


-
广泛的 GPU 兼容性:无缝支持 Apple Mac、Windows PC 和 Linux 服务器上各种供应商(NVIDIA、AMD、Apple、昇腾、海光、摩尔线程、天数智芯)的 GPU。 -
广泛的模型支持:支持各种模型,包括大语言模型 LLM、多模态 VLM、图像模型、语音模型、文本嵌入模型和重排序模型。 -
灵活的推理后端:支持与 llama-box(llama.cpp 和 stable-diffusion.cpp)、vox-box、vLLM 和 Ascend MindIE 等多种推理后端的灵活集成。 -
多版本后端支持:同时运行推理后端的多个版本,以满足不同模型的不同运行依赖。 -
分布式推理:支持单机和多机多卡并行推理,包括跨供应商和运行环境的异构 GPU。 -
可扩展的 GPU 架构:通过向基础设施添加更多 GPU 或节点轻松进行扩展。 -
强大的模型稳定性:通过自动故障恢复、多实例冗余和推理请求的负载平衡确保高可用性。 -
智能部署评估:自动评估模型资源需求、后端和架构兼容性、操作系统兼容性以及其他与部署相关的因素。 -
自动调度:根据可用资源动态分配模型。 -
轻量级 Python 包:最小依赖性和低操作开销。 -
OpenAI 兼容 API:完全兼容 OpenAI 的 API 规范,实现无缝迁移和快速适配。 -
用户和 API 密钥管理:简化用户和 API 密钥的管理。 -
实时 GPU 监控:实时跟踪 GPU 性能和利用率。 -
令牌和速率指标:监控 Token 使用情况和 API 请求速率。
docker run -d --name gpustack \
--restart=unless-stopped \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \ -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \ -v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \ -v /etc/ascend_install.info:/etc/ascend_install.info \
--network=host \
--ipc=host \ -v gpustack-data:/var/lib/gpustack \ crpi-thyzhdzt86bexebt.cn-hangzhou.personal.cr.aliyuncs.com/gpustack_ai/gpustack:v0.6.2-npu \
--port 9090docker logs -f gpustackdocker exec -it gpustack cat /var/lib/gpustack/initial_admin_password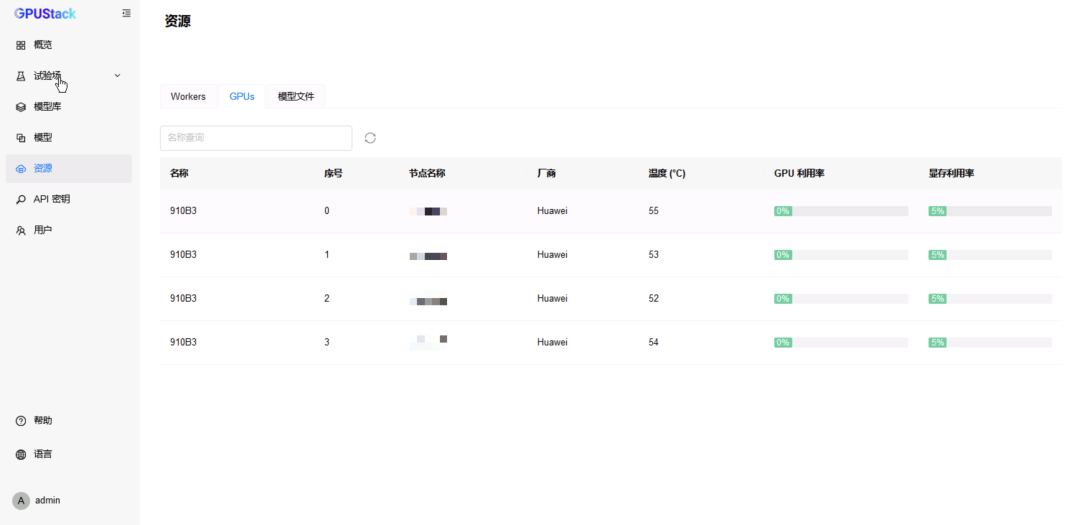
-
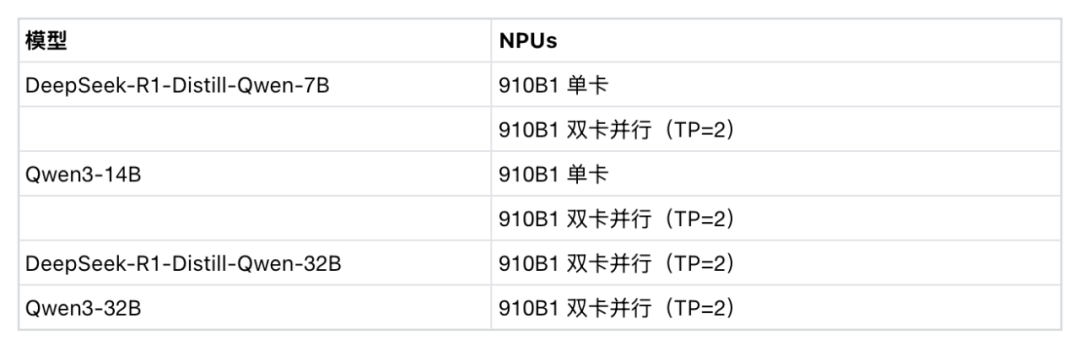
对于 vLLM 后端,可以设置 –tensor-parallel-size=2 或手动选择 2 卡来分配 2 块 NPU -
对于 MindIE 后端,可以手动选择 2 卡来分配 2 块 NPU
-
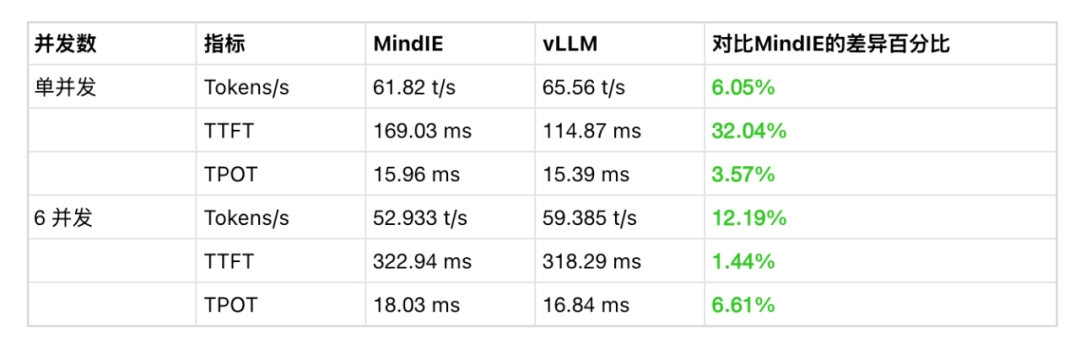
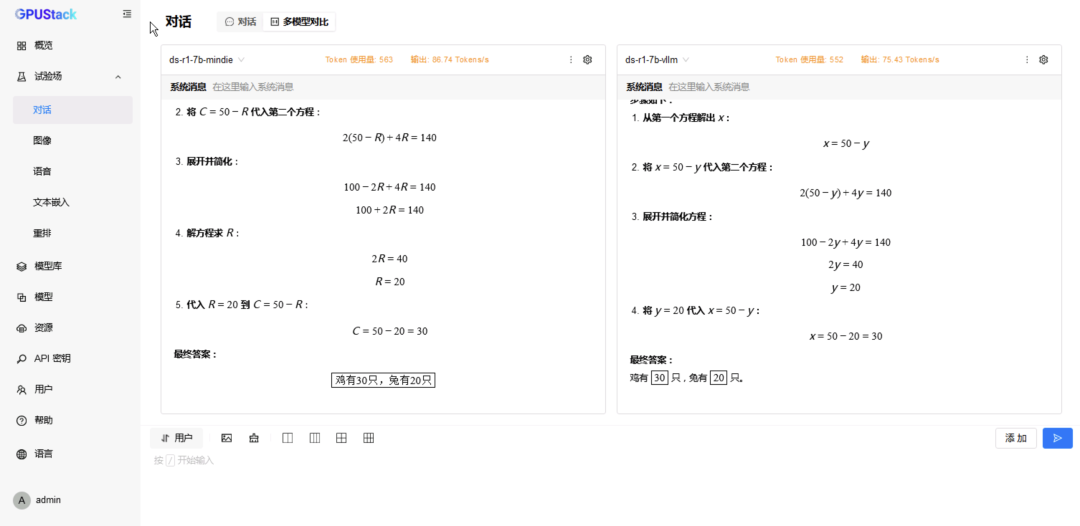
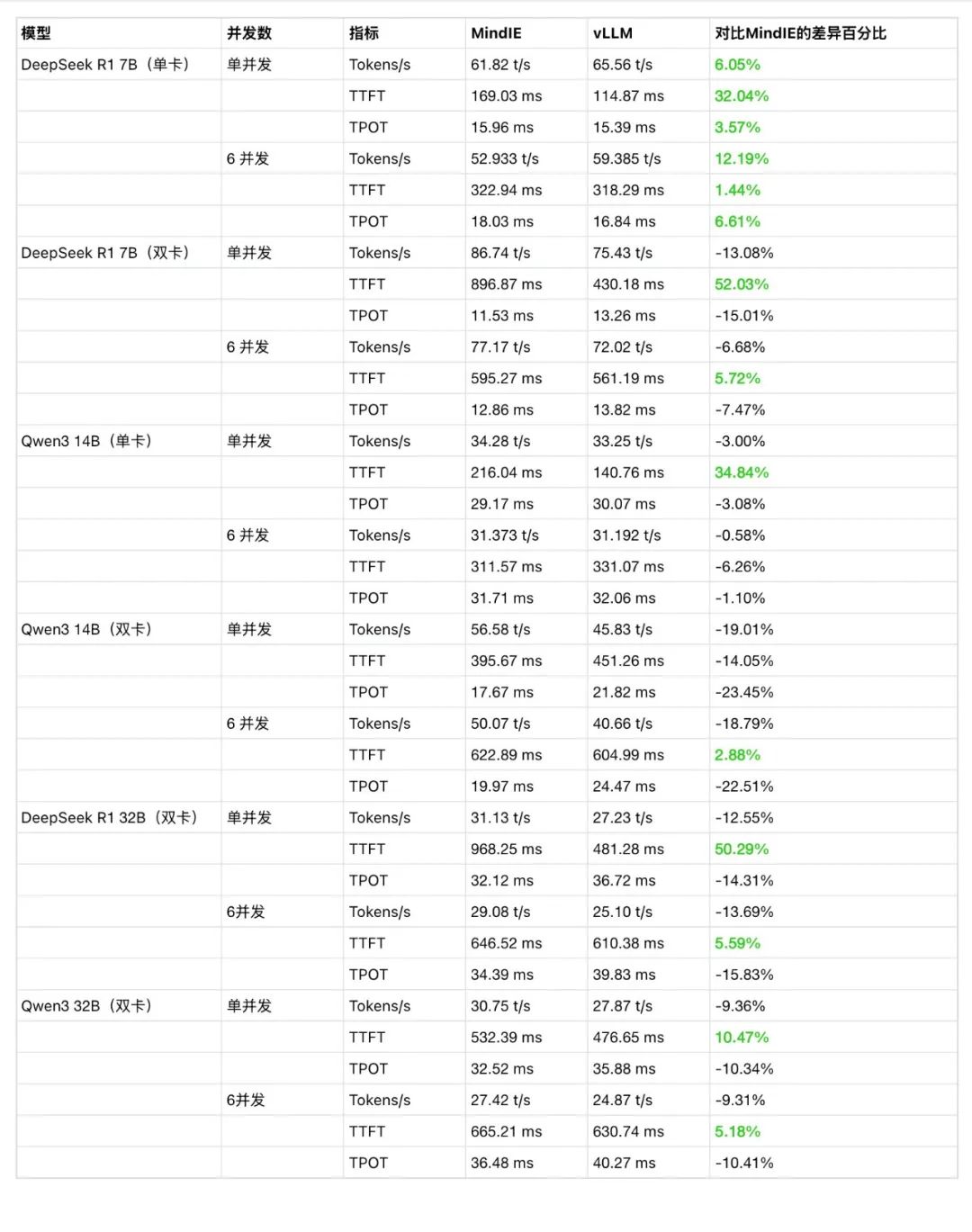
在 试验场-对话-多模型对比,分别选择两种后端运行的 DeepSeek-R1-Distill-Qwen-7B 模型进行对比测试; -
