
在“整体流程”一文中,我们已经讨论了 vllm v1 在 offline batching / online serving 这两种场景下的整体运作流程,以offline batching为例:
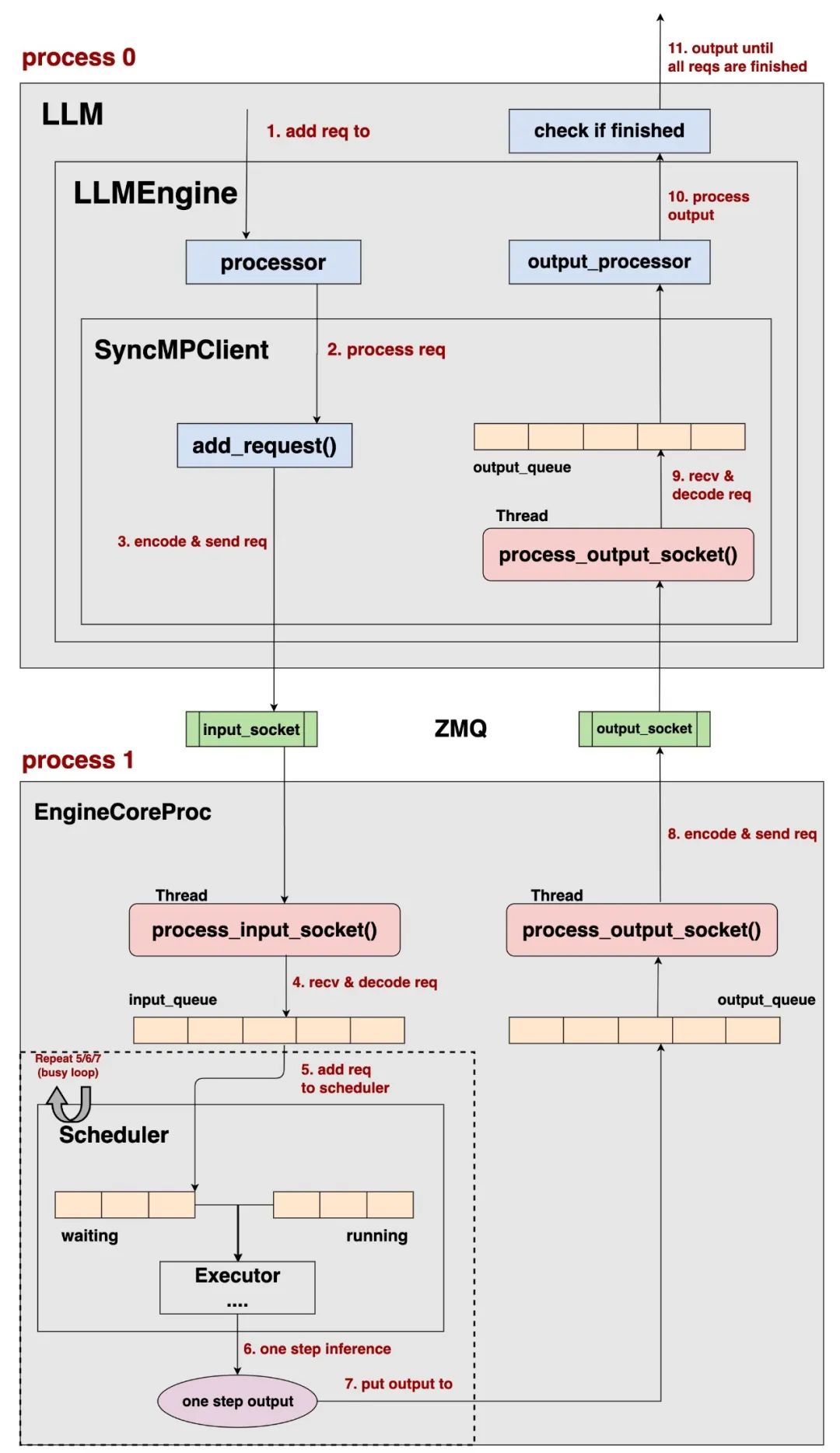
整体上来看:
-
vllm v1将 请求的pre-process和输出结果的post-process与实际的推理过程拆分在2个不同的进程中(process0, process1)。 -
Client负责 请求的pre-process和输出结果的post-process,EngineCore负责实际的推理过程,这两个进程间使用ZMQ来通信数据。 -
对于offline batching和online serving来说,它们会选取不同类型的Client进行运作,但是它们的EngineCore部分运作基本是一致的,如上图所示。 -
通过这样的进程拆分,在更好实现cpu和gpu运作的overlap的同时,也将各种模型复杂的前置和后置处理模块化,统一交给processor和output_processor进行管理。
(如果对上面的描述存在疑问,可回到“整体流程”篇中进行复习阅读)
本文我们来看上图中的Scheduler部分。而调度器本身涉及到的两个细节:kv cache块的分配(由KVCacheManager控制)和 prefix caching 我们将放在后面的文章中进行解读。
一、调度-推理的整体流程
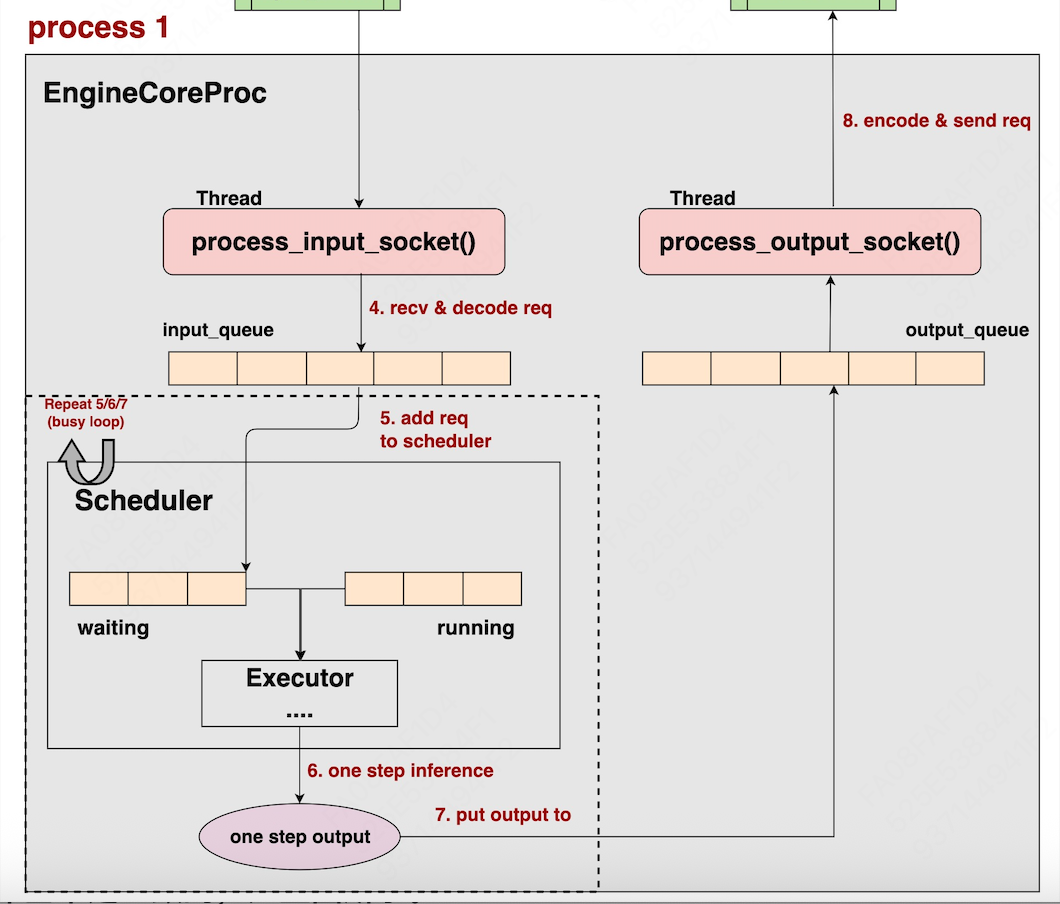
如图所示,EngineCoreProc进程内,会启动run_busy_loop()这个无限循环函数,“无限循环”即While True,即只要用户没有显式终止进程,那么这个函数将会一直重复做下面的事情:
