

-
nanoVLM https://github.com/huggingface/nanoVLM -
免费的 Colab Notebook https://colab.research.google.com/github/huggingface/nanoVLM/blob/main/nanoVLM.ipynb
我们受到了
Andrej Karpathy 的nanoGPT 的启发,为视觉领域提供了一个类似的项目。Andrej Karpathy https://karpathy.ai/ nanoGPT https://github.com/karpathy/nanoGPT
从本质上讲,nanoVLM 是一个 工具包,可以帮助你构建和训练一个能够理解图像和文本,并基于此生成文本的模型。nanoVLM 的魅力在于它的 简洁性 。整个代码库被有意保持 最小化 和 可读性 ,使其非常适合初学者或任何想要深入了解 VLM 内部机制而不被复杂性淹没的人。
在这篇博客中,我们将介绍该项目背后的核心思想,并提供与代码库交互的简单方法。我们不仅会深入项目细节,还会将所有内容封装起来,让你能够快速上手。
简要
你可以按照以下步骤使用我们的 nanoVLM 工具包开始训练视觉语言模型:
# 克隆仓库
git clone https://github.com/huggingface/nanoVLM.git
# 执行训练脚本
python train.py
这里有一个
什么是视觉语言模型?
顾名思义,视觉语言模型 (VLM) 是一种处理两种模态的多模态模型: 视觉和文本。这些模型通常以图像和/或文本作为输入,生成文本作为输出。
基于对图像和文本 (输入) 的理解来生成文本 (输出) 是一个强大的范式。它支持广泛的应用,从图像字幕生成和目标检测到回答关于视觉内容的问题 (如下表所示)。需要注意的是,nanoVLM 仅专注于视觉问答作为训练目标。
 |
||
|
|
|
|
|
|
<locxx><locxx><locxx><locxx> |
|
|
|
<segxx><segxx><segxx> |
|
|
|
|
|
如果你有兴趣了解更多关于 VLM 的信息,我们强烈建议阅读我们关于该主题的最新博客:
视觉语言模型 (更好、更快、更强) https://hf.co/blog/vlms-2025
使用代码库
“废话少说,直接看代码” – 林纳斯·托瓦兹
在本节中,我们将引导你了解代码库。在跟随学习时,保持一个
以下是我们仓库的文件夹结构。为简洁起见,我们删除了一些辅助文件。
.
├── data
│ ├── collators.py
│ ├── datasets.py
│ └── processors.py
├── generate.py
├── models
│ ├── config.py
│ ├── language_model.py
│ ├── modality_projector.py
│ ├── utils.py
│ ├── vision_language_model.py
│ └── vision_transformer.py
└── train.py
架构
.
├── data
│ └── ...
├── models # 👈 你在这里
│ └── ...
└── train.py
我们按照两个知名且广泛使用的架构来建模 nanoVLM。我们的视觉主干网络 ( models/vision_transformer.py ) 是标准的视觉 transformer,更具体地说是谷歌的
-
SigLIP https://hf.co/docs/transformers/en/model_doc/siglip -
Llama 3 https://hf.co/docs/transformers/en/model_doc/llama3
视觉和文本模态通过模态投影模块进行 对齐 。该模块将视觉主干网络产生的图像嵌入作为输入,并将它们转换为与语言模型嵌入层的文本嵌入兼容的嵌入。然后将这些嵌入连接起来并输入到语言解码器中。模态投影模块由像素洗牌操作和线性层组成。
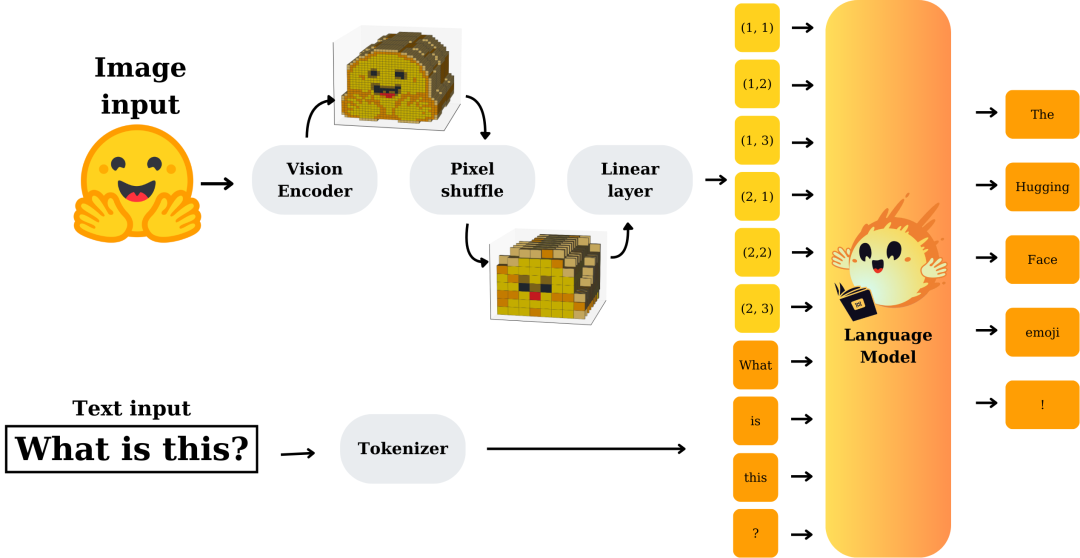 |
|---|
|
|
 |
|---|
|
|
所有文件都非常轻量且有良好的文档说明。我们强烈建议你逐个查看它们,以更好地理解实现细节 ( models/xxx.py )
在训练时,我们使用以下预训练的主干权重:
-
视觉主干: google/siglip-base-patch16-224 https://hf.co/google/siglip-base-patch16-224 -
语言主干: HuggingFaceTB/SmolLM2-135M https://hf.co/HuggingFaceTB/SmolLM2-135M
也可以将主干网络替换为 SigLIP/SigLIP 2 (用于视觉主干) 和 SmolLM2 (用于语言主干) 的其他变体。
训练你自己的 VLM
现在我们已经熟悉了架构,让我们换个话题,讨论如何使用 train.py 训练你自己的视觉语言模型。
.
├── data
│ └── ...
├── models
│ └── ...
└── train.py # 👈 你在这里
你可以通过以下命令启动训练:
python train.py
这个脚本是整个训练流程的一站式解决方案,包括:
-
数据集加载和预处理 -
模型初始化 -
优化和日志记录
配置
在任何其他操作之前,脚本从 models/config.py 加载两个配置类:
-
TrainConfig: 对训练有用的配置参数,如学习率、检查点路径等。 -
VLMConfig: 用于初始化 VLM 的配置参数,如隐藏维度、注意力头数等。
数据加载
数据流水线的核心是 get_dataloaders 函数。它:
-
通过 Hugging Face 的 load_datasetAPI 加载数据集。 -
组合和洗牌多个数据集 (如果提供)。 -
通过索引应用训练/验证分割。 -
将它们包装在自定义数据集 ( VQADataset、MMStarDataset) 和整理器 (VQACollator、MMStarCollator) 中。
这里一个有用的标志是
data_cutoff_idx,对于在小子集上调试很有用。
模型初始化
模型通过 VisionLanguageModel 类构建。如果你从检查点恢复,操作非常简单:
from models.vision_language_model import VisionLanguageModel
model = VisionLanguageModel.from_pretrained(model_path)
否则,你将获得一个全新初始化的模型,可选择为视觉和语言预加载主干网络。
优化器设置: 两个学习率
由于模态投影器 ( MP ) 是新初始化的,而主干网络是预训练的,优化器被分成两个参数组,每个都有自己的学习率:
-
MP 使用较高的学习率 -
编码器/解码器堆栈使用较小的学习率
这种平衡确保 MP 快速学习,同时保留视觉和语言主干网络中的知识。
训练循环
这部分相当标准但结构合理:
-
使用 torch.autocast进行混合精度以提高性能。 -
通过 get_lr实现带线性预热的余弦学习率调度。 -
每批记录令牌吞吐量 (令牌/秒) 以进行性能监控。
每 250 步 (可配置),模型在验证集和 MMStar 测试数据集上进行评估。如果准确率提高,模型将被保存为检查点。
日志记录和监控
如果启用了 log_wandb ,训练统计信息如 batch_loss 、val_loss 、accuracy 和 tokens_per_second 将记录到 Weights & Biases 以进行实时跟踪。
运行使用元数据自动命名,如样本大小、批次大小、epoch 数、学习率和日期,全部由辅助函数 get_run_name 处理。
推送到 Hub
使用以下方法将训练好的模型推送到 Hub,供其他人查找和测试:
model.save_pretrained(save_path)
你可以轻松地使用以下方式推送它们:
model.push_to_hub("hub/id")
在预训练模型上运行推理
使用 nanoVLM 作为工具包,我们训练了一个google/siglip-base-patch16-224 和 HuggingFaceTB/SmolLM2-135M 作为主干网络。该模型在单个 H100 GPU 上对
-
Hugging Face Hub 地址 https://hf.co/lusxvr/nanoVLM-222M -
cauldron https://hf.co/datasets/HuggingFaceM4/the_cauldron
这个模型并不旨在与最先进的模型竞争,而是为了揭示 VLM 的组件和训练过程。
.