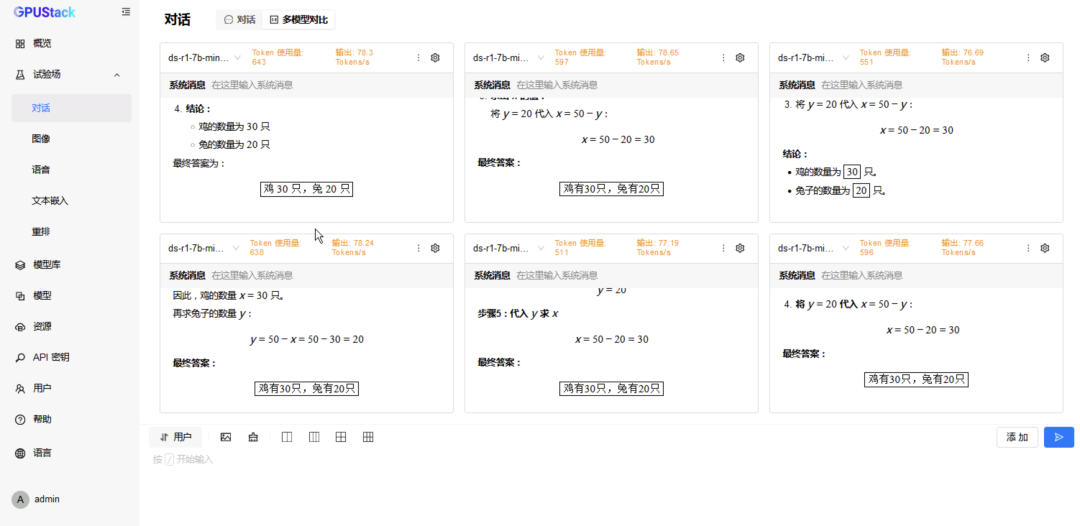
切换到 6 模型对比,重复选择 vLLM Ascend 运行的模型测试 6 并发请求; -
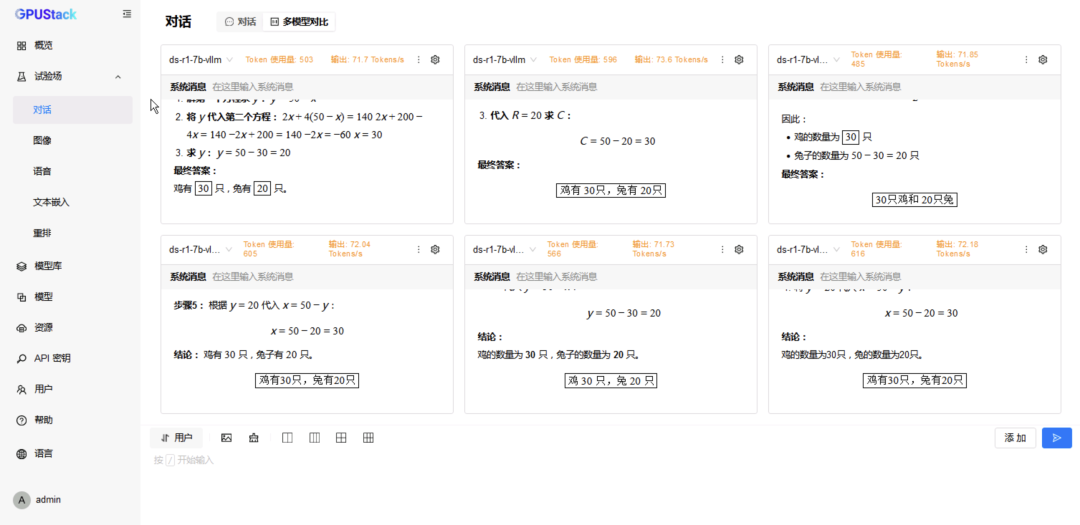
更换 MindIE 运行的模型测试 6 并发请求。
-
在 模型,分别选择两种后端运行的 DeepSeek-R1-Distill-Qwen-7B 模型,修改配置分配 2 卡并重建生效; -
在 试验场-对话-多模型对比,分别选择两种后端运行的 DeepSeek-R1-Distill-Qwen-7B 模型进行对比测试; -
切换到 6 模型对比,重复选择 vLLM Ascend 运行的模型测试 6 并发请求; -
更换 MindIE 运行的模型测试 6 并发请求。
