

极市导读
本文介绍了一种名为AnomalyAny的创新框架,它利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像等领域提供了新的解决方案。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
在工业质检、医疗影像等领域,视觉异常检测(Visual Anomaly Detection, AD)是保障质量与安全的关键技术。然而,异常样本稀缺一直是制约其发展的核心难题 —— 现实中,异常现象往往罕见且难以收集,传统方法要么依赖大量正常数据 “脑补” 异常,要么生成的伪异常缺乏真实感,导致检测模型性能受限。
近日,瑞士洛桑联邦理工学院(EPFL)与华中科技大学的研究团队联合提出AnomalyAny 框架已被CVPR2025录用,利用开源文本生成图像模型Stable Diffusion(SD)的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真、多样且从未见过的异常样本,为数据稀缺场景下的异常检测提供了全新解决方案。

论文链接:
https://arxiv.org/abs/2406.01078v3
代码与 Demo 地址:
https://hansunhayden.github.io/AnomalyAny.github.io/
一、核心挑战:传统方法的 “数据困局”
现有异常生成方法主要面临两大痛点:
1. 真实性不足:
如图1(a)所示,早期方法通过 “裁剪 – 粘贴” 随机图案(如自然纹理)生成异常,虽无需训练,但生成的异常与真实场景差异显著,难以被检测模型有效识别。
2. 依赖大量数据:
如图1(b)所示,基于生成模型(如 GAN、扩散模型)的方法虽能生成更真实的样本,但需要大量正常和异常数据进行训练,这在异常罕见的场景中(如精密零件缺陷)几乎不可行。
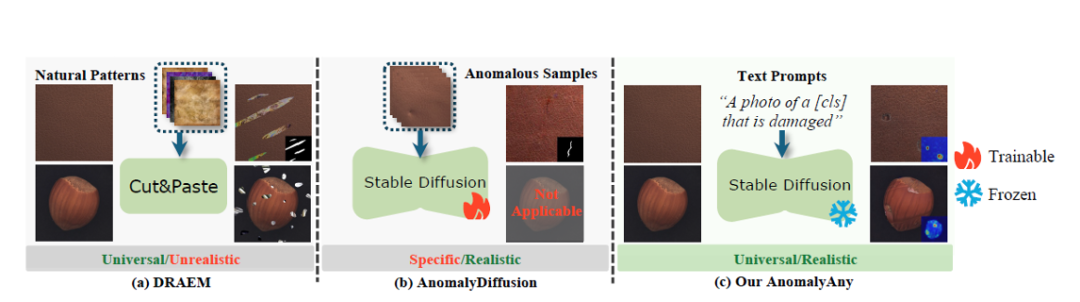
AnomalyAny 的突破点在于:无需任何训练数据,直接利用预训练的 Stable Diffusion 模型,通过巧妙的引导机制,让模型 “理解” 正常样本的特征,并根据文本描述生成符合逻辑的异常。
二、AnomalyAny:如何让 AI “创造” 从未见过的异常?
