vanna的核心思想是由大模型替代DBA人员编写SQL,能够直接根据自然语言进行数据分析 。”
在大模型应用中有一种技术叫做NL2SQL——自然语言生成SQL语句;在基于人工智能的数据分析场景中,数据库是必不可少的一个环节。但怎么处理数据库中的数据却有不同的思路,比如类似于传统数据分析,使用SQL读取数据库,然后交给大模型进行分析;
第二,使用pandas这种数据分析工具,让大模型调用pandas的函数执行获取结果;因为存在即合理,因此不同的技术方案适合不同的业务场景。
而今天我们就来介绍一下基于大模型的SQL语句生成项目——Vanna。
SQL语句生成智能体
Vanna项目是一个让用户输入自然语言,然后自动生成SQL语句进行数据分析的开源项目;其本质是使用RAG的技术,配合大模型进行SQL生成。
官网地址:https://vanna.ai/docs/
项目架构图如下:
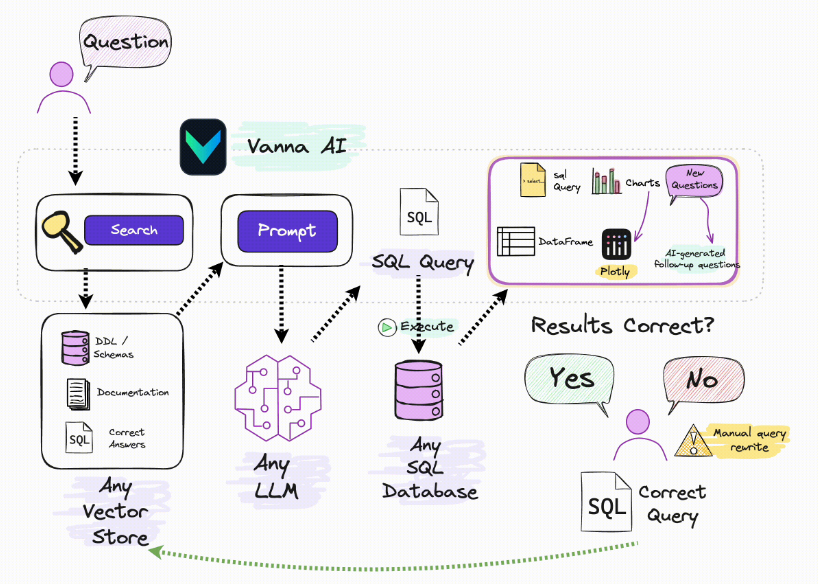
从架构图中可以看出,项目是根据用户的问题从向量数据库中进行相似度检索,然后再拼接成提示词,最后由大模型生成SQL查询语句交给数据库引擎执行。
从文档中可以看出,vanna项目的执行过程主要分为两步,第一步是train也就是训练,第二步是ask也就是用户提问;训练的过程,其实就是把数据库结构和说明文档保存到向量数据库中,然后用户提问时就可以根据用户的语义对向量数据进行相似度检索,获取到用户想要查询的库表结构。
然后再由大模型根据用户的需求和库表结构生成相对应的SQL语句进行执行。
如下图所示:

