

近期,当很多人还在纠结用什么 label 和 reward 训练大模型的时候,以及纠结用什么样的基准模型进行公平比较的时候,西湖大学 MAPLE 实验室另辟蹊径:既然 LLM 在复杂指令上表现不佳,需要引入单独的 SFT 或者 RL 过程,那为什么不让模型在推理时「临时学习」一下这个具体的问题呢?这个看似「离谱」的想法,竟然带来了惊人的效果提升。
试想一下,如果你参加考试时,可以在答题前花几秒钟「适应」一下这道具体的题目,你的表现会不会更好?
这正是西湖大学研究团队在最新论文中提出的核心思想。他们开发的 SLOT(Sample-specific Language Model Optimization at Test-time)方法,把每个输入 prompt 本身当作一份「迷你训练数据」,让模型在生成答案前先「学习」理解这个具体问题。
更令人惊讶的是,这个方法简单到离谱:
-
只需要优化一个轻量级参数向量 delta(仅修改最后一层特征)
-
只需要几步 (比如 3 步) 梯度下降
-
计算开销几乎可以忽略不计(仅增加 7.9% 推理时间)
-
完全即插即用,无需修改原模型

-
论文标题:SLOT: Sample-specific Language Model Optimization at Test-time
-
论文地址:https://arxiv.org/pdf/2505.12392
-
GitHub地址:https://github.com/maple-research-lab/SLOT
效果炸裂
多项基准测试刷新纪录
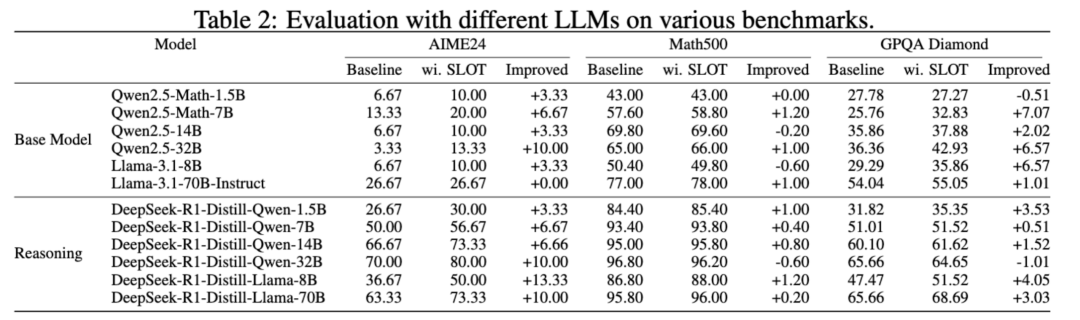
即便拿最有挑战性的高性能基线做比较对象,实验结果令人瞩目 (所有 log 都在开源 github 里):
-
Qwen2.5-7B 在 GSM8K 数学推理任务上准确率从 57.54% 飙升至 66.19%,提升 8.65 个百分点。
-
DeepSeek-R1-Distill-Llama-70B 在 GPQA Diamond 上达到 68.69%,创下 70B 级别开源模型新纪录
-
在高难度的 AIME 2024 数学竞赛题上,多个模型实现 10% 以上的提升
核心创新
把 Prompt 当作「测试时训练样本」
传统的 LLM 在面对复杂或特殊格式的指令时经常「翻车」,它可能会忽略格式要求或给出错误答案。
SLOT 的解决方案优雅而简单:针对单独一个问题,直接在最后一层特征上加一个 delta 向量,并在问题 prompt 本身上最小化交叉熵损失即可。
由于仅仅需要在最后一层上优化一个加性的 delta 参数向量,每个问题只需要经过一次网络推理。通过把输入给最后一层的中间结果进行缓存,优化 delta 的过程几乎不需要增加计算开销。
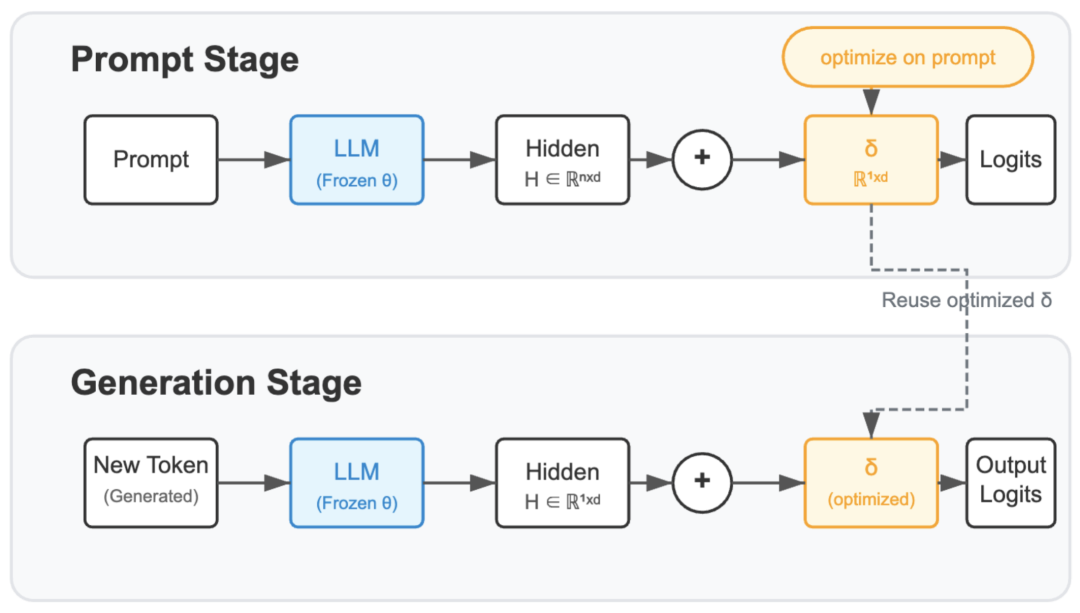
由于方法十分简单,任何伪代码公式都多余,这里给出如何把 SLOT 应用于你的工作的 transformers 版本代码(vLLM 版本也已开源)。
以 modeling_qwen.py 里 Qwen2ForCausalLM 模型为例,研究团队在 forward 函数里获得 hidden_states 之后插入这段代码:首先初始化一个全 0 的 delta 向量,加在 last hidden states 上;然后用当前的 prompt 作为训练数据,delta 作为可学习参数,以交叉熵损失优化,得到 sample-specific 的 delta 参数;之后即可用优化好的 delta 生成后续 token。