如图2所示,AnomalyAny 框架包含三大核心模块,环环相扣实现精准异常生成:
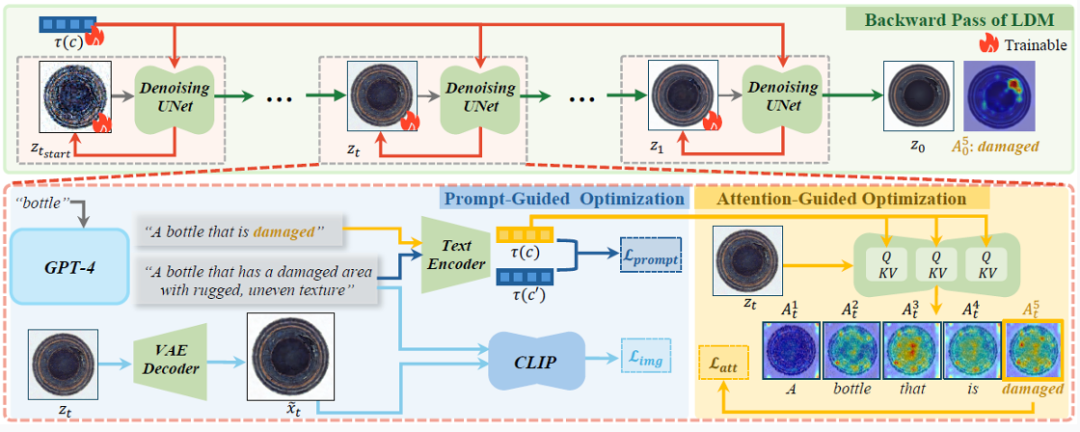
1. 测试时正常样本引导(Test-time Normal Sample Conditioning)
传统 SD 模型生成的图像可能偏离目标数据集的 “正常分布”(如图3(b))。AnomalyAny 通过在推理阶段引入单个正常样本的潜在特征,从噪声生成过程的中间步骤(而非完全随机起点)开始,确保生成的异常样本与正常样本共享相同的背景、光照等全局特征,避免 “画风突变”。
举个例子:若输入一张正常的 “瓶子” 图片,模型会以该瓶子的形状、材质为基础,在其基础上 “改造” 出破损、裂痕等异常,而非生成一个完全不同的物体。

2. 注意力引导异常优化(Attention-Guided Anomaly Optimization)
由于 SD 的训练数据中异常样本较少,模型容易忽略文本描述中的异常关键词(如 “破损”)。AnomalyAny 通过最大化异常关键词的注意力权重,迫使模型聚焦于生成目标异常区域。具体而言,通过分析 SD 的交叉注意力图(Cross-Attention Maps),找到与 “破损”“裂痕” 等关键词对应的图像区域,并通过反向传播优化潜变量,确保异常特征被显著表达。
可视化结果:如图3(d)-(f) 所示,移除注意力引导后,生成的异常区域模糊不清;而启用该机制后,异常特征(如瓶盖的裂痕)清晰可辨。
3. 提示引导异常细化(Prompt-Guided Anomaly Refinement)
为进一步提升生成质量,AnomalyAny 利用GPT-4 自动生成详细异常描述(如将 “破损” 细化为 “带有粗糙不平纹理的破损区域”),并通过 CLIP 模型计算生成图像与文本的语义相似度,强制两者对齐。这一过程不仅增加了异常的多样性(如不同类型的划痕),还能生成符合工业标准的复杂缺陷(如 “锯齿状裂缝”)。
三、实验验证:生成质量与检测性能双提升