-
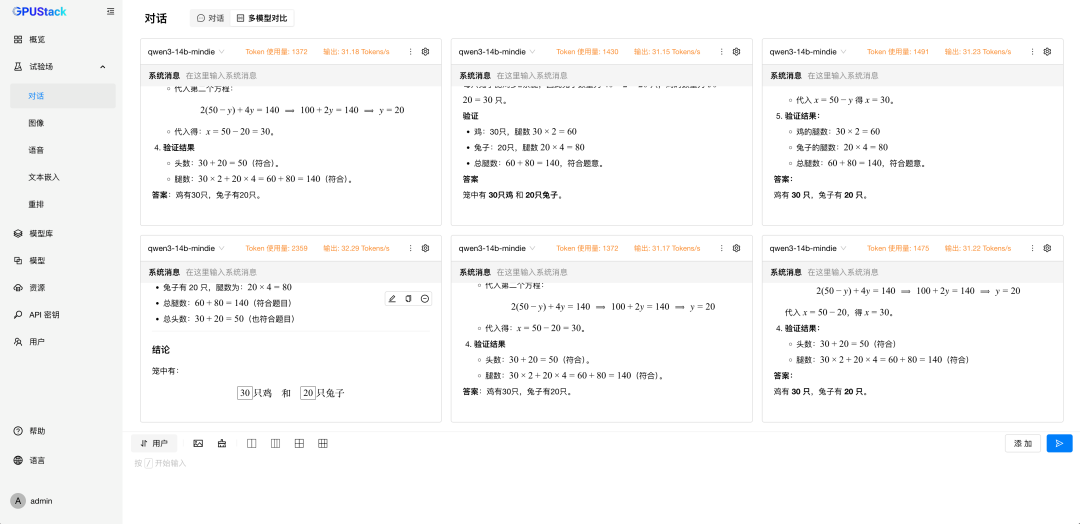
在 试验场-对话-多模型对比,分别选择两种后端运行的 DeepSeek-R1-Distill-Qwen-14B 模型进行对比测试; -
切换到 6 模型对比,重复选择 vLLM Ascend 运行的模型测试 6 并发请求; -
更换 MindIE 运行的模型测试 6 并发请求。


-
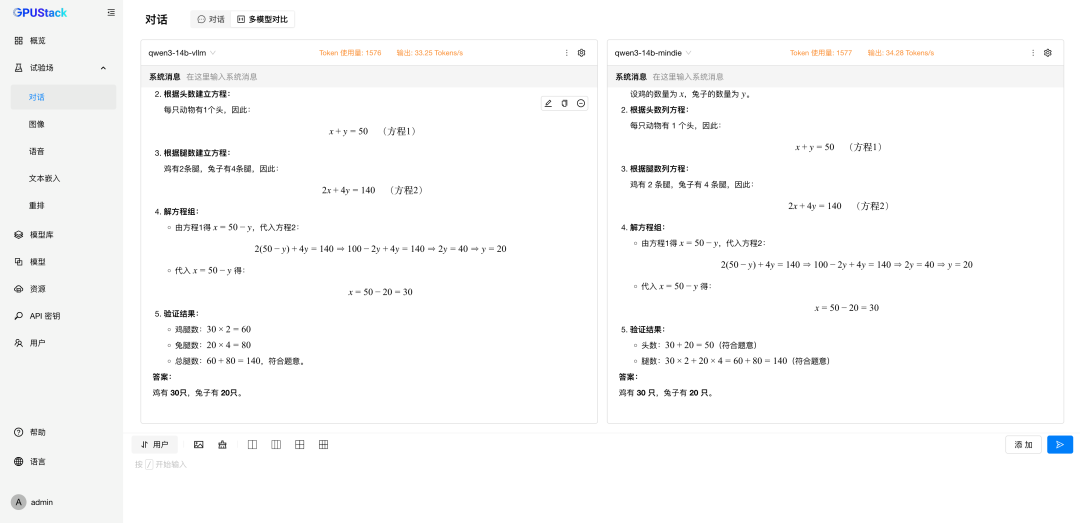
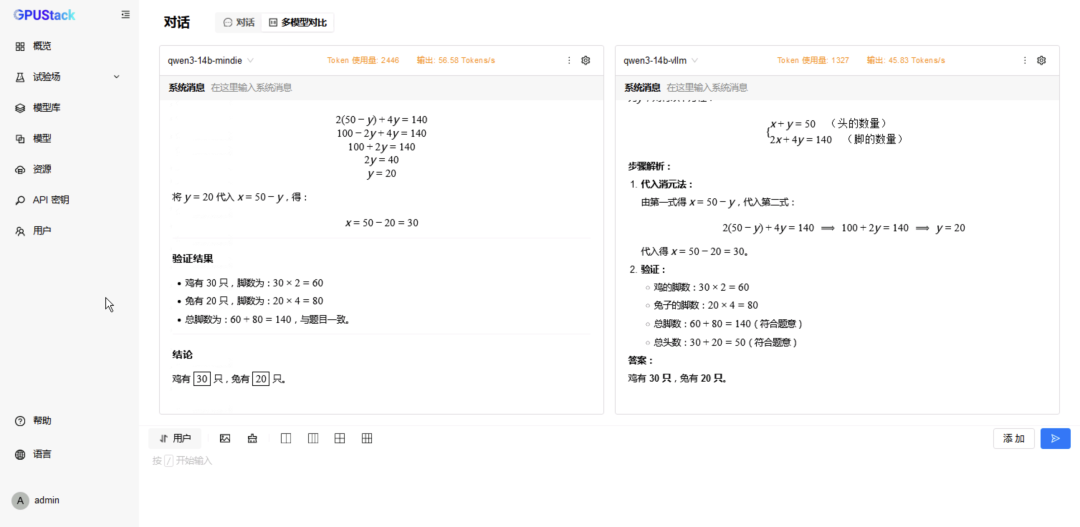
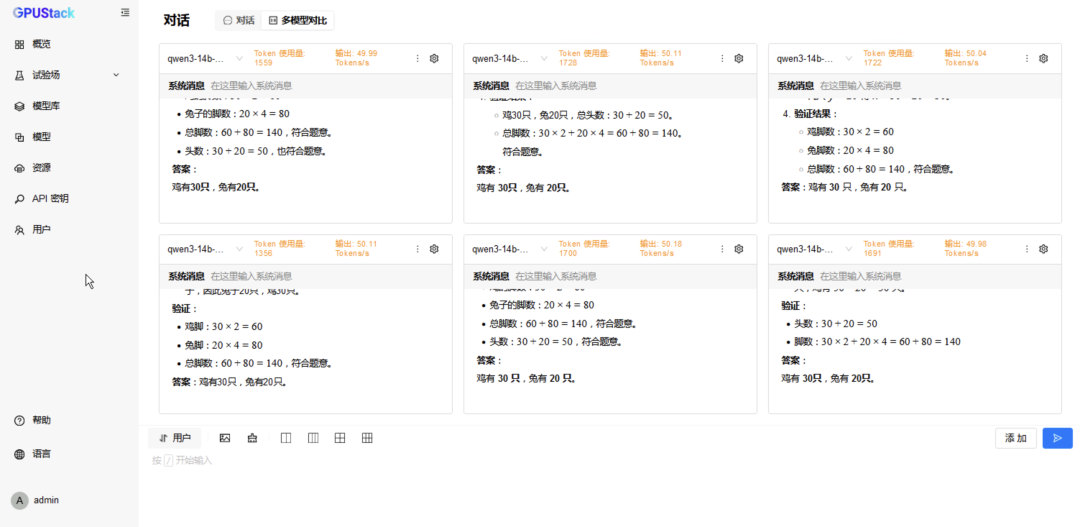
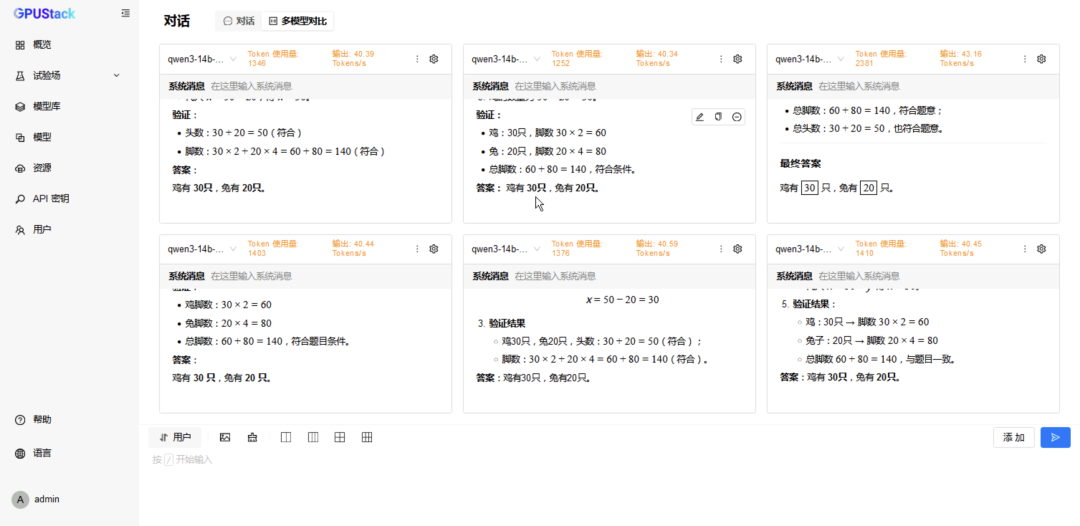