├── data
│ └── ...
├── generate.py # 👈 你在这里
├── models
│ └── ...
└── ...
让我们使用 generate.py 脚本在训练好的模型上运行推理。你可以使用以下命令运行生成脚本:
python generate.py
这将使用默认参数并在图像 assets/image.png 上运行查询 “What is this?”。
你可以在自己的图像和提示上使用此脚本,如下所示:
python generate.py --image path/to/image.png --prompt "你的提示在这里"
如果你想可视化脚本的核心,就是这些行:
model = VisionLanguageModel.from_pretrained(source).to(device)
model.eval()
tokenizer = get_tokenizer(model.cfg.lm_tokenizer)
image_processor = get_image_processor(model.cfg.vit_img_size)
template = f"Question: {args.prompt} Answer:"
encoded = tokenizer.batch_encode_plus([template], return_tensors="pt")
tokens = encoded["input_ids"].to(device)
img = Image.open(args.image).convert("RGB")
img_t = image_processor(img).unsqueeze(0).to(device)
print("\nInput:\n ", args.prompt, "\n\nOutputs:")
for i in range(args.generations):
gen = model.generate(tokens, img_t, max_new_tokens=args.max_new_tokens)
out = tokenizer.batch_decode(gen, skip_special_tokens=True)[0]
print(f" >> Generation {i+1}: {out}")
我们创建模型并将其设置为 eval 。初始化分词器 (用于对文本提示进行分词) 和图像处理器 (用于处理图像)。下一步是处理输入并运行 model.generate 以生成输出文本。最后,使用 batch_decode 解码输出。
|
|
|
|
|---|---|---|
|
|
|
|
 |
|
|
如果你想在 UI 界面中对训练好的模型运行推理,
这里 有一个 Hugging Face Space 供你与模型交互。https://hf.co/spaces/ariG23498/nanovlm
结论
在这篇博客中,我们介绍了什么是 VLM,探讨了支撑 nanoVLM 的架构选择,并详细解释了训练和推理工作流程。
通过保持代码库轻量级和可读性,nanoVLM 旨在既作为学习工具,又作为你可以在此基础上构建的基础。无论你是想了解多模态输入如何对齐,还是想在自己的数据集上训练 VLM,这个仓库都能让你快速入门。
如果你尝试了它,并在它的基础上尝试构建,或者你只是有问题,我们都很乐意听到你的反馈。祝你探索愉快!
参考文献
-
GitHub – huggingface/nanoVLM: 用于训练/微调小型 VLM 的最简单、最快速的代码库。 https://github.com/huggingface/nanoVLM -
视觉语言模型 (更好、更快、更强) https://hf.co/blog/vlms-2025 -
视觉语言模型详解 https://hf.co/blog/vlms -
深入视觉语言预训练 https://hf.co/blog/vision_language_pretraining -
SmolVLM: 重新定义小型高效多模态模型 https://hf.co/papers/2504.05299
英文原文:
https://hf.co/blog/nanovlm 原文作者: Aritra Roy Gosthipaty, Luis Wiedmann, Andres Marafioti, Sergio Paniego, Merve Noyan, Pedro Cuenca, Vaibhav Srivastav
翻译: innovation64
(文:Hugging Face)