(1)将请求添加进Scheduler中:持续监听、处理input_queue中存放的输入(EngineCoreRequest),并将输入add进Scheduler的waiting队列中。
(2)Scheduler执行单步调度策略:决定本次调度中要送哪些请求去做推理,被选中的请求们将会被包装成SchedulerOutputs的形式。
(3)实际执行单步推理:SchedulerOutputs将被传递给Executor,Executor->Workers->ModelRunners架构将实际执行推理,输出结果形式为ModelRunnerOutputs
(4)Scheduler对单步推理结果做处理:ModelRunnerOutputs将再次返回给Scheduler,由其做一些更新处理操作,生成最终的单步输出结果,形式为EngineCoreOutputs
(5)推理结果装入output_queue队列:EngineCoreOutputs被装入output_queue队列中,后续将会被返回给Client进程
(注意,在上图中,这个Executor其实应该画在Scheduler的外面更合理,而不是应该呈包含关系,不过不影响整体的理解,我偷个懒暂时不改动图片了。)
接下来,我们就围绕着上面的内容,做细节展开。
二、将请求添加进Scheduler中
2.1 run_busy_loop
我们先来看之前提到的run_busy_loop()实现,它是整个调度的入口。
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/engine/core.py#L350
def run_busy_loop(self):
"""Core busy loop of the EngineCore."""
