


近年来,GPT 等大型语言模型在问答、搜索、医疗等任务中大放异彩,但一个顽疾始终存在——幻觉(hallucination),即模型自信输出却偏离事实。为缓解幻觉,学界提出了 RAG(Retrieval-Augmented Generation) 框架,通过引入外部资料来辅助生成,试图减少“胡编乱造”。
但现实真如我们所愿?港理工与四川大学研究团队发现:RAG 本身也可能引入偏差,甚至造成“幻觉叠加”(Hallucination on Hallucination)。
为此,团队提出新框架——DRAG(Debate-Augmented RAG),通过引入多智能体辩论机制,在“找资料”和“写答案”的每一个环节中层层把关,提升答案的真实性与可靠性。

论文标题:
Removal of Hallucination on Hallucination: Debate-Augmented RAG
论文链接:
https://arxiv.org/abs/2505.18581
代码链接:
https://github.com/Huenao/Debate-Augmented-RAG
收录会议:
ACL 2025 Main

研究背景:RAG 中的幻觉叠加
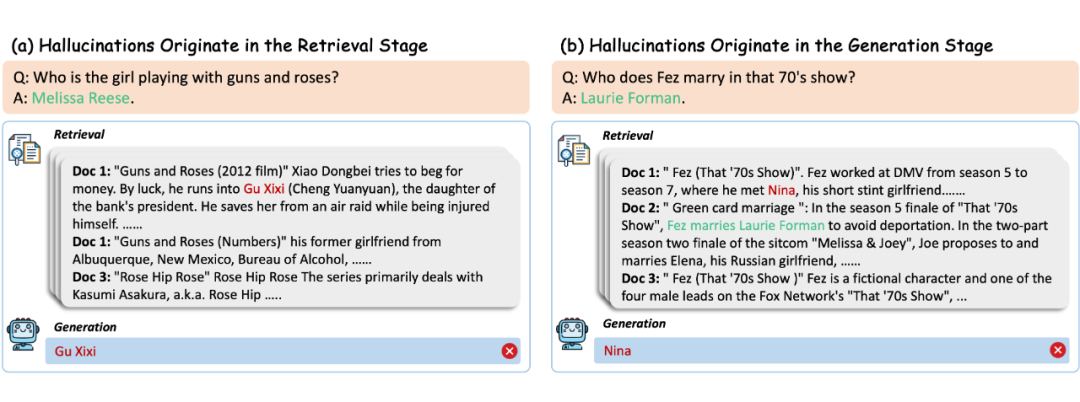
为了解决生成式 AI 中的幻觉问题,RAG 框架通过“先查资料再说话”的方式增强生成结果的事实性。但现实很骨感:如果查到的资料本身就错了呢?