在 模型,分别选择两种后端运行的 DeepSeek-R1-Distill-Qwen-14B 模型,修改配置分配 2 卡并重建生效; -
在 试验场-对话-多模型对比,分别选择两种后端运行的 DeepSeek-R1-Distill-Qwen-14B 模型进行对比测试; -
切换到 6 模型对比,重复选择 vLLM Ascend 运行的模型测试 6 并发请求; -
更换 MindIE 运行的模型测试 6 并发请求。

-
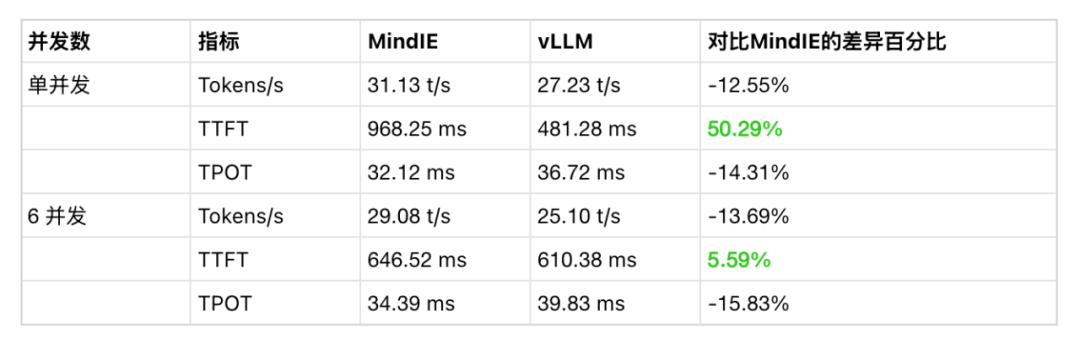
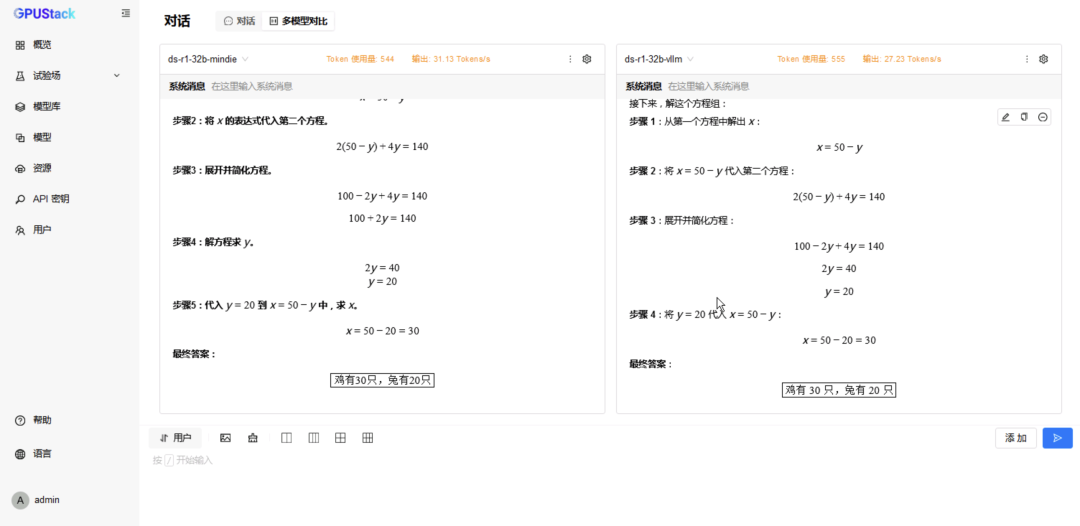
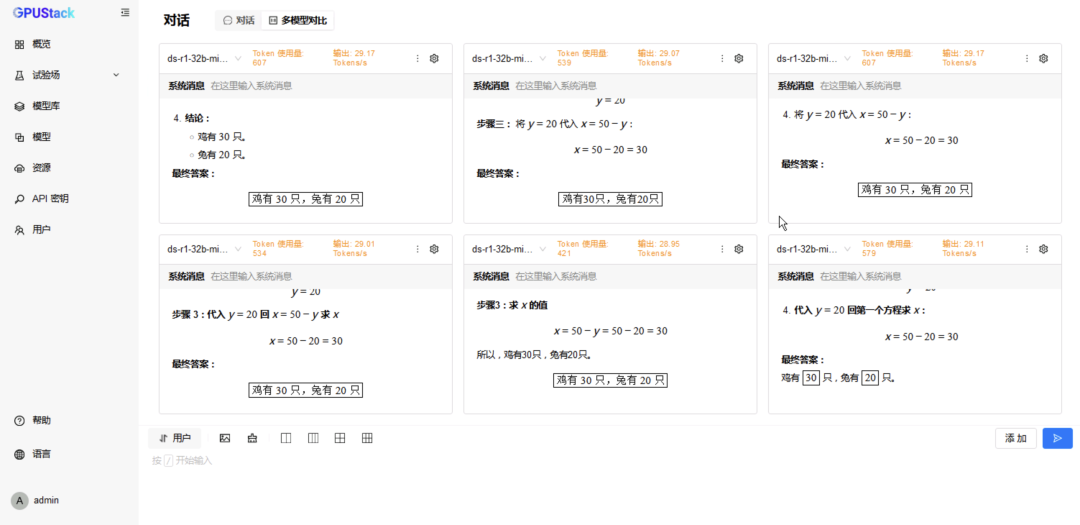
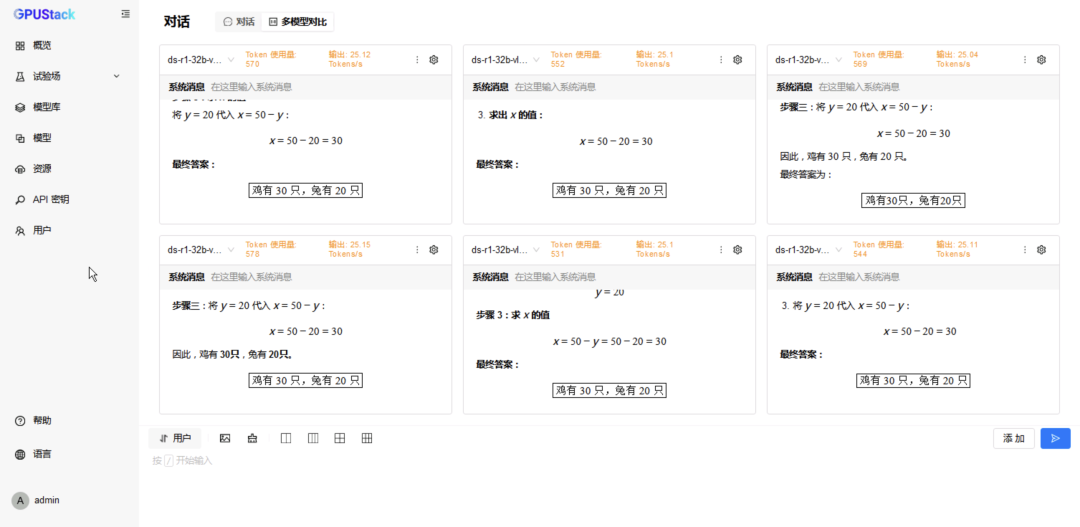
在 试验场-对话-多模型对比,分别选择两种后端运行的 DeepSeek-R1-Distill-Qwen-32B 模型进行对比测试; -