# =================================================================================
# - pp=1,batch_queue = None,step_fn = self.step
# - pp>1, batch_queue的长度为pp的stage数,step_fn = self.step_with_batch_queue
# (本文着重分析的是pp=1,但也会对pp>1做部分说明)
# =================================================================================
step_fn = (self.step
if self.batch_queue isNoneelse self.step_with_batch_queue)
# =================================================================================
# Loop until process is sent a SIGINT or SIGTERM
# 持续监听和处理input_queue中的输入(EngineCoreRequest),除非用户显式终止程序
# =================================================================================
whileTrue:
# =================================================================================
# 1) Poll the input queue until there is work to do.
# 当Scheduler中没有请求的时候
# =================================================================================
whilenot self.scheduler.has_requests():
logger.debug("EngineCore busy loop waiting.")
# =================================================================================
# 从input_queue中获取request数据(阻塞式取出)
# 阻塞取出:当input_queue为空,且不设置timeout的情况下,会持续等待直到可以从
# input_queue中取到请求
# =================================================================================
req = self.input_queue.get()
# =================================================================================
# 处理请求,具体包括:
# 1、将请求包装成Request形式(EngineCoreRequest -> Request)
# 2、将请求添加进Scheduler的waiting队列中
# =================================================================================
self._handle_client_request(*req)
# =================================================================================
# 2) Handle any new client requests.
# 当scheduler中有request,且input_queue也有request时
# =================================================================================
whilenot self.input_queue.empty():
# =================================================================================
# 从input_queue中获取request数据(非阻塞式取出)。
# 非阻塞式取出:若input_queue为空,不会暂停线程,而是会直接抛出 queue.Empty 异常
# (所以要通过not empty()确保队列非空)
# =================================================================================
req = self.input_queue.get_nowait()
# =================================================================================
# 处理请求
# =================================================================================
self._handle_client_request(*req)
# =================================================================================
# 3) Step the engine core.
# EngineCore执行单步推理,返回单步推理的结果,包括:
# - Scheduler确定在本步调度中,哪些请求要被送去推理(SchedulerOutputs)
# - Executor->Workers->ModelRunners架构执行实际推理(SchedulerOutputs -> ModelRunnerOutputs)
# - Scheduler处理推理结果:ModelRunnerOutputs-> EngineCoreOutputs
# =================================================================================
outputs = step_fn()
