

LEMMA项目组 投稿
量子位 | 公众号 QbitAI
大模型学习不仅要正确知识,还需要一个“错题本”?
上海AI Lab提出了一种新的学习方式,构建了“错误-反思-修正”数据,让大模型仿照人类的学习模式,从错误中学习、反思。
结果,在Llama3-8B上,数学题的解题准确率平均提升了13.3%。

这种方法名为LEMMA(Learning from Errors for Mathematical Advancement),专门教大模型如何从错误中学习。
作者通过深入分析模型犯下的错误,构建了“错误-纠正”数据集,并利用反思机制,引导模型从错误的思路平滑过渡到正确的答案。
结果,模型不仅获得了准确率的提升,还获得了超强的自主纠错能力和泛化能力。
相关论文已发表于ACL’25 Findings。

用教师模型生成“错题本”
作者首先系统分析了当前主流大模型在数学题中常见的七大类错误(如题意误解、公式混淆、计算失误等),发现这些错误在不同模型之间分布非常一致。
结果显示,大模型犯下最多的错误是误解题意,占比超过40%,随后的两张常见错误类型是公式混淆和计算错误。
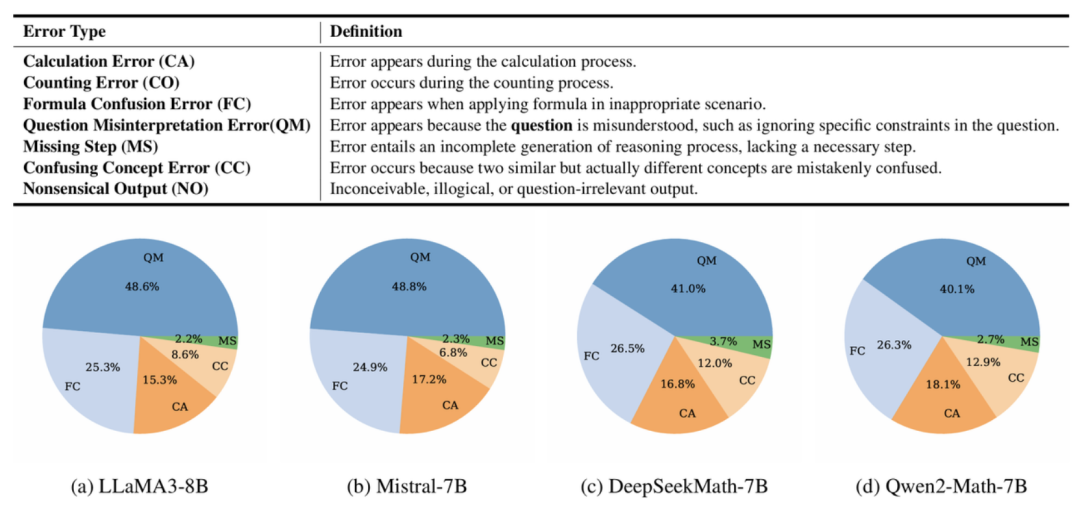
了解了模型都会犯哪些错误,接下来就可以有针对性地生成数据了。
过去,整个过程往往通过提高采样Temperature(如T=1.0或T=1.1)来完成。
但作者发现高Temperature采样会引入大量无意义的(如语义不通、毫无逻辑)错误,这种错误实际上是模型不会犯的。
作者认为,这种“已读乱回”式的错误,难以让模型真正提升自我纠错能力。

