


数学证明不仅要得出 “对” 的答案,更要给出逻辑闭合、层层严谨的推理过程。在不等式问题中尤其如此 —— 哪怕最终答案是对的,只要中间某一步出现纰漏,整个证明就可能不成立。我们不禁提问:这些答案是模型通过严密推理得出的,还是只是通过 “看起来合理” 的过程猜出来的?
不等式问题正是检验这一点的理想对象:它们结构清晰、逻辑对象简单,在数学竞赛与应用数学中都极为常见,同时具备较长的推理链条,能够有效揭示推理中的漏洞或模糊之处。
这正是当前形式化数学所试图解决的问题。近年来,Lean、Coq 等系统为数学提供了严格可验证的推理机制,每一步推导都必须符合逻辑规则,可被计算机检验。然而,这类系统对语句的表达精度要求极高,建模成本大、自动化程度有限,尤其在面对中学到奥数级别的不等式问题时,很难做到规模化应用。

使用 Lean 进行形式化证明的过程
另一方面,当前主流的大语言模型是在海量自然语言上训练出来的。它们虽然无法直接生成可被形式系统接受的机器检查证明,却在 “非形式化推理” 方面表现出色 —— 也就是说,它们往往能给出看似合理、直觉对路的答案,并模仿人类在解决问题初期的思维方式。这种能力虽然不符合传统意义上的形式证明要求,但在探索性的数学过程中具有重要价值。
为此,斯坦福大学、加州大学伯克利分校与麻省理工学院的研究团队提出了一种创新方法:将不等式证明任务拆解为两个 “非形式化但可验证” 的子任务,即 “界限估计” 和 “关系预测”,并基于此构建了第一个奥林匹克级不等式证明基准数据集 ——IneqMath。这一框架提供了一种介于完全形式化验证与自然语言生成之间的 “中间层”,可以逐步审查模型的推理链条,从而判断其是否真正掌握了推理结构,而不仅仅是在猜测答案。
-
完整项目主页:🌐 https://ineqmath.github.io
-
📜 论文:https://arxiv.org/abs/2506.07927
-
🛠️ 代码库:https://github.com/lupantech/ineqmath
-
📊 数据集:https://huggingface.co/datasets/AI4Math/IneqMath
-
🏆 排行榜:https://huggingface.co/spaces/AI4Math/IneqMath-Leaderboard
-
