


随着人工智能技术的飞速发展,AI在视频生成领域的应用越来越广泛。从简单的动画到复杂的影视特效,AI视频生成技术正在为内容创作带来前所未有的变革。字节跳动开源的ContentV项目,凭借其高效的训练框架和强大的生成能力,为AI视频生成领域带来了新的突破。

一、项目概述
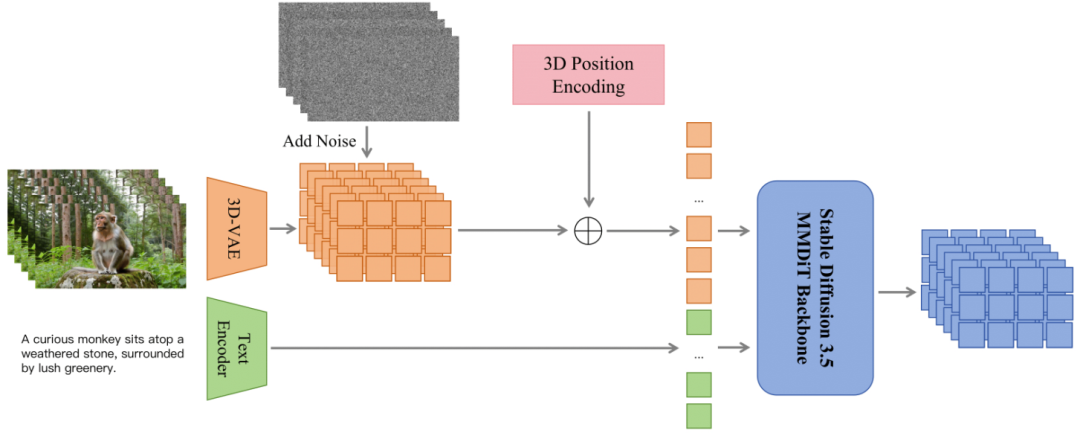
ContentV是由字节跳动开源的80亿参数文生视频模型框架,旨在通过高效的训练策略和极简架构实现高质量视频生成。该项目通过将Stable Diffusion 3.5 Large的2D-VAE替换为3D-VAE并引入3D位置编码,结合多阶段训练策略和强化学习人类反馈框架,在仅使用有限计算资源的情况下,达到了85.14的VBench评分,仅次于Wan2.1-14B。ContentV不仅支持文本到视频的生成,还具备自定义视频参数、风格迁移与融合、视频续写和修改等多种功能,能够满足多样化的视频创作需求。
二、技术原理
(一)极简架构设计
ContentV采用极简架构,最大化复用预训练的图像生成模型进行视频生成。其核心改动是将Stable Diffusion 3.5 Large(SD3.5L)中的2D-VAE替换为3D-VAE,并引入3D位置编码。这种架构设计不仅保留了预训练图像模型的强大生成能力,还通过3D位置编码增强了模型对视频时间维度的理解,使图像模型能够快速获得视频生成能力。
(二)流匹配(Flow Matching)算法
ContentV使用流匹配算法进行训练,通过连续时间内的直接概率路径实现高效采样。模型经过训练以预测速度,该速度引导噪声样本向数据样本转变,通过最小化预测速度与真实速度之间的均方误差来优化模型参数。这种算法不仅提高了采样效率,还增强了模型对视频动态变化的捕捉能力。
(三)渐进式训练策略
ContentV采用渐进式训练策略,先从低分辨率、短时长的视频开始训练,逐步增加时长和分辨率。这种策略有助于模型更好地学习时间动态和空间细节,同时避免了在高分辨率、长时长视频训练初期可能出现的过拟合问题,提高了模型的稳定性和收敛速度。
(四)多阶段训练
ContentV的训练过程分为多个阶段,包括预训练、监督微调(SFT)和强化学习人类反馈(RLHF)。预训练阶段在大规模数据上进行,学习基本的图像和视频生成能力;SFT阶段在高质量数据子集上进行,提高模型的指令遵循能力;RLHF阶段则通过人类反馈进一步优化生成质量。这种多阶段训练方式不仅提高了模型的生成质量,还降低了对人工标注数据的依赖。
(五)高效分布式训练
ContentV利用64GB内存的NPU构建分布式训练框架,通过解耦特征提取和模型训练、整合异步数据管线和3D并行策略,实现了高效的480P分辨率、24FPS、5秒视频训练。这种高效的分布式训练框架大幅降低了训练成本,提高了训练效率。
三、主要功能
(一)文本到视频生成
用户只需输入文本描述,ContentV即可根据文本内容生成多种类型的视频。无论是简单的动画还是复杂的实拍视频,ContentV都能快速生成高质量的视频内容。
(二)自定义视频参数
ContentV支持用户自定义视频的分辨率、时长、帧率等参数,生成符合特定需求的视频。例如,用户可以生成高清的1080p视频,或者制作适合社交媒体的15秒短视频。
(三)风格迁移与融合
ContentV支持将特定风格应用到生成的视频中,如油画风格、动漫风格或复古风格等,使生成的视频具有独特的艺术效果。此外,用户还可以将多种风格融合在一起,创造出独特的视觉效果。