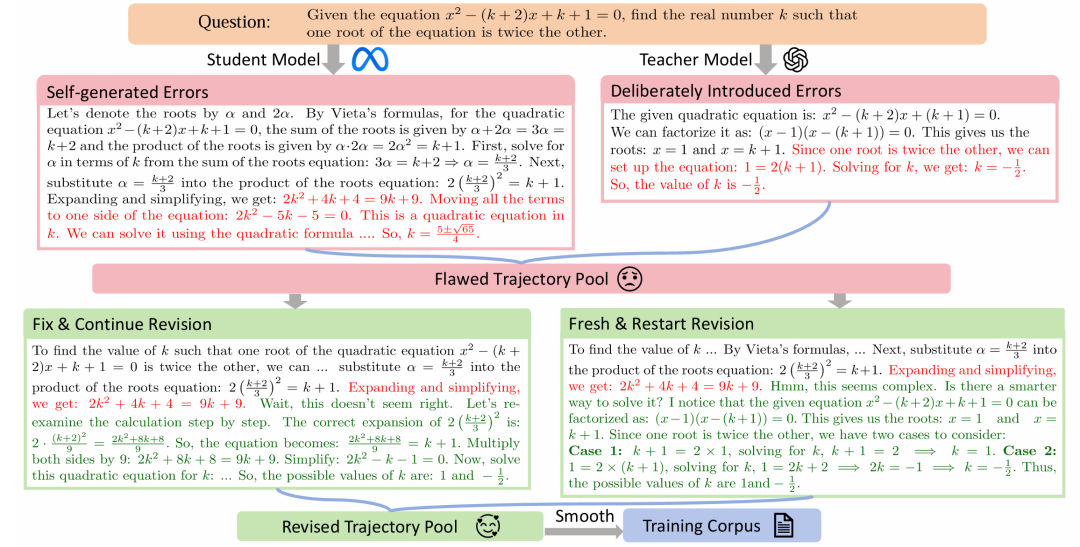
为此,LEMMA采用了新的方法,让教师模型定向制造“学生会犯的错”,构造“反思式”数据:
具体来说,LEMMA提出了一种全新的反思数据构造策略,主要包括三个环节:
-
首先,分析学生模型常犯哪些错(如题意误解、公式误用、计算失误); -
然后让强大的教师模型(GPT-4o),根据学生模型在每个问题上的错误类型,有针对性地故意引入特定错误; -
之后,教师模型还会标出第一个错误发生的步骤,并生成反思和改正,确保模型学会“及时反思”。
在反思和改正阶段:LEMMA采用了两种更贴近人类思维的纠错方式——一是返回上一步,二是直接推倒重来。
引入第二种修正方式的原因在于,作者发现大模型在有的题目上出错的根本原因,是一开始就选择了低效的暴力解法,这样即使修正了某个中间的错误步骤,也会在后续的推理中犯错,不如从头开始选择更“聪明”的解法。
总的来说,LEMMA构建的是“有目标、有指导、有反馈”的错误数据,让模型能像学生一样反思:“我错在哪?应该怎么改?”
实验结果
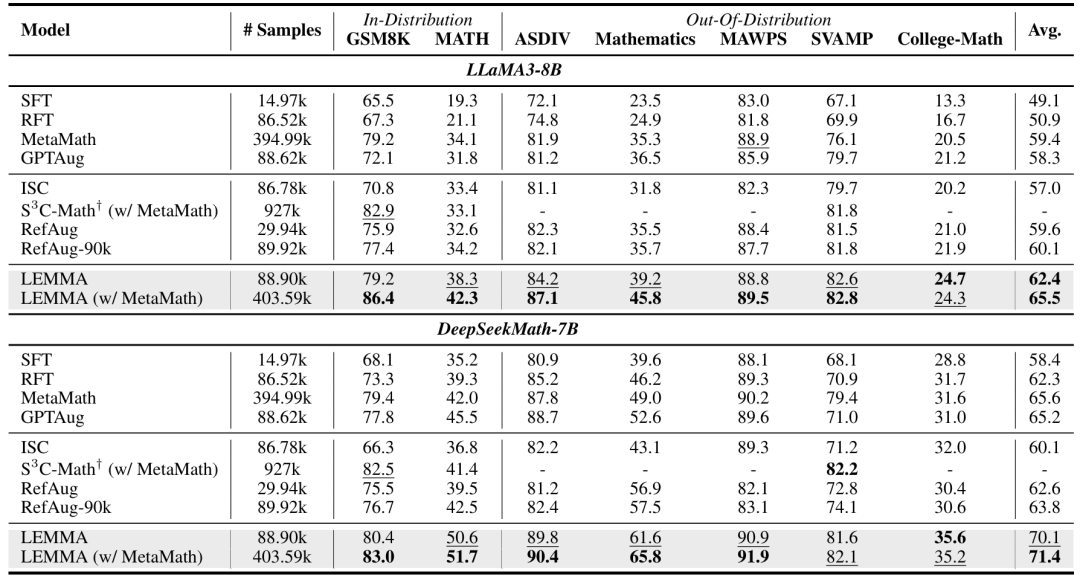
对比多种主流反思修正方法,优势明显。
作者对比了包括RefAug、RFT,ISC、S3C-Math在内的八种主流baseline方法。
结果表明,LEMMA在常见的数学任务上正确率更高,在Llama3-8B上准确率提升了最高达13.3%。
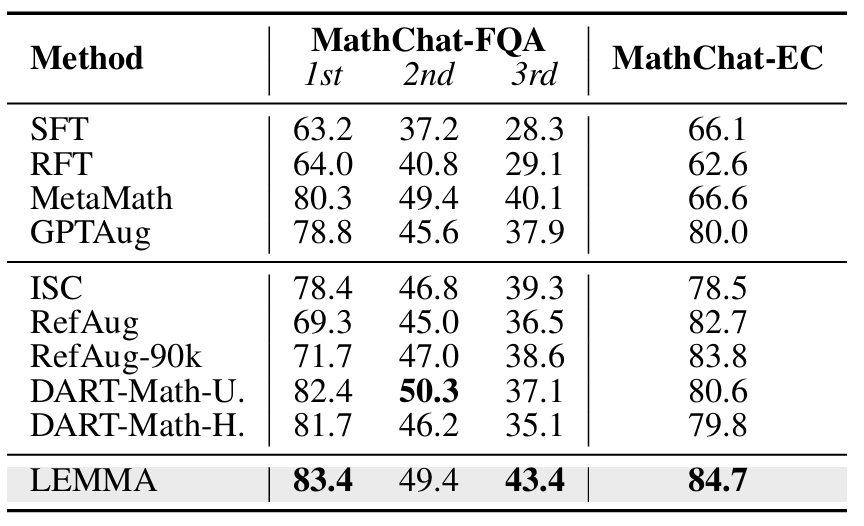
并且,LEMMA有效提升了模型的反思和自我修正能力。
在MathChat任务中,LEMMA在“追问回答”和“错误修正”两大任务上领先SOTA方法(Dart-MATH)多达6.3和4.1个百分点。
同时,LEMMA也显著减少了模型的常见错误。
在生成的数据上进行微调之后,LEMMA一致地降低了各种错误类型,提升模型推理精度。
相比之下,SFT虽然整体准确率提升,但却在某些错误类型(如公式混淆)上反而变差。