🔍 数据集可视化展示:https://ineqmath.github.io/#visualization
-
𝕏 推特:https://x.com/lupantech/status/1932866286427779586
本项目并非试图替代形式化系统,而是希望补足当前 LLM 推理评估的盲区 —— 在不依赖形式逻辑表达的前提下,仍然能对模型的推理严谨性进行系统、自动的检验,以更贴近人类思维的方式,衡量它们是否具备构造完整数学证明的潜力。
🔍 如何 “非形式化” 地评估不等式证明?
论文核心思路是:将不等式证明过程拆解为以下两种子任务:界限估计与关系预测。
对于同一道数学证明题目: 对于任意非负实数 a,b,请证明 a+b≥2√ab
两种任务分别把证明问题改写成了不同的形式:
1️⃣ Bound Estimation(界限估计)
对于任意非负实数 a,b,请判断两个式子的关系:a+b?2√ab
2️⃣ Relation Prediction(关系预测)
对于任意非负实数 a,b,请求出最大的常数 C 使得a+b≥C√ab恒成立。
这两类任务都可以用自然语言和 LaTeX 表达,适合大模型按步骤求解,同时保留了不等式证明中的创造性核心,避免了形式化证明工具带来的复杂负担。并且每道题目有唯一的正确答案,方便验证结果的正确性。
📘 IneqMath:首个非形式化但可验证的不等式证明数据集
研究团队基于上述任务结构,构建了 IneqMath 数据集,覆盖训练、测试与验证三部分:
-
训练集:包含 1,252 道不等式题目,配有分步证明和定理标签(共包含 83 种定理,如均值不等式、Chebyshev 不等式等,以及 29 个定理类别),适用于模型微调。
-
测试集:共 200 道题目,由国际数学奥林匹克(IMO)奖牌得主手工设计、资深数学家审核,强调复杂策略组合与逻辑链深度。
-
验证集:共 100 道题目,题型与测试集保持一致,主要用于调参和中期评估。
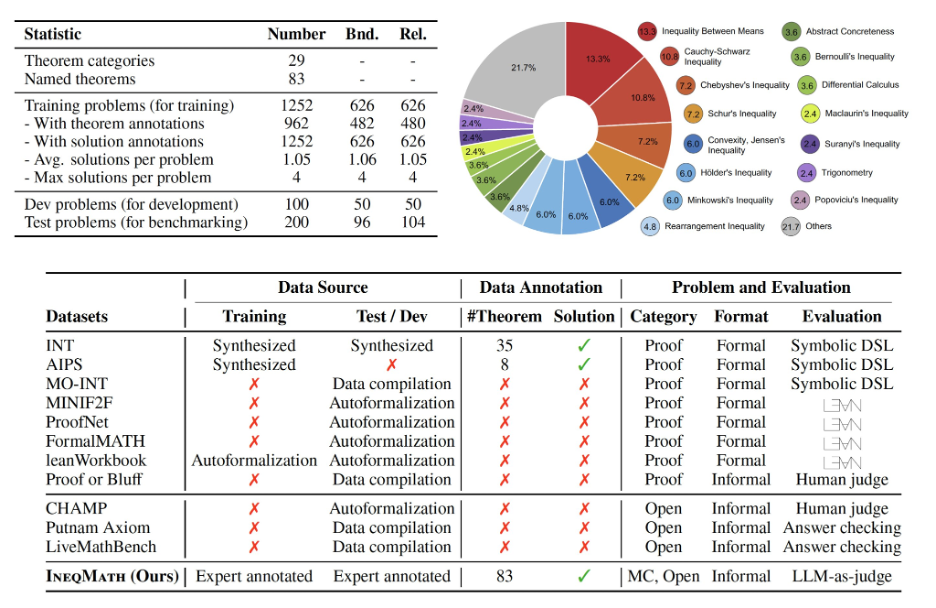
以下是 IneqMath 的训练和测试题目示例:


🧠 如何评估 LLM 的推理严谨性?
团队开发了一套由五种 “自动评审器” 组成的 LLM-as-Judge 框架,可以逐步分析语言模型的解题过程是否符合逻辑严谨性:
-