举个栗子:
问题 “Guns N’ Roses 的女键盘手是谁?”
RAG 检索到的是电影《Guns and Roses》的剧情,然后模型信誓旦旦地回答:“Gu Xixi”。
这不是救火,而是浇油。
此外,即便资料查得没问题,模型也可能挑错重点、曲解信息甚至编造内容。
本文将这种“幻觉叠加”现象,归因为 RAG 系统在两个阶段的问题所致:
-
检索阶段:若检索不充分或存在偏差,就会为后续生成埋下“认知陷阱”;
-
生成阶段:模型仍可能因噪声干扰或对上下文的误解,输出与事实不符的答案。

破局之道:让模型「辩」起来
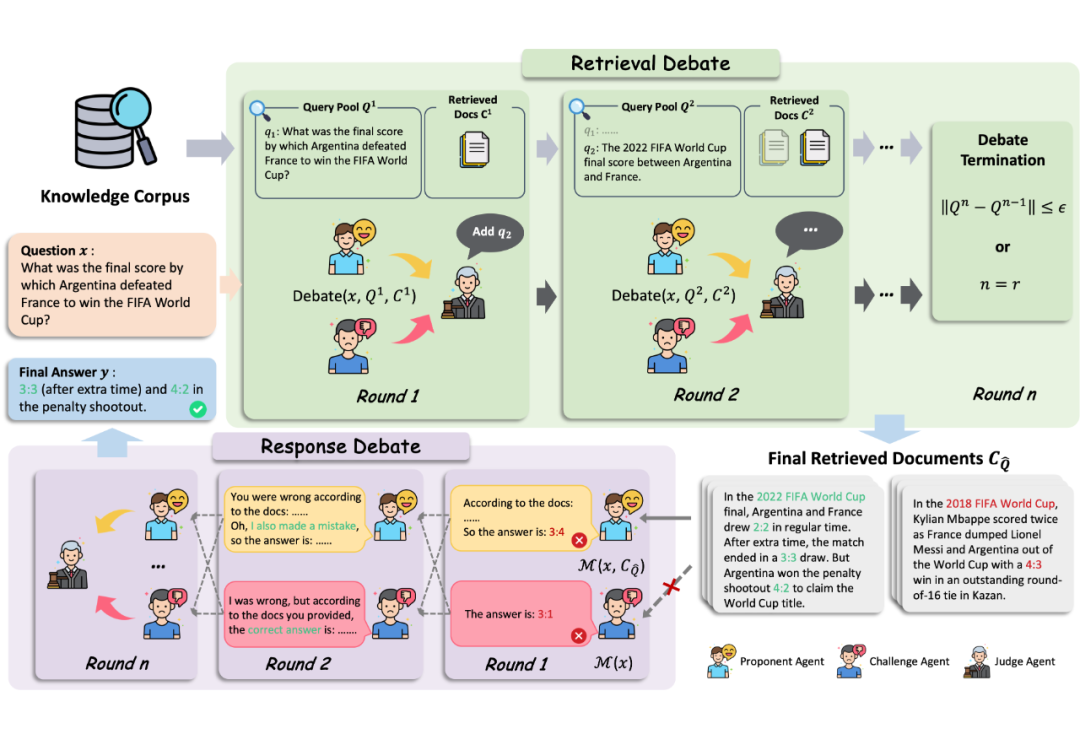
DRAG 的核心思想是借助多智能体辩论机制(Multi-Agent Debate, MAD),在信息检索和答案生成阶段都引入“正反方辩论 + 法官裁决”的机制,模拟一个“查找事实 + 互相质疑 + 集体评估”的 AI 辩论法庭,让最终输出更准确、更有理有据。
1. 阶段1:检索环节也能“据理力争”
传统 RAG 在检索是“一问一搜”的模式,模型根据问题发起一次查询,然后就拿着这份资料去回答。但如果查询关键词不够精准,或者只检索到了片面的内容,模型自然会“从错的信息里找答案”。
为此,DRAG 在检索阶段引入了“多智能体辩论机制”,相当于让多个智能体一起开会“讨论怎么查资料最靠谱”。