# =================================================================================
# 4) Put EngineCoreOutputs into the output queue.
# 将EngineCoreOutputs装入output_queue中
# =================================================================================
if outputs isnotNone:
self.output_queue.put_nowait(outputs)
详细的内容都在注释中,这里额外提一些点。
-
当Scheduler中没有请求的时候,说明此时整个Scheduler都在空转(例如先前的数据已经做完了推理,而此刻又没有新来的请求)。所以此时才使用阻塞式的取数方式,要求至少可以从input_queue中等到一条新请求,这样Scheduler才能继续干活。
-
当Scheduler中有请求时,说明Scheduler是有活干的,那么如果input_queue中有新请求,那就去处理它们,把它们add进Scheduler的waiting队列中;如果没有也没关系,所以采用的是非阻塞式取数。
-
满足以下任意情况,说明Scheduler中有请求:
-
(a) 当前scheduler的waiting或running队列不为空 -
(b) 当前scheduler中存在已经推理完毕的请求(finished_req_ids这个集合不为空)
这里详细看(b):
-
当一轮推理结束后,我们会得到 ModelRunnerOutputs,Scheduler需要对其处理,转为EngineCoreOutputs -
在处理的过程中,Scheduler会检查哪些请求已经完成推理,将其add进finished_req_ids中,并释放掉这些请求相关的资源(kv cache block等) -
等到在下一轮调度结束后,Scheduler会强制重置finished_req_ids为空set -
而在任意时刻,只要检测到finished_req_ids不为空,就认为调度器中还有请求
2.2 step_fn
由2.1中代码第9行可知,vllm中提供了2种step_fn函数:
# =================================================================================
# - pp=1,batch_queue = None,step_fn = self.step
# - pp>1, batch_queue的长度为pp的stage数,step_fn = self.step_with_batch_queue
# =================================================================================
step_fn = (self.step
if self.batch_queue is None else self.step_with_batch_queue)
整体来说,step_fn函数主要做了3件事情:
-
调度器单步调度 -
单步推理 -
调度器对推理结果做一些后处理
我们先来看较为简单的step_fn = self.step场景(这3件事串行执行);再来看更为复杂一些的step_fn = self.step_with_batch_queue(这3件事可以并行执行)。在后面细节的讲解中,你会更深入感受到这两者间的区别以及为什么要这么做。
(1)普通step:self.step
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/engine/core.py#L184
当我们不使用pp做推理时(pp=1),vllm选择的是self.step,它的具体代码如下,这里3个步骤是串行执行的,不难理解:
def step(self) -> EngineCoreOutputs:
"""Schedule, execute, and make output."""