Final Answer Judge(最终答案是否正确)
-
Toy Case Judge(是否用特殊值推断出一般的结论,忽略了泛化过程. )
例如,如果只通过代入 a = 1, b = 2 来得出对任何非负实数 a, b 都成立 a+b≥2√ab 的结论就是在用特殊值推断出一般的结论。
-
Logical Gap Judge(是否存在跳步、未解释的等价变形等逻辑偏差)
例如,对于一个复杂的函数 f (x),直接说明 “经过复杂的数值计算我们知道 f (x) 的最小值在 x=1 取到 “但是没有给出具体的最小值求解过程的就属于逻辑偏差的一种,因为他跳过了关键的步骤。
-
Numerical Approximation Judge(是否存在不当近似)
例如,若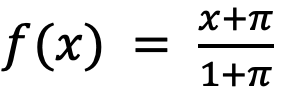 ,但是后续的证明中全部把 f (x) 近似
,但是后续的证明中全部把 f (x) 近似 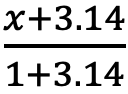 的行为就属于不当近似。
的行为就属于不当近似。
-
Numerical Computation Judge(计算是否正确,包括基本代数运算或代入过程中的数值错误)
例如,把 23×76(应该等于 1541)计算成了 1641 就属于一种计算错误。
通过这套系统,研究者可以判断一个模型是否只是 “碰巧答对了”,还是在每一个推理节点上都做对了。
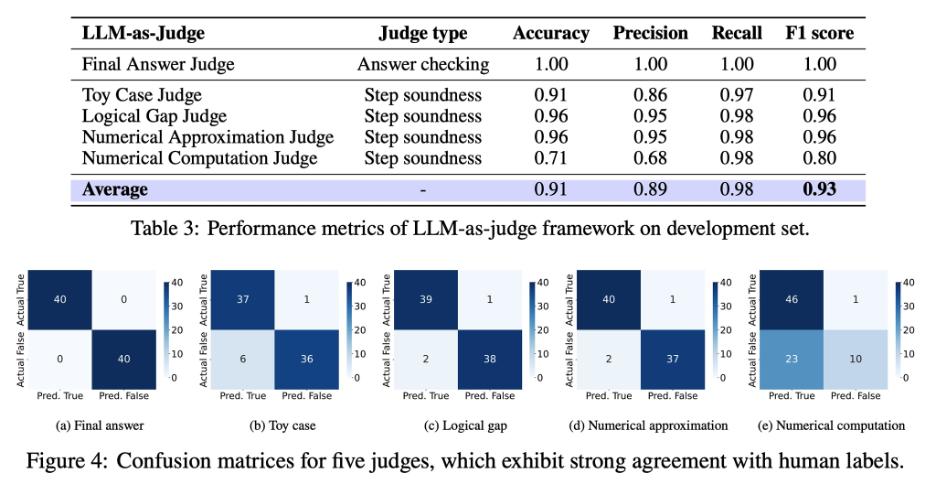
同时这些评审器在准确性上表现出与人类标注高度一致。如下图所示,评审器系统在与人工标注对齐的任务上达到了 F1 = 0.93 的表现,证明了这一方法既可靠又具可扩展性,可有效替代大规模人工审阅。
⭐️ 实验结果
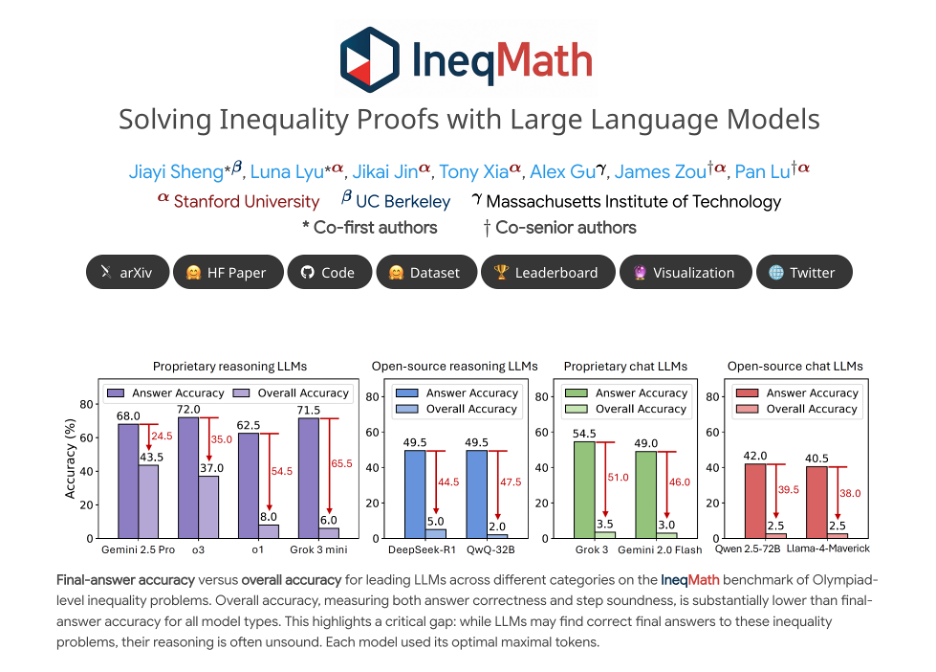
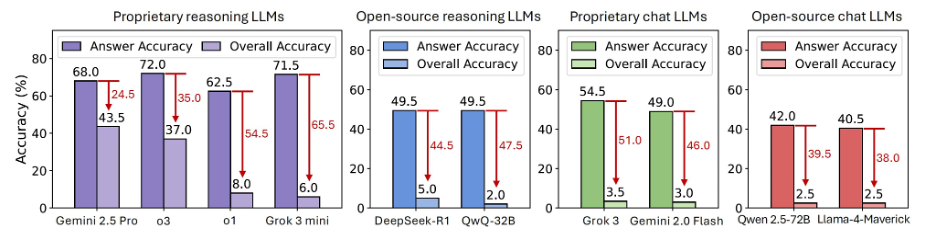
重磅发现一:Soundness Gap 是真实存在的!
研究测试了包括 GPT-4、Claude、Gemini、Grok、Mistral、LLaMA 等在内的 29 款主流 LLM,发现:
🔹 Grok 3 mini:最终答案准确率高达 71.5%,但经逐步评审后骤降至 6.0%!