另外,作者进行的消融实验也充分验证了“教师模型错误引入(Error Aug.)”和“从头修正(Fresh & Restart)”两个关键模块的有效性。
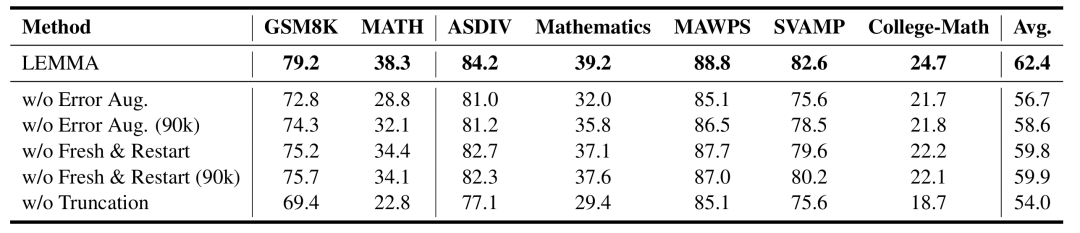
总之,LEMMA提出了一种让大模型在数学推理中“从错误中有效学习”的创新方法,提升了模型对推理错误的识别与修复能力。
相比以往依赖高Temperature采样和简单拼接的反思数据合成方式,LEMMA 显著提高了“错误-反思-修正”数据的质量,提升了模型的数学推理能力。
论文地址:
https://arxiv.org/abs/2503.17439
代码仓库:
https://github.com/pzs19/LEMMA
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)