# 如果调度器中已经没有请求。
ifnot self.scheduler.has_requests():
# 那么就返回一个空的输出结果
return EngineCoreOutputs(
outputs=[],
scheduler_stats=self.scheduler.make_stats(),
)
# 如果调度器中还有请求。
# ============================================================
# 1. 单步调度:确定要送哪些请求去做推理(SchedulerOutputs)
# ============================================================
scheduler_output = self.scheduler.schedule()
# ============================================================
# 2. 执行单步推理(SchedulerOutputs -> ModelRunnerOutputs)
# ============================================================
output = self.model_executor.execute_model(scheduler_output)
# ============================================================
# 3. 处理单步推理结果(ModelRunnerOutputs -> EngineCoreOutputs)
# ============================================================
engine_core_outputs = self.scheduler.update_from_output(
scheduler_output, output) # type: ignore
(2)pp下的step:self.step_with_batch_queue
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/engine/core.py#L201
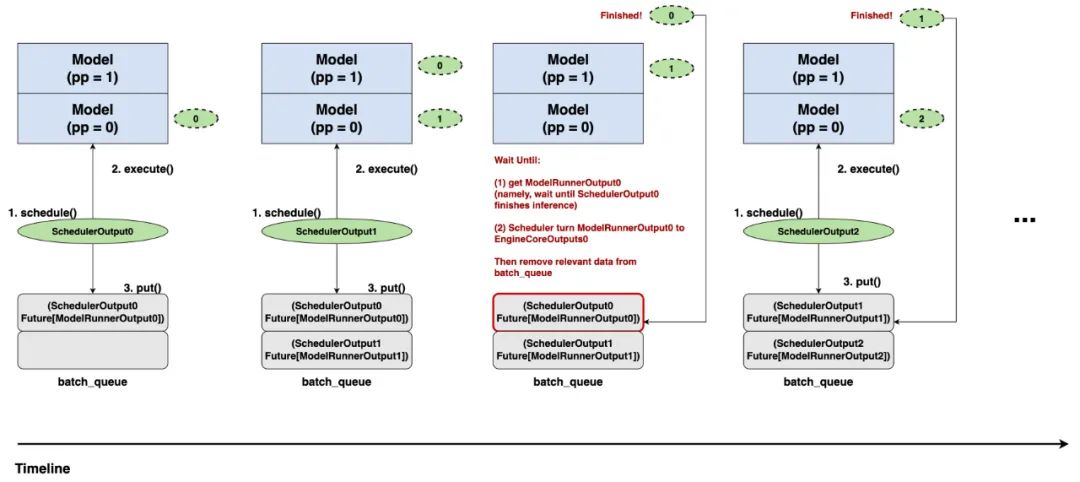
假设pp = 2,我们配合上图来看下self.step_with_batch_queue的整体流程:
-
由于pp=2,因此这里我们初始化一个空间大小也为2的batch_queue。
-
batch_queue中的每个元素的形式如
(SchedulerOutput, Future[ModelRunnerOutput]),其中,Future来自from concurrent.futures import Future,它可以用来实现“后台异步执行的机制”,也就是说,你不需要原地等待整个推理过程执行完毕,并把真正的ModelRunnerOutput返回给你,你可以把推理过程挂在后台执行,然后去做别的事情。等到某一时刻,你必须要取回真正的ModelRunnerOutput时,再通过Future.result()的方法阻塞式取回(阻塞式 = 原地等待,直到推理执行完毕,拿到结果)。 -
介绍完了batch_queue,现在我们真正来看调度过程。
-
Time0:
-
调度器执行单步调度,产出SchedulerOutput0 -
SchedulerOutput0被下发给Executor->Worker->ModelRunner架构做实际推理 -
batch_queue中记录相关数据,此时实际推理的过程挂在后台执行 -
Time1:
-
检查batch_queue是否已满,发现未满,那么继续做调度 -
重复Time0的3个步骤 -
此时,实现了调度和推理overlap的过程 -
Time2:
-
检查batch_queue是否已满,发现已满,那么意味着SchedulerOutput0可能已经要执行完毕了 -
此时不再做新调度,使用`Future.result()“,原地等待ModelOutput0的结果。该结果出来后,再给调度器做后处理(ModelOutput0 -> EngineCoreOutputs0) -