🔹 所有模型准确率下降幅度最多达 65.5%
🔹 开源推理模型:最佳也仅达 6% 准确率
🔹 聊天型大模型(chat LLMs):整体准确率低于 5%
研究者指出,这意味着当前 LLM “猜得准但推不全”,逻辑链条存在 “虚假自洽” 的陷阱。
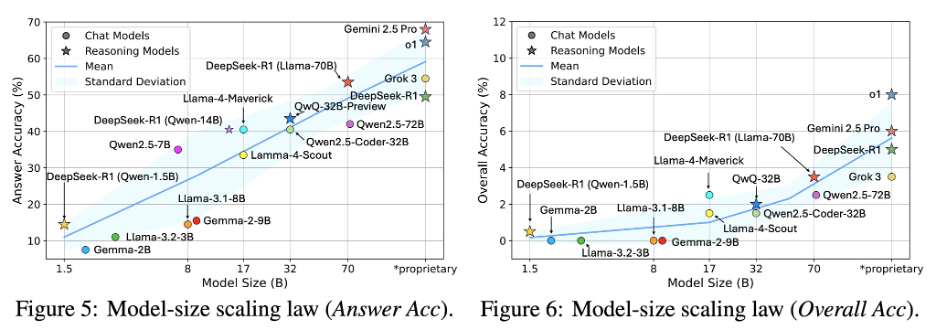
重磅发现二: 模型越大 = 推理越好吗?未必!
实验发现,大语言模型在 “最终答案准确率” 上确实会随着模型规模提升而稳步增长,说明大模型在 “猜对答案” 这件事上确实更厉害了。但一旦我们开始评估推理过程是否严谨,情况就没那么乐观了:随着模型变大,“整体推理正确率” 提升有限、甚至不再提升。这意味着:更大的模型并不能自动学会更严谨的逻辑链条。换句话说,LLM 可以越猜越准,但证明过程还远谈不上靠谱。仅靠堆参数,解决不了推理的本质问题。
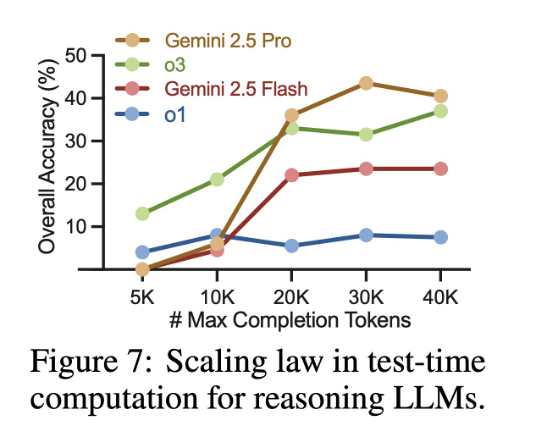
重磅发现三:多算≠更严谨
研究团队通过增加推理 token 数让大模型在解题时 “想得更久”。结果发现:推理链更长,只带来轻微提升,且很快进入饱和状态 。换句话说,计算多了,推理依然不严谨。对复杂数学证明来说,“多想” 远不如 “想对”。
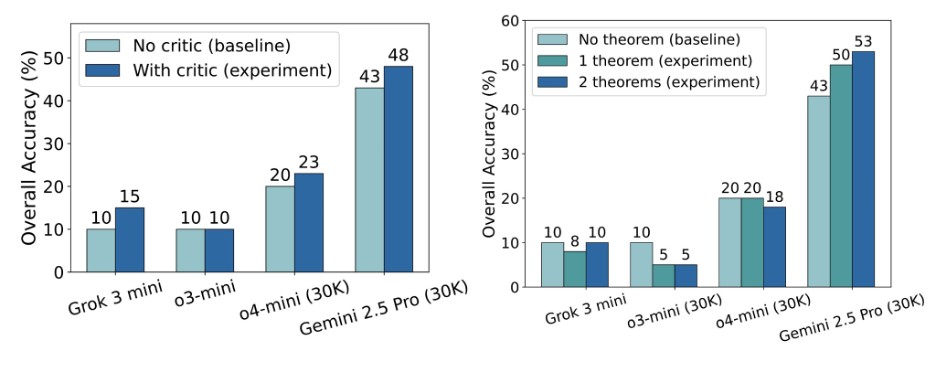
✨ 曙光初现:批判增强与定理提示可带来性能提升
尽管当前模型在逻辑严谨性上的表现仍不理想,扩大模型规模或延长推理过程也难以显著提升推理质量,但研究团队仍发现了一些确实有效的改进策略:
-
自我批判提升(Self-improvement via critic):自我评判自己的作答,评判后重新对答案进行修改。📈 该策略为 Gemini 2.5 Pro 带来约 5% 的提升。
-
定理提示(Theorem Augmentation):通过自动检索相关定理并作为提示提供给模型,帮助其在关键步骤做出更合理的推理选择。📈 Gemini 2.5 Pro 在这一策略下准确率提升约 10%。
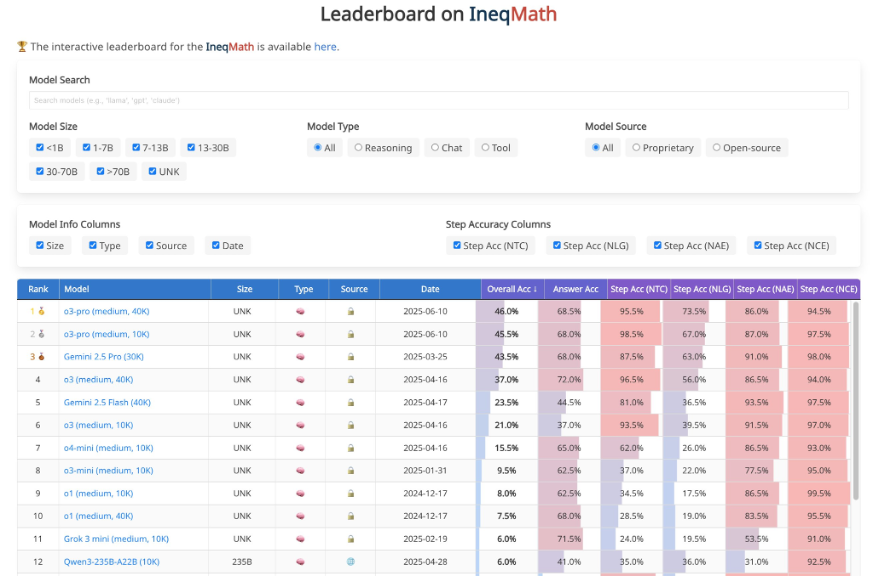
🏅 欢迎参与 IneqMath 排行榜挑战!