(四)视频续写与修改
ContentV能够根据用户提供的视频片段续写出后续情节,实现视频内容的扩展。用户还可以对生成的视频进行修改,如改变视频中的场景、人物动作等,以满足不同的创作需求。
(五)视频到文本描述
ContentV可以对生成的视频进行文本描述,帮助用户更好地理解视频内容,实现视频与文本之间的双向交互。
四、应用场景
(一)视频内容创作
ContentV为视频创作者提供了强大的工具支持。教师可以通过输入简单的文本描述,生成与课程内容相关的动画或实拍视频,增强教学的趣味性和互动性;自媒体创作者也可以利用ContentV快速生成吸引人的视频内容,提升创作效率。
(二)游戏开发
在游戏开发中,ContentV可以生成游戏中的动画片段或过场视频,帮助开发者快速创建丰富的内容。通过风格迁移功能,开发者还可以将特定的游戏风格应用到视频中,提升游戏的视觉效果。
(三)虚拟现实(VR)和增强现实(AR)
ContentV生成的视频可以用于VR和AR应用中,为用户提供沉浸式的体验。例如,在VR教育应用中,ContentV可以生成逼真的虚拟场景,帮助用户更好地理解教学内容。
(四)特效制作
在影视制作中,ContentV可以生成复杂的特效场景,如科幻场景、奇幻元素等,帮助特效团队快速实现创意。通过自定义视频参数和风格迁移功能,特效团队可以根据具体需求生成高质量的特效视频。
五、快速使用
(一)环境准备
推荐的PyTorch版本
– GPU:torch >= 2.3.1(CUDA >= 12.2)
– NPU:torch和torch-npu >= 2.1.0(CANN >= 8.0.RC2)。如果使用NPU,需要参考Ascend Extension for PyTorch进行torch-npu的安装。
(二)安装依赖
git clone https://github.com/bytedance/ContentV.gitcd ContentVpip3 install -r requirements.txt
(三)文本到视频生成
1. GPU环境
python3 demo.pyUSE_ASCEND_NPU=1 python3 demo.py通过上述步骤,用户可以在本地环境中快速部署ContentV,并根据文本描述生成视频内容。在实际使用中,用户可以根据需求调整视频的分辨率、时长、帧率等参数,以生成符合特定需求的视频。
六、结语
ContentV作为字节跳动开源的文生视频模型框架,凭借其高效的训练策略、强大的生成能力和丰富的功能,为AI视频生成领域带来了新的突破。通过极简架构设计、流匹配算法、渐进式训练策略和多阶段训练,ContentV在有限的计算资源下实现了高质量视频生成。其支持的文本到视频生成、自定义视频参数、风格迁移与融合、视频续写与修改等功能,为视频创作者、游戏开发者、特效团队等提供了强大的工具支持。
七、项目地址
项目官网:https://contentv.github.io/
Github仓库:https://github.com/bytedance/ContentV
HuggingFace模型库:https://huggingface.co/ByteDance/ContentV-8B
arXiv技术论文:http://export.arxiv.org/pdf/2506.05343
(文:小兵的AI视界)