在工业异常检测基准数据集MVTec AD和VisA上,AnomalyAny 展现出显著优势:
1. 生成质量:真实感与多样性兼具
• Inception Score(IS) 衡量生成图像的真实性,AnomalyAny 在多数类别中得分最高(如 bottle 类别 IS=1.73,远超基线方法),表明其生成的异常样本更接近真实图像。
• Intra-cluster LPIPS 距离(IC-LPIPS) 衡量多样性,AnomalyAny 生成的异常样本差异更大(如 cable 类别 IC-LPIPS=0.41),为检测模型提供了更丰富的训练信号。
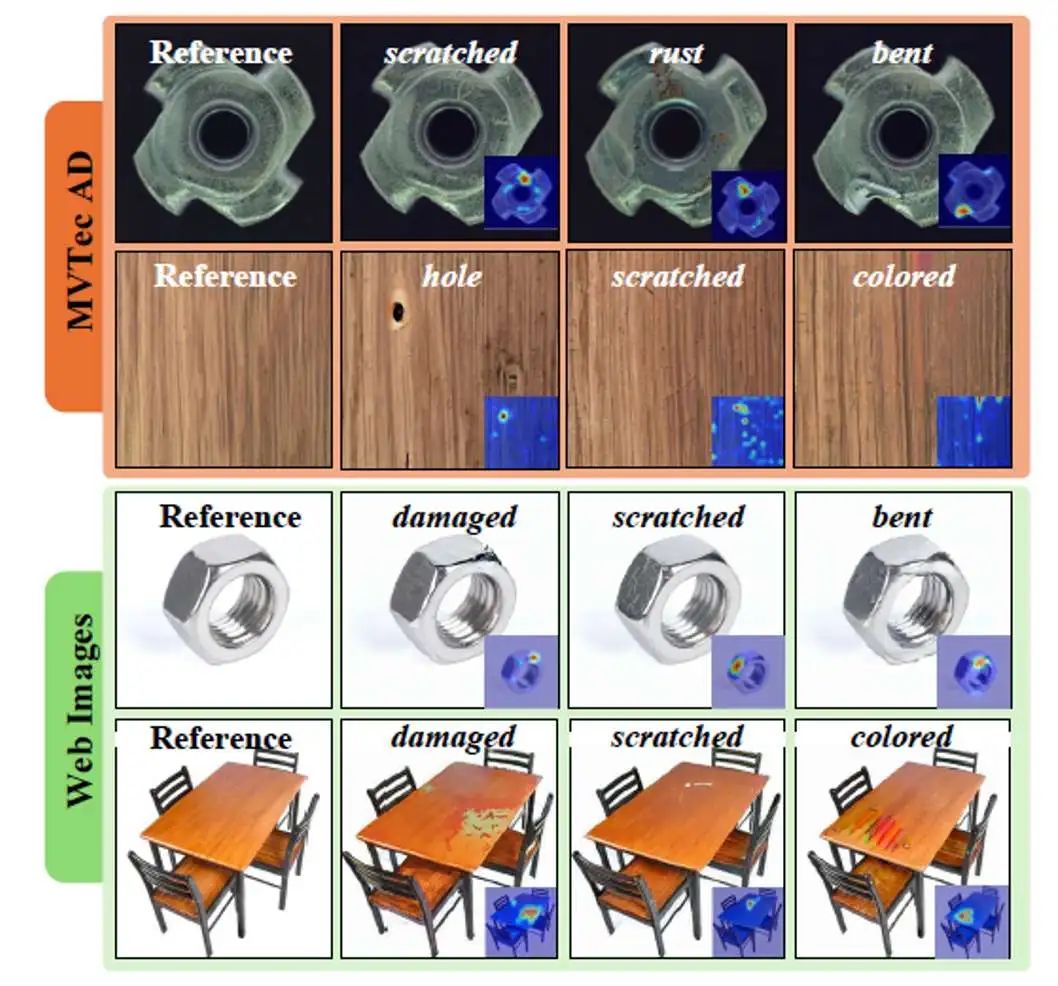
图4展示了在MVTec AD以及Web图片中生成的异常效果。
2. 下游检测性能:小数据下的卓越表现
如表1所示,在1-shot 检测场景(仅用 1 张正常样本训练)中,使用 AnomalyAny 生成的样本训练的模型,在 MVTec AD 上达到图像级 AUC=94.9%、像素级 AUC=95.4%,超越了 PatchCore、WinCLIP + 等主流方法。即使与需要部分异常数据训练的 AnomalyDiffusion 相比,AnomalyAny 仍实现了 comparable 性能,且无需担心数据泄漏问题。

四、未来展望:开启 “零样本” 异常检测新范式
AnomalyAny 的创新之处在于将预训练多模态模型(SD+GPT-4)与领域知识结合,无需任何训练即可生成定制化异常样本。这一特性使其在以下场景具有广阔应用前景:
-
工业质检:快速生成各类零件的虚拟缺陷,减少人工标注成本; -
医疗影像:模拟罕见病变,辅助训练肿瘤检测模型; -
自动驾驶:生成极端天气、道路异常等边缘场景,提升模型鲁棒性。
当然,当前方法仍依赖文本提示的准确性,未来若结合单样本异常图像输入,有望进一步提升复杂异常的生成精度。随着大模型技术的发展,类似 AnomalyAny 的 “提示式” 解决方案或将成为解决数据稀缺问题的通用范式。
(文:极市干货)