而且,vanna项目提供了专门的训练接口,让开发者可以基于自己的库表结果做训练。并且,可以选择对应的大模型,向量数据库和关系型数据库;而且,为了解决兼容性问题,还提供了基于pandas的数据结构分析接口。
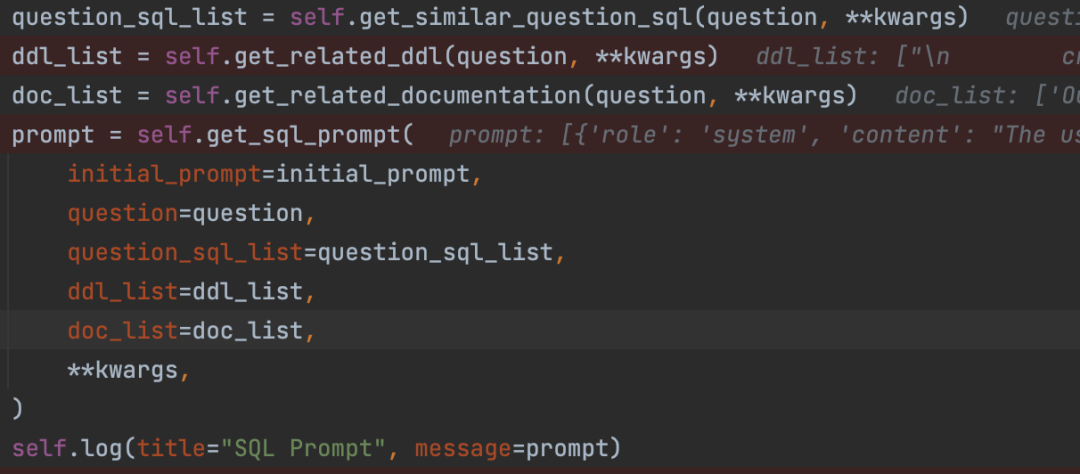
而从源码分析,vanna生成SQL语句是使用历史记录,数据库DDL语句和说明文档document一起拼接成Prompt提示词交由大模型自动分析生成查询语句。
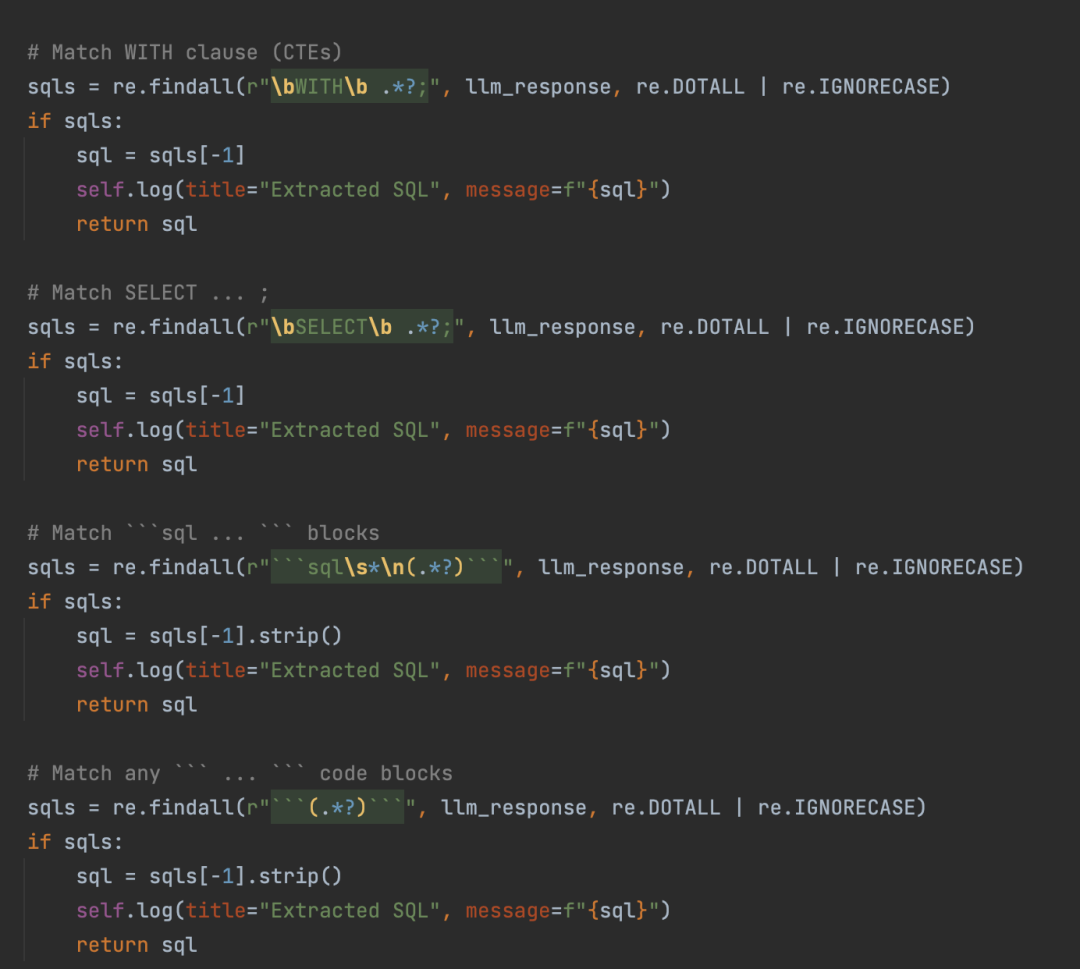
如下图所示:
当大模型分析生成SQL语句之后,再交由数据库引擎进行执行;并且为了防止生成的SQL语句有问题,这里还专门用正则表达式进行处理。
那么通过这种生成SQL执行的好处是什么?
这种基于SQL的数据分析方式,其原理只是把本来由人工编写SQL语句的过程交给了大模型;而数据处理的过程还是由数据库引擎来执行。这种方式对比使用pandas有什么好处?
使用pandas进行数据处理,需要先把数据部分或全部读取到内存中进行分析;虽然pandas也提供了分批读取数据的方式,但我们都知道在数据分析中有些场景是没办法进行分批读取的,比如说统计一个上千万的表结构;最好的方式就是直接执行统计SQL,毕竟分批读取无法直接获取一共有多少条数据。
当然,使用pandas进行数据统计也有其好处,在数据量不大或内存足够大的情况下;使用pandas进行数据分析,只需要在第一步去兼容不同的数据库即可,之后的数据分析过程可以通用;但使用生成SQL的方式,就需要根据不同的数据库引擎生成不同的SQL语句。
(文:AI探索时代)