Time3:
-
检查batch_queue是否已经满,发现未满,那么继续执行新的调度,以此类推。
由此可知,我们之所以在pp下,要实现“调度-推理”的overlap,是因为:当一波数据从pp=0上推理完毕,进入pp=1时,pp=0所在的这块卡就空转了,所以需要我们及时调度新一波数据来填补它,而在pp中,一般我们会尽量均匀分割模型的layers,让每块卡上的计算速度都差不多,这也是我们为什么选择让batch_queue大小等于pp,以及为什么要在batch_queue装满的时候原地等待最早的那个output。
详细的代码大家可以自行阅读。最后,再提2个注意点:
-
当前vllm中,目前只有
RayDistributedExecutor才支持pp,而我们整个系列都是以MultiProcExecutor为例的,所以在本文后面的讲解中,选用的都是self.step而不是self.step_with_batch_queue -
本系列的讲解使用的是vllm 0.8.2版本的代码,在这一版中,EngineCore下默认batch_queue长度为1,也就是不会选用到
self.step_with_batch_queue(V1的很多feature都是逐步开发中的)。而在最新的版本中,batch_queue的长度已经和pp配置一样了。
三、Scheduler的单步调度策略
我曾经写过vllm V0的Scheduler策略(版本为0.4),在V0当时的策略中,每次调度步骤要么全是做prefill的请求,要么全是做decode的请求,除此以外,调度器中维护着waiting,running,swapped三个队列,整体来说调度策略比较复杂(详情参见这篇文章)。
在V1中,调度策略简化许多,最主要的就是允许单次调度步骤中同时调度prefill和decode请求,同时调度器中只维护waiting和running队列。我们从vllm官方blog中来看下V1的整体调度思想(https://blog.vllm.ai/2025/01/27/v1-alpha-release.html)
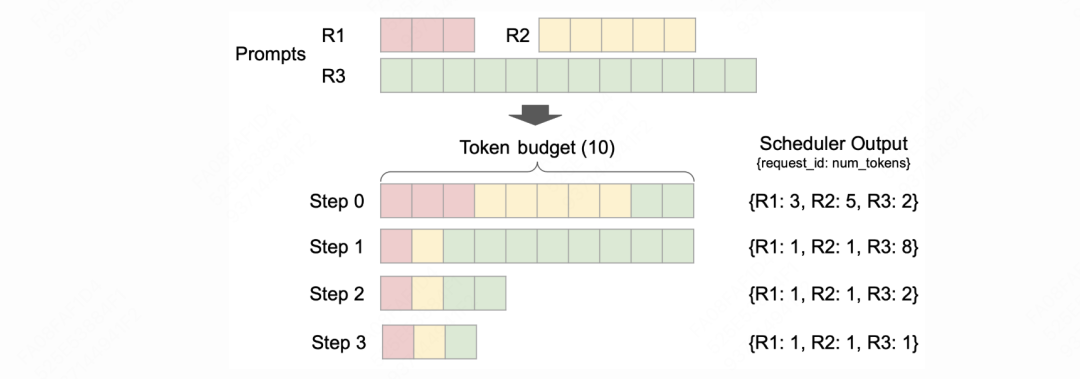
如图所示:
-
首先,vllm会对单次调度步骤设置一个
token_budget,它用来决定每次调度中最多允许“计算”多少个token。这个token_budget可以由用户通过scheduler_config.max_num_batched_tokens进行配置。在我们的图例中token_budget = 10 -
假设此时waiting队列中有3个R1,R2,R3三个请求(prompts),长度分别为3,5,12。请求已经按照到来的先后顺序排列好了。Vllm v1依然采用的是FCFS原则(First come First serve),按先来后到的顺序处理请求。
-
step0:
-
调度器开始执行调度。 根据某种策略(后文会细说),调度器决定将【R1的3个token】,【R2的5个token】都算入本次调度步骤中。此时token_budget = 10 – 3 – 5 = 2。 -
R3有12个token需要计算,但本轮调度的token_budget只剩2个,所以只取R3的2个token加入本次调度中 -
R1,R2和R3都会从waiting队列转移到running队列上 -
step1:
-
调度器开始执行新一轮调度。此时R1和R2都做完了prefill,进入decode阶段,它们待计算的token都只有1个。R3仍在prefill阶段,并根据token_budget再送入8个token进入本轮调度 -
以此类推,可以发现,直到step3为止,最长的R3才做完了prefill,进入decode阶段。
读完上面这个流程,你的心中应该还有一些问题,让我来猜猜你想问什么。
(1)问题1:token_budget的定义是“每次调度步骤中最多允许计算的token数量”,那这里“计算”的定义是什么?
在vllm调度器相关的代码中,你会发现很多变量名里都带有computed,比如请求数据的属性中就有request.num_computed_tokens,表示一个请求被计算过的token数量。在我的理解里,计算 = 计算kv值并存成cache,举例来说:
-