具体来说,每轮检索都由三类智能体参与构成:
-
支持方(Proponent Agent):主张“现在的检索策略挺好,不用改”;
-
反对方(Challenger Agent):认为“查得不够准”,并提出优化建议,如换关键词、拓展查询;
-
裁判方(Judge Agent):对比双方观点,决定下一轮要不要调整查询策略。
2. 阶段2: 生成环节进行“对线式推理”
即便有了好资料,模型仍可能答非所问,尤其当信息冲突或推理链较长时。
DRAG 引入的第二大机制是:让 AI 在生成阶段进行“对线式推理”。此外,为了避免模型不加怀疑地信任有偏差的检索信息,本文设计了信息不对等机制,即使用两个信息源不对等的智能体进行互相“辩论”
-
支持方(Proponent Agent):依赖检索到的资料来作答;
-
反对方(Challenger Agent):完全不看资料,仅靠自己的知识作答;
-
裁判方(Judge Agent):综合两者的回答,从中挑出事实更准确、逻辑更严密的版本。

实验表现:表现稳定,多跳更强
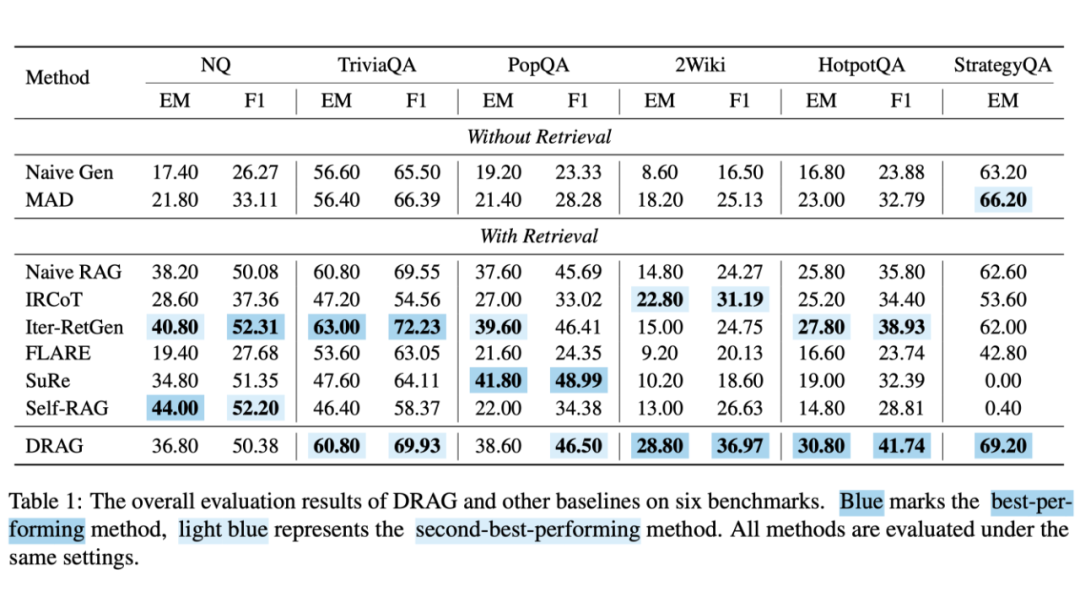
本文在六个 QA 数据集上对 DRAG 进行了全面评估,包括开放问答(TriviaQA、NQ、PopQA),多跳问答(2WikiMultihopQA、HotpotQA)以及常识推理(StrategyQA)。
实验结果如表 1 所示,DRAG 在多跳推理任务上 在多跳推理任务中取得了强劲的表现,在单跳任务中也同样具有竞争力。
