



-
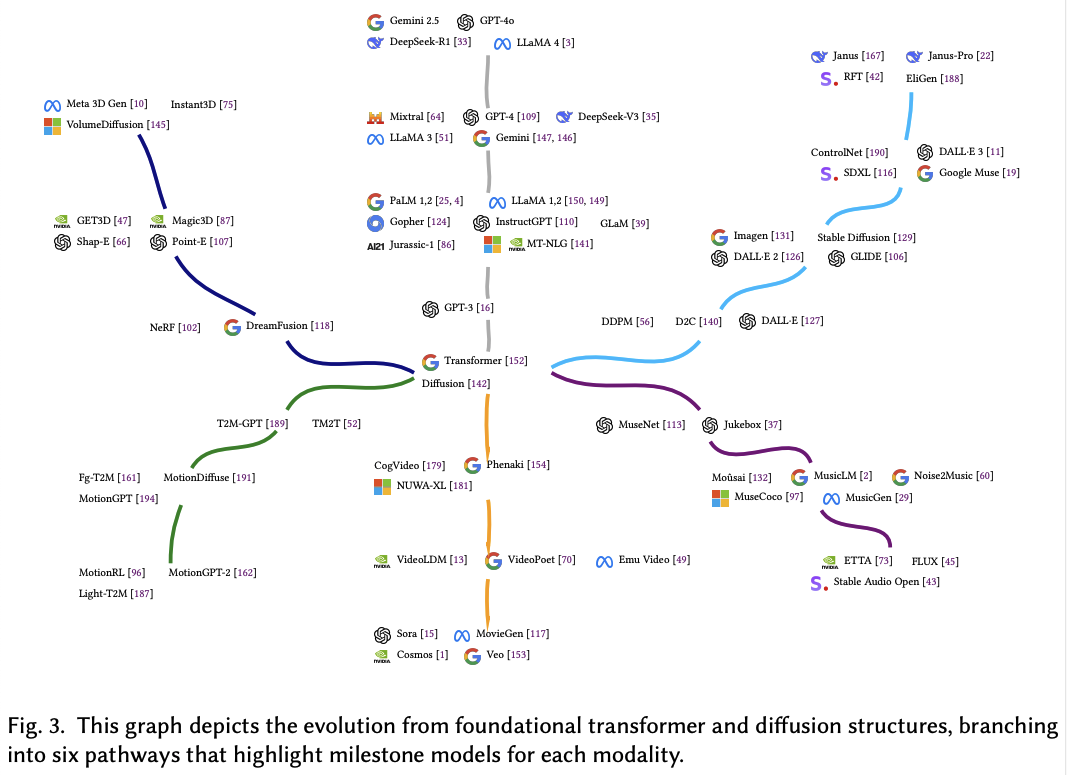
文本到图像(T2I):DALL·E系列、Imagen和Stable Diffusion等模型通过大规模图像-文本对数据集训练,利用SSL技术从无标签图像数据中学习,提高了图像生成的质量和多样性。
-
文本到音乐(T2M):Moûsai、MusicLM和Noise2Music等模型利用扩散模型和自监督学习,从大规模音乐数据中学习音乐结构和模式,生成高质量的音乐。
-
文本到视频(T2V):CogVideo、Make-A-Video和Phenaki等模型通过结合Transformer架构和扩散模型,实现了高质量视频生成,同时解决了数据集限制和计算成本问题。
-
文本到人类动作(T2HM):TEMOS、T2M-GPT和MotionDiffuse等模型通过概率生成方法和扩散模型,生成与文本描述相匹配的人类动作序列。
-
文本到3D对象(T2-3D):DreamFusion、Magic3D和Shap-E等模型通过优化神经辐射场(NeRF)和扩散模型,从文本描述生成高质量的3D对象。