切换到 6 模型对比,重复选择 vLLM Ascend 运行的模型测试 6 并发请求; -
更换 MindIE 运行的模型测试 6 并发请求。
-
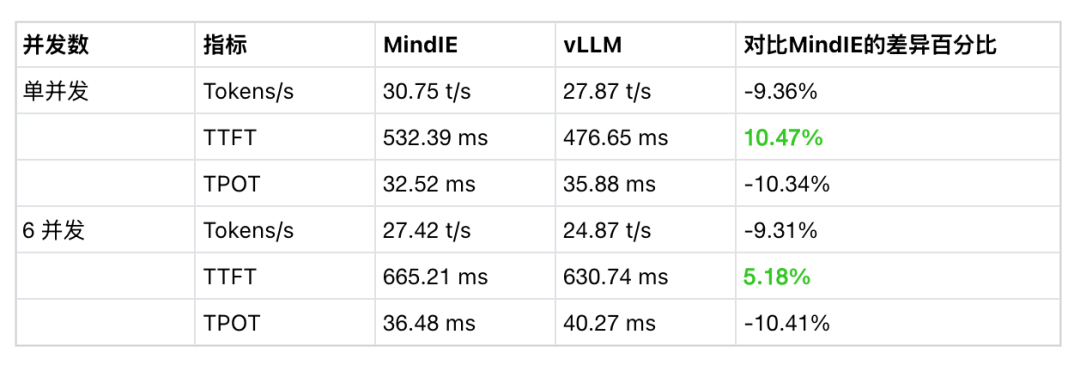
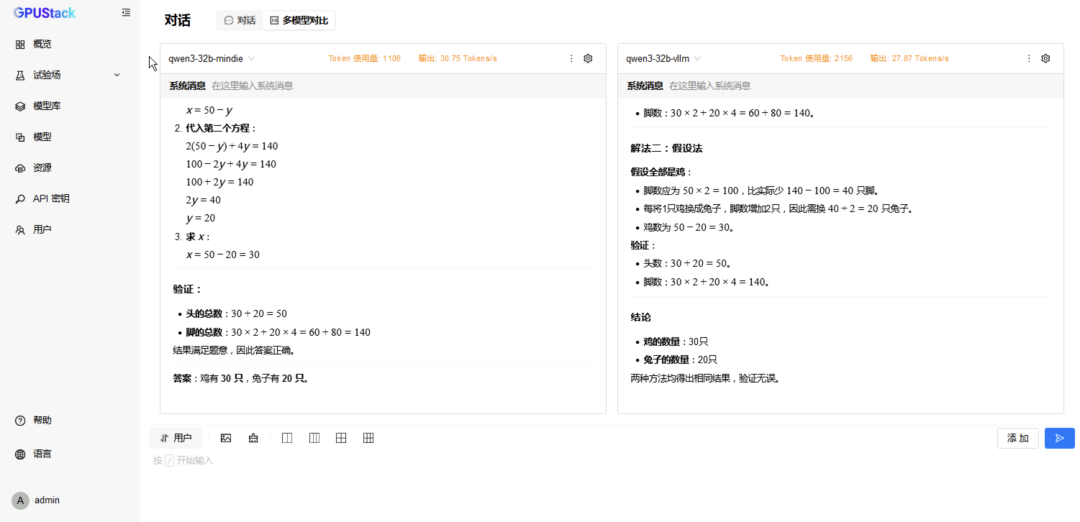
在 试验场-对话-多模型对比,分别选择两种后端运行的 Qwen3-32B 模型进行对比测试; -
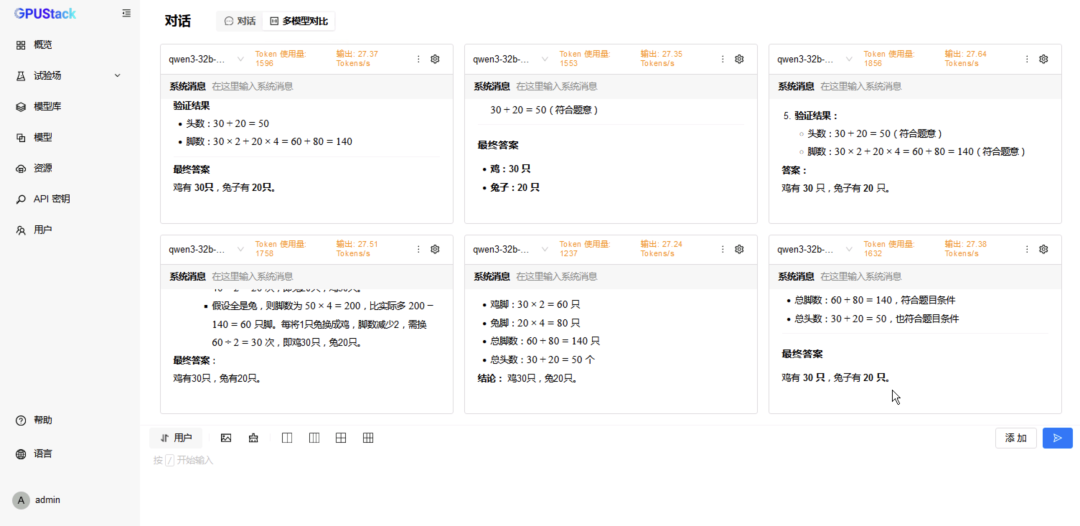
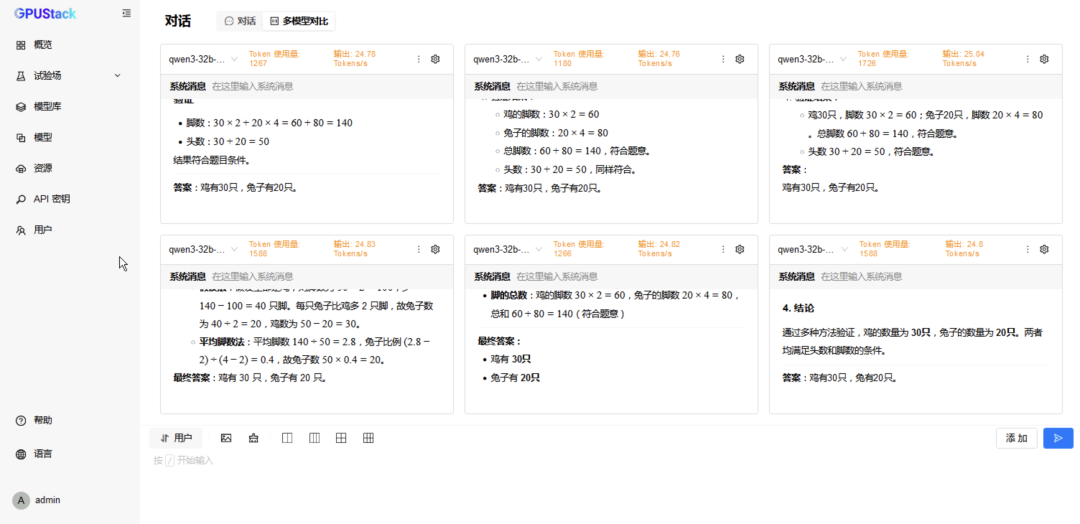
切换到 6 模型对比,重复选择 vLLM Ascend 运行的模型测试 6 并发请求; -
更换 MindIE 运行的模型测试 6 并发请求。
⭐
(文:AI寒武纪)