此外,本文对检索辩论和生成辩论阶段分别进行更加细致的分析:
-
表 3 统计了 DRAG 在不同任务中的平均辩论轮数和查询次数,表明 DRAG 可动态调整检索策略以适应任务的复杂性。
-
表 4 探究了 DRAG 在检索不到正确资料的情况下有生成辩论与否的表现,表明生成辩论增强了对检索缺陷的鲁棒性。
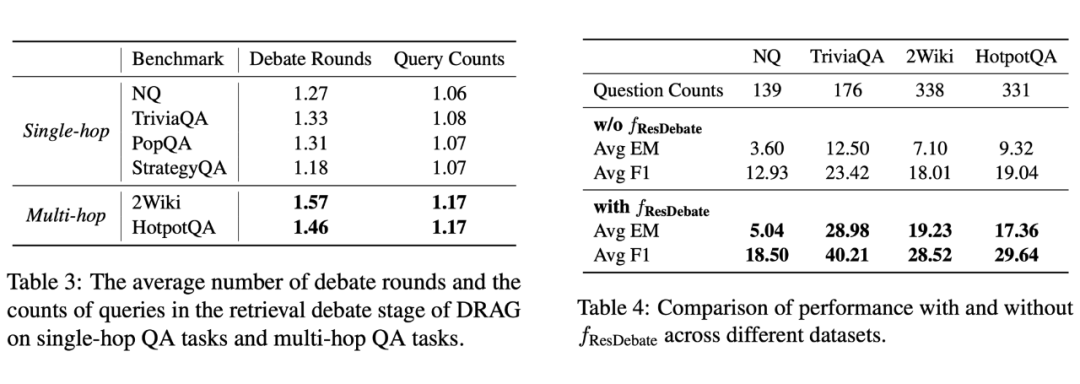
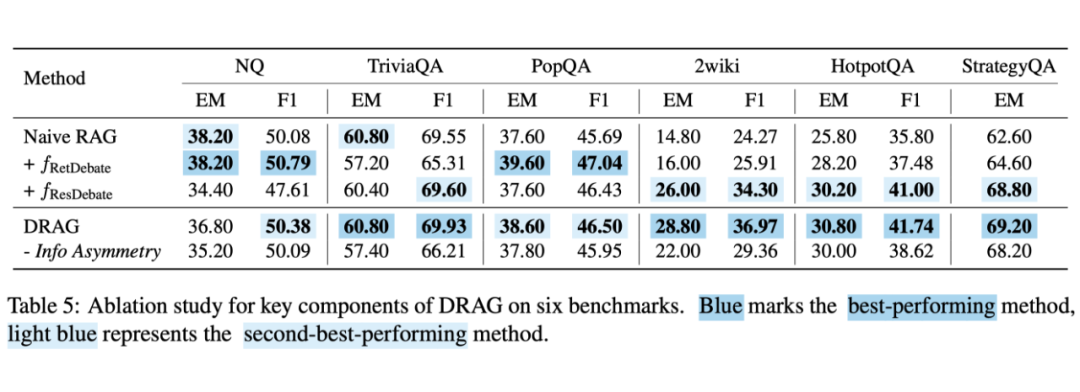
表 5 是对 DRAG 中的各个模块的消融实验,表明 DRAG 两大阶段缺一不可,此外信息不对称设定对于防止代理过度依赖检索到的内容并促进事实一致性具有重要作用。
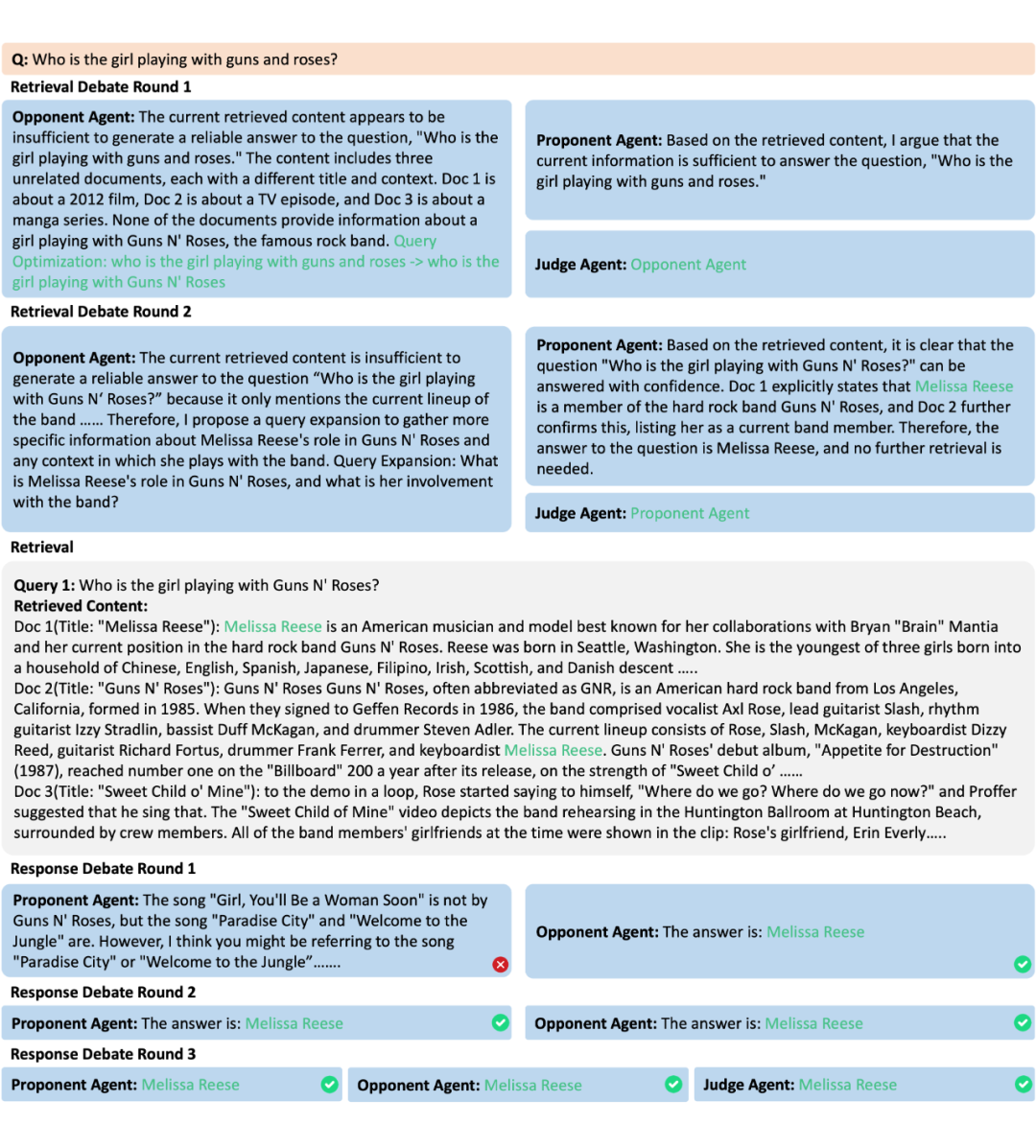
以下是 DRAG 的实例分析,可以看到检索辩论能有效排除错误的检索目标引导系统制定更准确的检索策略。

结论与展望
DRAG 以“多代理辩论”的创新方式对 RAG 框架在检索与生成两个阶段进行优化,有效缓解了幻觉叠加的问题。在多跳问答、开放领域问答等任务中均取得了领先表现,验证了该方法的通用性与有效性。
但 DRAG 同样也有一定的局限,在简单单跳任务中,DRAG 可能因“过度辩论”引发问题漂移,因此未来可探索自适应停止策略,提升性价比。
(文:PaperWeekly)