对于正在做prefill的请求,它正在计算的token数量 = 本轮调度中它被选中的prompt长度。例如在step0中,R1,R2,R3需要被计算的token数量就是3,5,2。这些token不存在已经被算过且存下来的KV值。
-
对于正在做decode的请求,它正在计算的token数量 = 1。例如在step1中,R1刚做完prefill,产出了第一个output_token,这个output_token将在step1的调度中被计算kv值,cache下来,然后产生next output_token。
-
由此可知,
request.num_computed_tokens指的就是这条请求已经被计算过KV cache的那些token数量。
(2)问题2:在step0的调度中,我们发现R1和R2完整的prompt都被选中了,只有对R3的prompt做了切割。那么为什么不能是对R1和R2也做一些切割呢?这里采用的调度策略具体是什么呢?
在vllm中,整个调度器策略有一个核心思想:
(a) 对于一个请求,我们会记录len(prompt_token_ids) + len(output_token_ids) + len(spec_token_ids):
-
prompt_token_ids:表示这个请求的prompt -
output_token_ids:表示这个请求当前已经生成的response。举例来说,刚做完prefill的请求,会产生第一个output_token装入output_token_ids。后续的decode过程中,每产出一个token,都会装入这里,这个列表是动态变化的。 -
spec_token_ids:推测解码策略相关的token_ids,不是本文讲述的重点,我们可以将其长度视为0。 -
综上,你可以将(a)的结果理解成,当前这个请求一共有多少token需要做计算
(b) 对于一个请求,我们会记录request.num_computed_tokens:
-
如问题1中所说,它表示这条请求已经被计算过kv cache的token数量。举例来说,如果这条请求刚做完prefill,那么这个值就等于prompt长度,以此类推。 -
综上,你可以将(b)的结果理解成,当前这个请求一共有多少token已经做了计算
(c) 对于一个请求,我们会计算num_new_tokens = (a) - (b),它即表示当前这个请求有多少token还没做计算,例如:
-
对于正准备做prefill的请求,例如step0中的R1: -
(a) = prompt + output = 3 + 0 = 3 -
(b) = 0 -
num_new_tokens = (a) – (b) = 3 – 0 = 3,即此时R1还有3个token需要做计算 -
对于刚做完prefill的请求,例如step1中的R1: -
(a) = prompt + output = 3 + 1 = 4 -
(b) = prompt = 3 -
num_new_tokens = (a) – (b) = 4 – 3= 1,即此时R1还有1个token需要做计算,这就是R1 prefill完成后产出的那个token -
对于prefill被分批调度的请求,例如step1中的R3: -
(a) = prompt + output = 12 + 0 = 12,只要R3没有做完prefill,它就永远不会有output,而prompt是恒定的 -
(b) = 2,因为step0中R3有2个token已经被计算过 -
num_new_tokens = (a) – (b) = 12 – 2 = 10
对于一条请求,vllm会尽可能让它的num_new_tokens全部加入本次调度中,因为这就是这条请求目前需要被“计算”的全部tokens。但是受到token_budget的影响,最终会让num_new_tokens = min(num_new_tokens, token_budget)。在每次调度中,尽量让一个请求需要被计算的token全部都能被调度上,即让(b)去尽可能追上(a),这就是单步调度策略的核心。而也只有对num_new_tokens,也就是还没有计算过kv的tokens,我们才有必要去考虑是否为它们安排blocks,以及怎么安排blocks。
