
Stable Diffusion

miniDiffusion,一个用PyTorch重新实现的Stable Diffusion 3.5
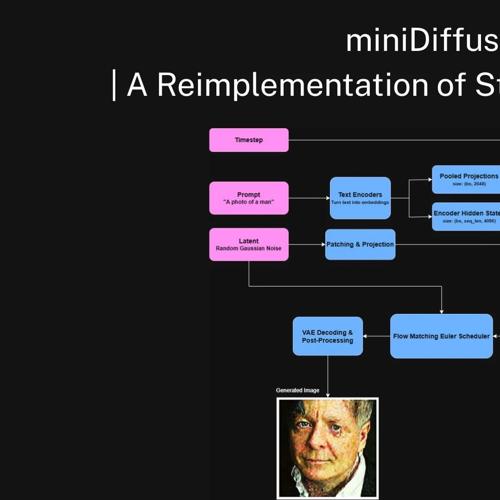
miniDiffusion是用PyTorch实现的Stable Diffusion 3.5项目,包含核心组件和训练/推理脚本,用于教育和实验目的。
ContentV:字节跳动开源的高效文生视频模型框架,助力AI视频生成技术突破

字节跳动开源的ContentV项目通过高效训练策略和极简架构实现了高质量视频生成。支持文本到视频生成、自定义参数、风格迁移等多功能,并已上线多个应用场景。
CVPR2025|突破数据瓶颈!Stable Diffusion 助力视觉异常检测,无需训练即可生成真实多样异常样本
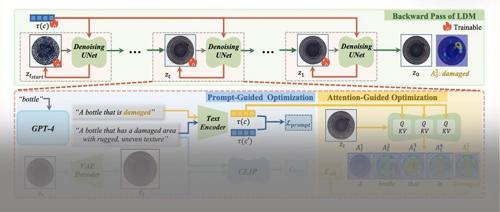
本文介绍了一种名为AnomalyAny的创新框架,利用Stable Diffusion生成能力仅需单个正常样本和文本描述即可生成逼真且多样化的异常样本,解决了视觉异常检测中异常样本稀缺的问题。
又一个现象级Agent产品?今天突然火起来的Lovart,我们也测上了

Lovart 是全球首个设计 Agent,可以让人类和 AI 在同一张画布上协作创作。它提供了丰富的功能来生成符合需求的视觉效果,并支持多城市主题插画的制作。
ICLR 2025 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得

本文介绍了一种基于生成流网络的扩散模型奖励微调方法Nabla-GFlowNet,该方法能够在快速收敛的同时保持生成样本的多样性和先验特性。通过在Stable Diffusion上实验验证了其有效性。
Midjourney推出AI图片生成模型 V7了

Midjourney推出的新版V7注重图像的真实感提升,并在细节真实性、场景理解及专业拍摄风格适配方面进行了优化。但个性化创作受限于数据学习和用户满意度提高有限问题。同时,新增的草图模式提升了生成速度,但也带来了一些质量上的挑战。
AI Toolkit 是专注Stable Diffusion模型训练的开源工具包
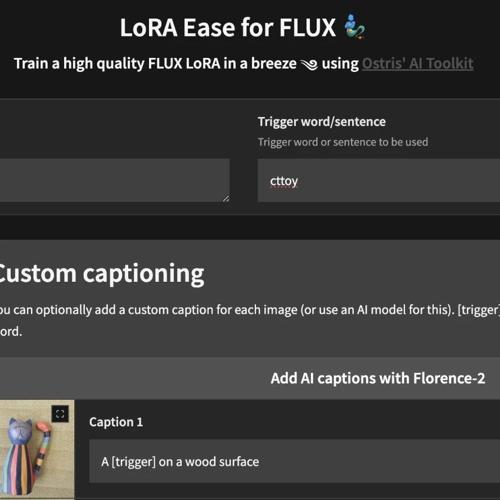
AI Toolkit 是一款开源工具包,专注于Stable Diffusion模型训练,提供优化的训练脚本、FLUX.1训练方案、多平台支持以及可视化操作界面等特性。