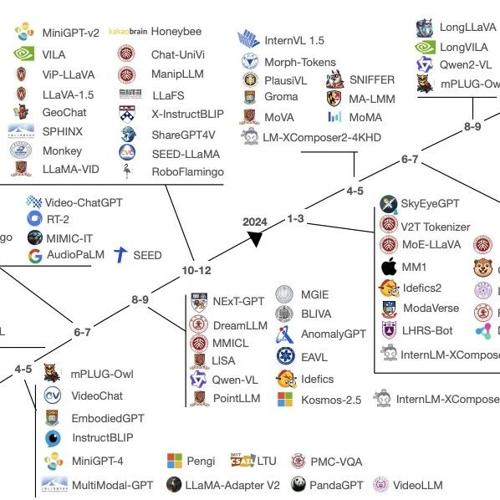
第二篇论文则聚焦于MLLMs的融合策略和技术。提出了一个以大型语言模型(LLM)为中心的分析框架,从架构策略、表示学习技术和训练范式三个关键维度对MLLMs进行分类。

在架构策略方面,详细分析了抽象层、投影层、语义嵌入层和交叉注意力层等机制,这些机制使得非文本模态能够与LLMs有效集成。例如,抽象层通过控制特征的token数量,减少了模型的计算成本;而交叉注意力层则允许模型动态关注非文本特征,实现更精细的模态融合。
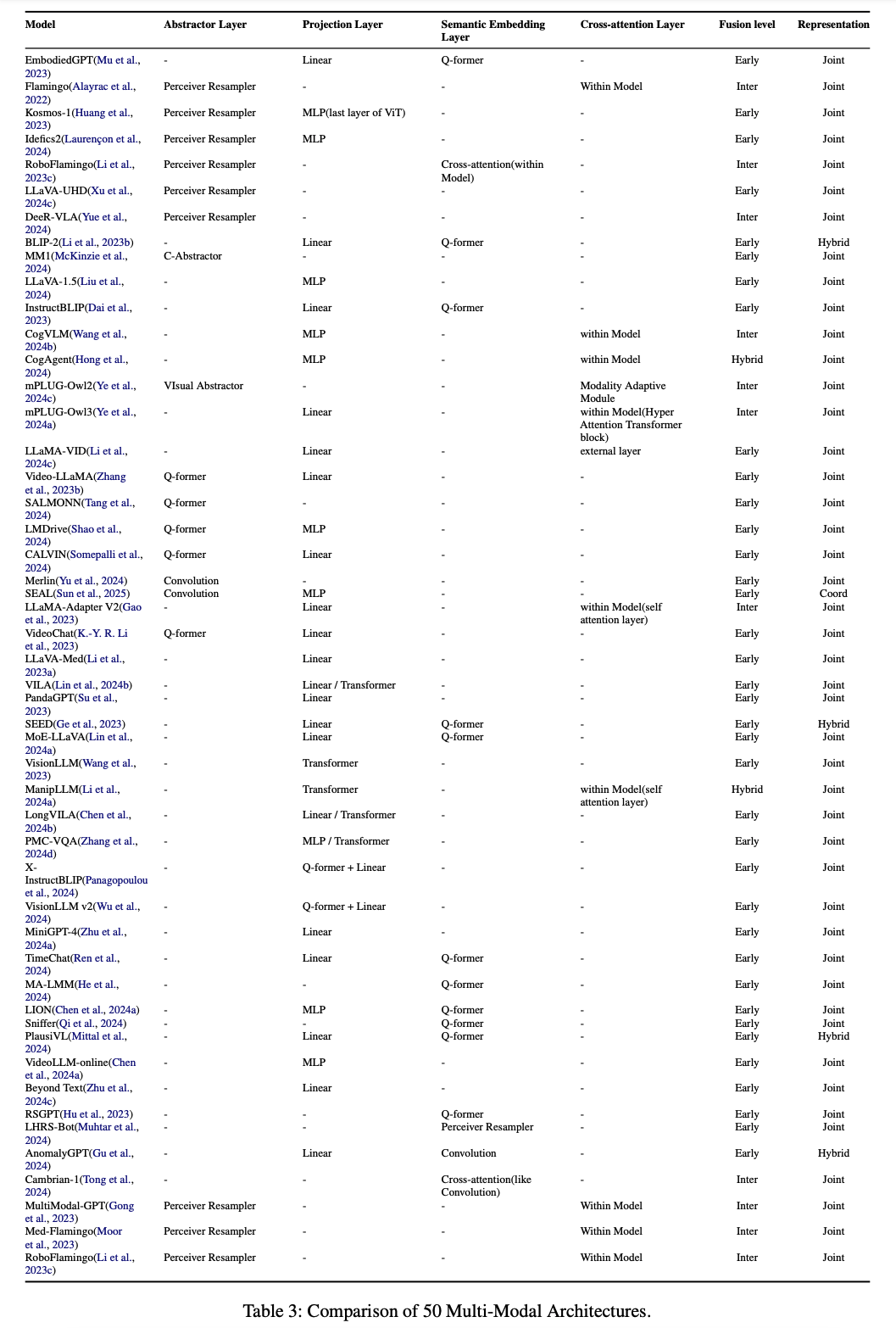
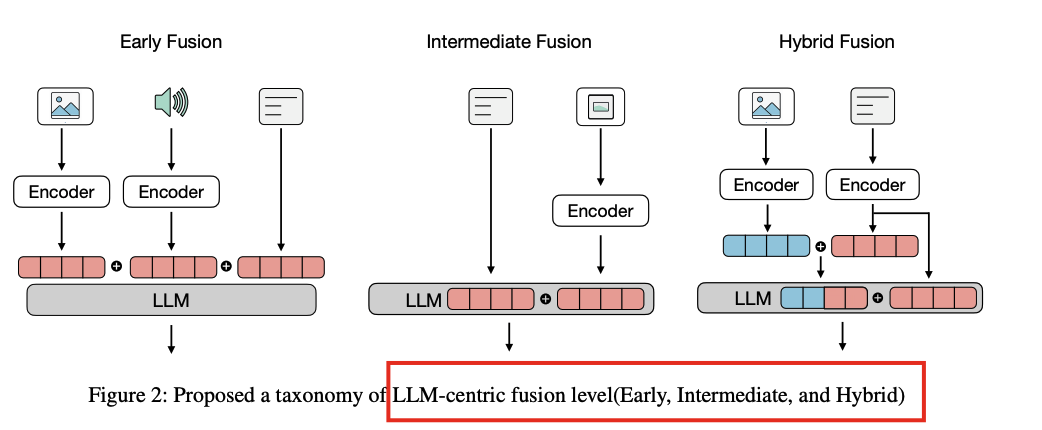
在表示学习技术上,将MLLMs分为联合表示、协调表示和混合表示三种方式。联合表示通过将所有模态的特征合并到一个共享空间中,实现细粒度的融合;协调表示则通过对比学习对齐不同模态的输出,适合快速检索和零样本转移;混合表示则结合了两者的优点,既保持了检索效率,又实现了详细的多模态融合。
