
AI 学会了自我打分和学习,然后实现自我提升!

Anthropic的研究人员找到了一种让语言模型自我微调的方法——模型通过评估自己的答案来提升能力,彻底摆脱了人类标注的瓶颈。

这项名为Internal Coherence Maximization(ICM)的技术让预训练模型能够生成并信任自己的标签。在数学、事实检验和对话质量等任务上,它的表现与黄金标准训练相当,甚至超越了人类标注。
最令人震撼的是,用这种自我微调方法训练的Claude 3.5 Haiku助手,在对比测试中60%胜率击败人类监督版本。
核心概念:挖掘内在知识
预训练语言模型已经储存了丰富的真理、正确性和偏好概念。ICM要做的就是在没有外部帮助的情况下激发这些概念。

ICM定义了一个评分系统,结合了两个关键要素:
相互可预测性:模型预测每个标签时,会参考其他所有已标记的例子。如果所有标签都指向同一个底层概念,预测概率就会很高。
逻辑一致性:防止出现明显矛盾,比如「A胜过B」和「B胜过A」不能同时为真。即使是「不同数值答案不能都正确」这样简单的规则,也足以阻止退化解。
工作原理:自我监督的搜索过程
由于穷举搜索不可行,ICM采用了巧妙的策略:

上图展示了ICM如何衡量一批标签是否协调一致。
三个声明已经有了临时的真假标签。模型每次隐藏一个标签,从其余两个推测它,并记录猜对的对数似然。将这三个数字相加得到一个连贯性分数——总和越高,标签越符合模型自己的一致性感知。
下图展示了改进这些标签的搜索循环。系统从一个有临时标签的小型算术数据集开始,采样一个新陈述,创造几个符合基本算术逻辑的替代标签,并用相同的连贯性指标为每个候选项打分。

算法从随机选择少量未标记例子开始,分配粗略标签,然后快速修复任何逻辑冲突。接着进入循环:
-
逐步降低「温度」参数(早期鼓励探索,后期趋于谨慎) -
选择一个未标记项目,让模型根据已有标签预测最合理的标签 -
添加临时标签并修复逻辑冲突 -
计算连贯性分数的变化 -
如果分数提升就保留,否则以概率决定是否保留
修复不一致:关键的清理步骤

ConsistencyFix算法扫描数据集中的冲突对,比如一个声明说某陈述为真,另一个说为假。它列出所有可能的一致性组合,询问模型哪个选项能得到最佳整体连贯性分数。如果新组合提升了分数,就保留更改。
这个过程确保每个新标签都能触发对旧错误的修复,而不是被简单丢弃。
实验结果:全面超越
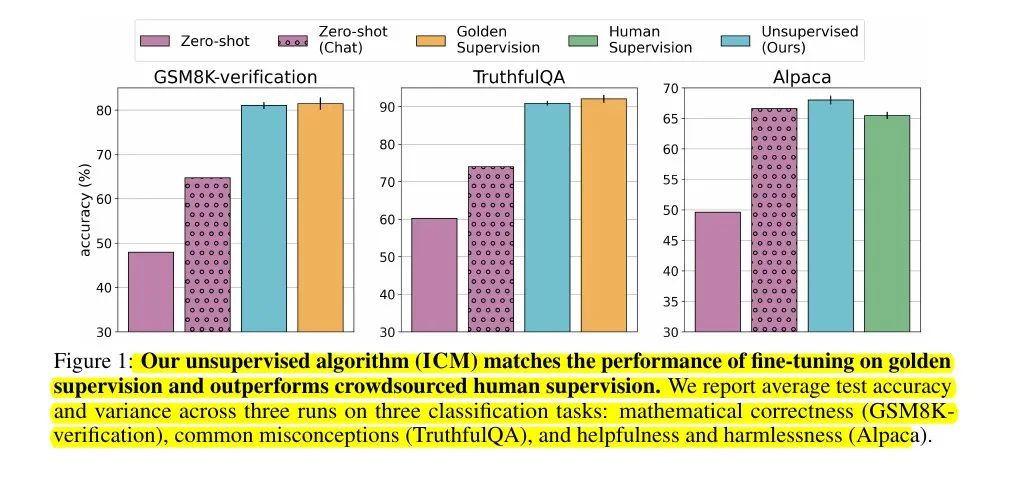
在Llama 3.1模型上,ICM在TruthfulQA和GSM8K验证上匹配了黄金标签微调,在Alpaca上击败了众包监督。
在作者性别预测这个模型超人类的任务上,ICM达到80%准确率,而人类只有60%。
标注成本适中,每个数据点只需要2-4次前向传播。
前沿模型应用

团队在40万个提示对上仅使用ICM标签训练了Claude 3.5 Haiku的奖励模型,在Rewardbench上得分75%,超过人类标注基线的72.2%。

左图比较了两个奖励模型。在Alpaca数据上,无监督模型达到约68%准确率,比人类标注版本高10个百分点。在更大的生产数据集上,它仍领先几个百分点。
右图追踪了用每个奖励模型训练的聊天机器人在直接对决中的胜率。由无监督奖励模型指导的机器人赢得约60%的比赛。
局限性

当基础模型中不存在所需概念时,ICM会失败。
一个仅基于「太阳」一词的诗歌质量任务退化为随机猜测。
由于评分需要将许多例子放入上下文,具有超长输入的任务仍然无法触及。
启示

内部连贯性是网络内部已经存在的强大监督信号,简单的逻辑检查让搜索保持在正轨上。
当目标技能是潜在的,模型可以在没有一个人类标签的情况下自我完善。
社区讨论
Jiahao Lu(@jiahao_lu_)提出了关键问题:
这是否意味着激发出的能力严格受限于预训练模型?它不是在开发新东西,只是在预训练的庞大分布中选择期望的子分布?
Stephen McAleer(@McaleerStephen):
非常酷!
Aki Ranin(@aki_ranin)更直接:
人类在循环中没戏了。
Michael Spencer(@ReadFuturist)则表示怀疑:
击败人类意味着什么?Anthropic甚至无法让Claude写自己的博客。
Oyx(@Test20061722)指出评估方法的潜在问题:
助手胜率只由专有奖励模型判断,而非盲测的人类评估。基于模型的判断可能偏向钻空子的策略,60%胜率可能无法转化为真实的人类偏好!
相关研究
Xuandong Zhao(@xuandongzhao)分享了他们的「无需外部奖励学习推理」研究。Jiaxin Wen澄清了两项工作的区别:
最近的「无监督学习」论文主要关注推理基准+强化学习,而我们更关注通用的、模糊的奖励建模任务+监督微调。SFT的训练动态对我来说更清晰——用随机演示进行SFT肯定会导致更差的性能。
为确保结果可靠,团队进行了多次验证,包括将数据集复制到新文件(排除所有标签)重新运行算法,一位合著者还使用不同代码库独立复现了结果。
AI真的在「左脚踩右脚」了——
通过自己给自己打分、自己纠正自己的错误,模型实现了自我提升。

这种自我微调的能力让AI彻底摆脱了人类监督的枷锁,正在向着真正的自主学习迈进。
虽然现在还不能真的「上天」,但这或将是通往AGI的重要一步。
论文原文: https://alignment-science-blog.pages.dev/2025/unsupervised-elicitation/paper.pdf
[2]项目博客: https://alignment-science-blog.pages.dev/2025/unsupervised-elicitation/
[3]代码仓库: https://github.com/Jiaxin-Wen/Unsupervised-Elicitation
[4]arXiv论文: https://arxiv.org/abs/2506.10139
(文:AGI Hunt)