在对整体调度策略有了感知后,我们来看更细节的部分,总体来说,vllm v1采用先从running队列中调度,再从waiting队列中调度的规则。所以我们分开来看,整个调度的入口代码在下面链接中。本节所说的内容,即是对这段代码开头的注释进行扩展讲解。
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/core/sched/scheduler.py#L107
3.2 running队列的调度流程
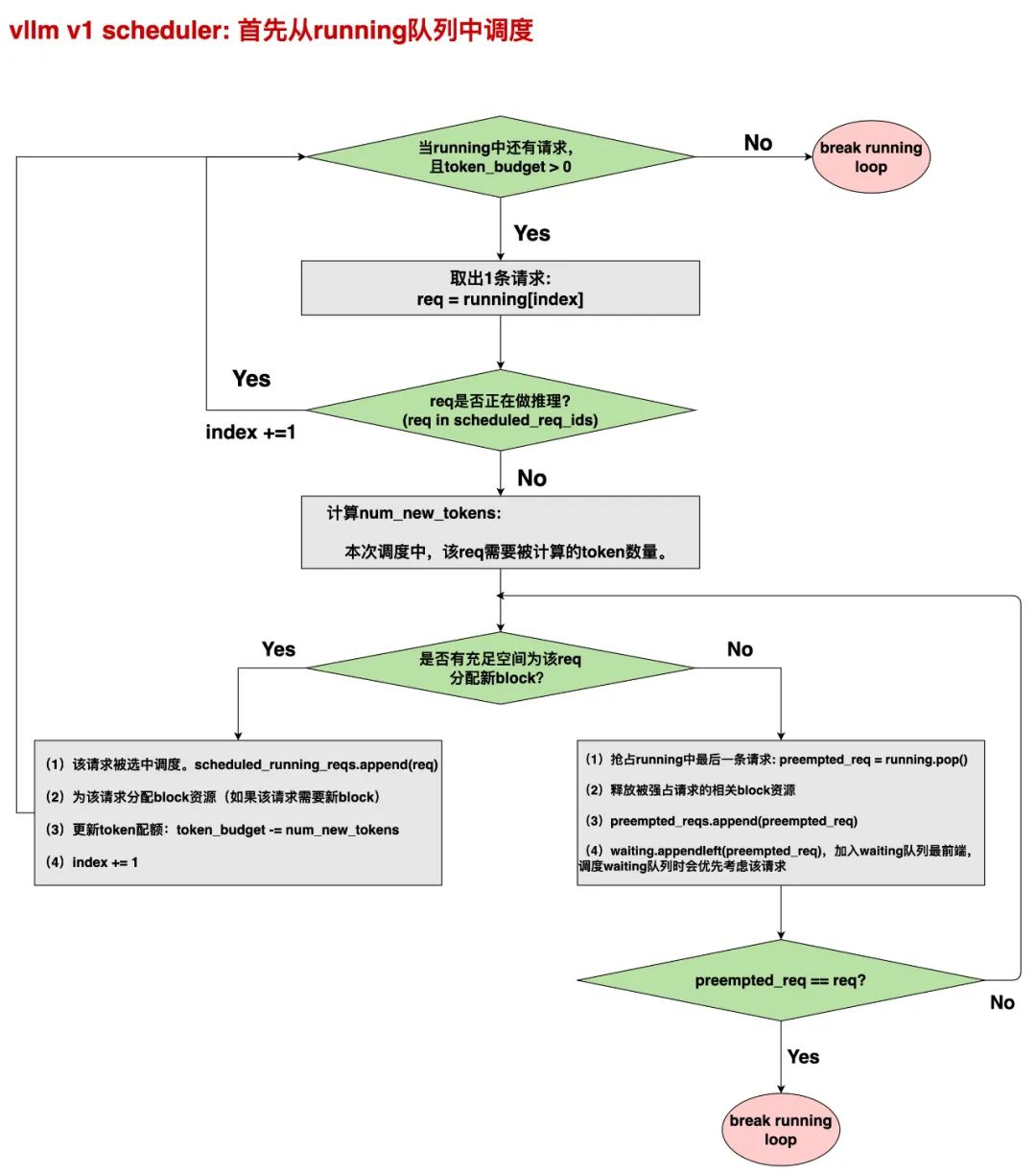
我们对这张图做一些说明。
(1)首先,在本次调度步骤开始前,会初始化4个重要的空列表,其数据形式如List[Request]:
-
scheduled_new_reqs:用于装从waiting队列中调度的新鲜请求。新鲜指那些不是从抢占状态中恢复的请求。 -
scheduled_resumed_reqs:用于装从waiting队列中调度的抢占请求,也即从抢占状态恢复的请求 -
scheduled_running_reqs:用于装从running队列中调度的请求 -
preempted_reqs:用于装本次调度中刚被设置为抢占状态的请求(参见上图) -
最终本次调度的SchedulerOutput将由前3者共同组成
(2)index(在代码里叫req_index,每次调度步骤开始被设置为0),用于记录本次被调度的某条请求,在本次被调度的所有请求中的全局序号。
(3)图中,当我们从running队列中取出一条请求,首先要判断它是否正在做推理(req in scheduled_req_ids),这是什么意思呢?
-
正如2.2(2)中所说,某些情况下,我们是可以实现“请求-推理”的overlap的。2.2(2)中展示了pp情况下的overlap,另外当我们用online serving(AyncLLM)时,也可以实现这种overlap。 -
scheduled_req_ids用于记录整个Scheduler中,已经被调度,但是还没有做完“推理”和“调度器后处理”的请求。一旦一个请求完成了“调度器后处理”的部分,它将会被从scheduled_req_ids移除。 -
所以,如果running队列中有一条请求在scheduled_req_ids,意味着它在之前的调度步骤中被调度过,且还没有完成整个推理过程,所以本次调度我们不会考虑它,即直接跳过。
(4)对于running队列中的一条请求,我们会计算它本次调度中需要被计算的tokens数量(num_new_tokens = min (num_new_tokens, token_budget),这一部分的详细解释可以看3.1节。我们将根据num_new_tokens计算这个请求在本次调度中是否需要新的blocks,以及当前是否有充足空间为它分配新的blocks。
(5)如果当前没有充足空间,则会从running队列的末端开始持续强占请求,释放相关资源,为当前请求留出空间(从末端强占的原因是遵从FCFS策略)。如果最终轮到这个请求本身被强占了,说明无论如何也无法为这条请求分配blocks空间了。则抢占完这条请求本身之后,我们将退出整个running队列的调度(图中红色的break loop即表示这个意思。)
其余的内容和更多细节,大家可以配合流程图看代码。而关于“如何计算是否有充足的空间分配blocks”这部分,我们留在后面对KVCacheManager的部分详细说明。如果你对上述“抢占”之类的概念不了解,可以看我写的关于vllm V0系列的文章。
3.3 waiting队列的调度流程
当我们结束running队列的调度,且不存在被新转为抢占状态的请求后,就可以进入waiting队列的调度了,基本流程和running队列也差不多,只不过waiting队列不存在抢占请求的情况,以及waiting队列在计算num_new_tokens和需要多少blocks时,会考虑prefix caching的情况,这点也留在后面的系列详细说明。
那这里就把waiting队列的调度,以及Scheduler的后处理过程(self.scheduler.update_from_output),当成作业留给读者吧~
最后,任何源码解读都替代不了自己亲自阅读一遍代码。
(文:GiantPandaCV)