为了推动模型在严谨数学推理上的进步,研究团队特别设立了一个 动态更新的排行榜,供研究者与开发者提交自己的模型结果。该平台支持自动评估提交模型在 IneqMath 中的表现,涵盖最终答案准确率与推理过程严谨性,评价机制由 LLM-as-Judge 系统支撑,无需人工干预即可完成高质量判分。
研究团队诚挚邀请社区广泛参与 —— 无论是大型基础模型,还是你训练的小型创新模型,都可以提交来一试高下!
欢迎访问:🏆https://huggingface.co/spaces/AI4Math/IneqMath-Leaderboard 了解详情,并提交你的挑战结果!
结语
IneqMath 的研究表明,大语言模型虽能猜出不少正确答案,但在真正构造严谨数学证明时,仍存在结构性短板。无论是更大的模型,还是更长的 “思考过程”,都难以从根本上提升其逻辑闭合能力。
然而,曙光初现:通过定理提示与自我批判提升等方法,模型开始展现出 “学会推理” 的可能性。这意味着,真正可靠的数学 AI,不一定更大,但一定更会使用工具,更会自我反思。
大模型如今是优秀的猜测者,但还远不是可靠的证明者。那么 IneqMath 的目标,是推动它们成为能构造证明的真正 “数学思维体”。
让我们相信,这只是开始。
作者介绍
本项目由来自斯坦福大学、麻省理工学院(MIT)和加州大学伯克利分校的研究者联合完成。
本项目负责人 Pan Lu 是斯坦福大学的博士后研究员。他的研究涵盖大语言模型、智能体优化、数学与科学发现等方向,相关成果获 ICLR、NeurIPS 最具影响力论文奖,并曾获得 Amazon、Bloomberg、Qualcomm 等多项博士奖学金。
合作者 Alex Gu 是麻省理工学院(MIT)计算机科学博士生,师从 Armando Solar-Lezama 教授,研究方向为神经符号程序学习,聚焦编程与数学中的智能推理。他曾在 Meta AI、Jane Street、Pony.ai 等多家机构实习,并荣获 NSF GRFP 奖学金。
另一位合作者 Jikai Jin 是斯坦福大学计算与数学工程研究所(ICME)的博士生,研究兴趣跨越机器学习、统计学与运筹优化等多个领域,致力于为真实世界问题提供理论与实践兼具的解决方案。他本科毕业于北京大学数学科学学院。
©
(文:机器之心)