为什么如此有效?
深入分析揭示秘密
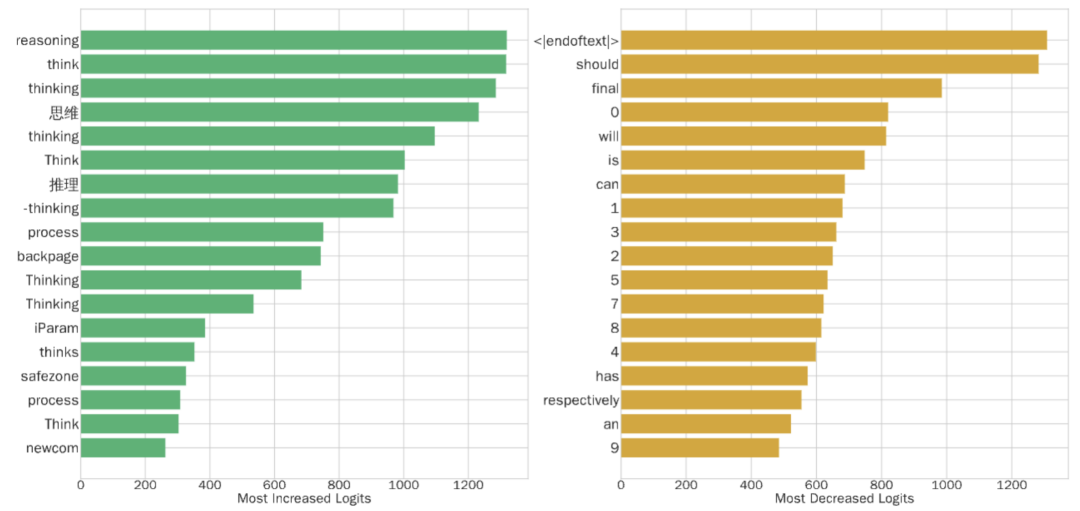
研究团队通过分析发现,SLOT 优化后的 delta 会显著调整输出词汇的概率分布:
-
增强的词汇:reasoning、think、thinking 等推理相关词汇
-
抑制的词汇:数字符号(0-9)、模态动词(should、will)、结束符 </s>
这意味着 SLOT 在鼓励模型「深思熟虑」,避免过早结束推理或陷入表面的模式匹配。
亮点在于:不同于 SFT 或者 RL 的微调算法,该方法无需:
-
修改模型架构
-
额外的训练数据
-
复杂的采样策略
-
昂贵的计算资源
广泛适用
从 1.5B 到 70B,从基础模型到推理专家
SLOT 在各种规模和类型的模型上都展现出稳定的提升:
-
Qwen 系列:1.5B 到 32B 均有提升。
-
Llama 系列:包括 Llama-3.1。
-
DeepSeek-R1 系列:即使是已经专门优化过推理能力的模型,仍能获得显著提升。
特别值得注意的是,在最具挑战性的任务上,SLOT 的提升最为明显:
-
C-Eval Hard 子集:+8.55%
-
AIME 2024:部分模型提升超过 13%
-
GPQA Diamond: 由 65.66 提升到 68.69 (开源 sota 级别)
结语
在大模型时代,当所有人都在追求「更大、更强」时,SLOT 用一个简单得「离谱」的想法证明:有时候,让模型在回答前先「理解」一下问题,就能带来惊人的效果。

©
(文:机器之心)