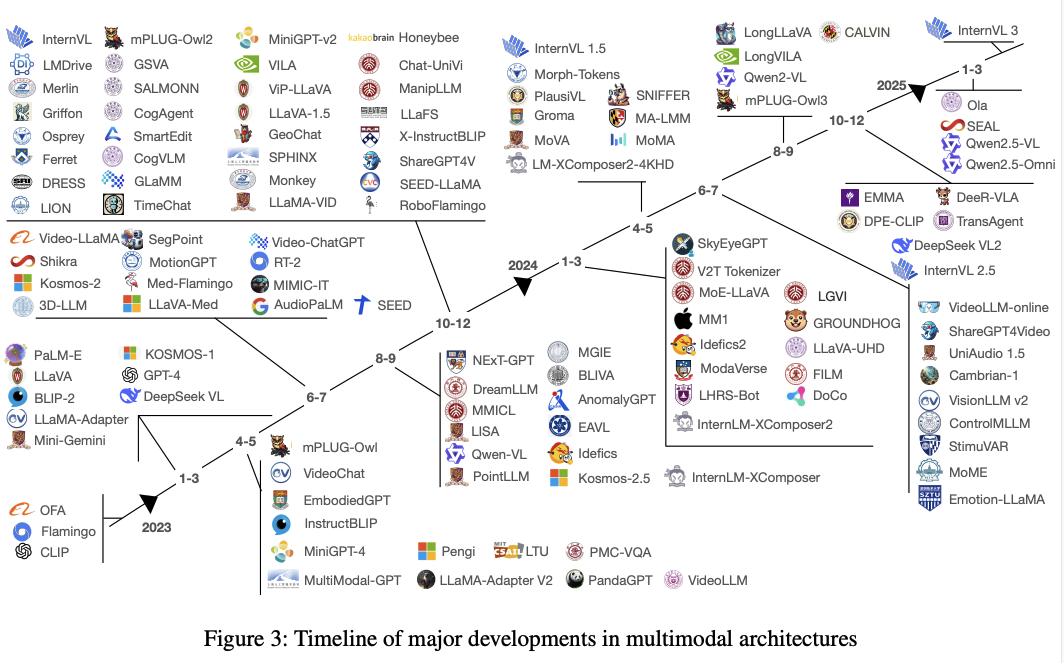
通过对125个MLLMs的分析,得出以下关键结论:
-
架构策略:不同的MLLMs采用了多种机制来将非文本模态与LLMs集成,这些机制可以根据研究者的意图在不同的上下文中发挥不同的功能。
-
表示学习技术:MLLMs在表示学习上主要采用联合表示、协调表示和混合表示三种方式,每种方式都有其优势和局限性。
-
训练范式:MLLMs的训练过程可以分为单阶段、两阶段或多阶段,不同的训练阶段和目标函数对模型性能有显著影响。
https://arxiv.org/abs/2506.10016A Survey of Generative Categories and Techniques in Multimodal Large Language Modelshttps://arxiv.org/pdf/2506.04788Towards LLM-Centric Multimodal Fusion: A Survey on Integration Strategies and Techniques
(文:PaperAgent)