

UTU团队 发自 凹非寺
量子位 | 公众号 QbitAI
现有的语言大模型(LLMs)在复杂指令下的理解和执行能力仍需提升。
腾讯优图(UTU)研究团队提出一种系统性方法——激励推理(Incentivizing Reasoning ),来提升LLM处理复杂指令的能力。

结果显示,该方法能够有效提升大多数LLM进行复杂指令深度处理时的表现,并在1.5B参数的LLM上实现了11.74%的性能提升,表现可媲美8B参数的LLM。
背景:难处理复杂指令与约束条件
现有的大语言模型(LLMs)在遵循复杂指令时面临挑战,尤其当多重约束以并行、链式和分支结构组织时,LLMs难以厘清真正的指令与约束条件。
一个直观的解决方案是通过“思维链”(CoT)来普遍提升LLMs的指令跟随能力。
然而研究团队发现,原始的CoT由于其表层的推理模式,即仅仅是对指令的简单释义与重复,却对性能产生了负面影响。朴素的CoT未能剖析约束的组成部分,也无法识别不同层级类型和维度关系。
为此,研究团队提出了一种系统性方法,通过激励推理能力来提升LLM处理复杂指令的能力:首先,基于现有分类法对复杂指令进行分解,提出了一种基于开源数据与已有约束结构的数据生产方法。其次,利用带有可验证、以规则为中心的奖励建模,通过强化学习(RL)培养模型在遵循指令时的推理能力。

方法:从数据生产方法到推理能力
复杂规则与约束的复杂指令数据生产
针对复杂指令集的数量问题,研究团队基于现有分类法对复杂指令进行分解,提出了一种基于开源数据与已有约束结构的数据生产方法以及校验准则的方法。
种子指令挑选:团队从WildChat和Alpaca等数据集中多样化地筛选种子指令,并通过主题和任务标签进行细致挑选。
带规则约束的指令发散:团队在细粒度规则和约束下自演化指令,结合代码执行和LLM判别两种验证方式,确保生成指令的多样性和有效性。
回复生产与质量校验:团队利用LLM生成回复并通过多重验证筛除低质量样本,同时用LLM判别典型问题以保证指令和回复的合理性。
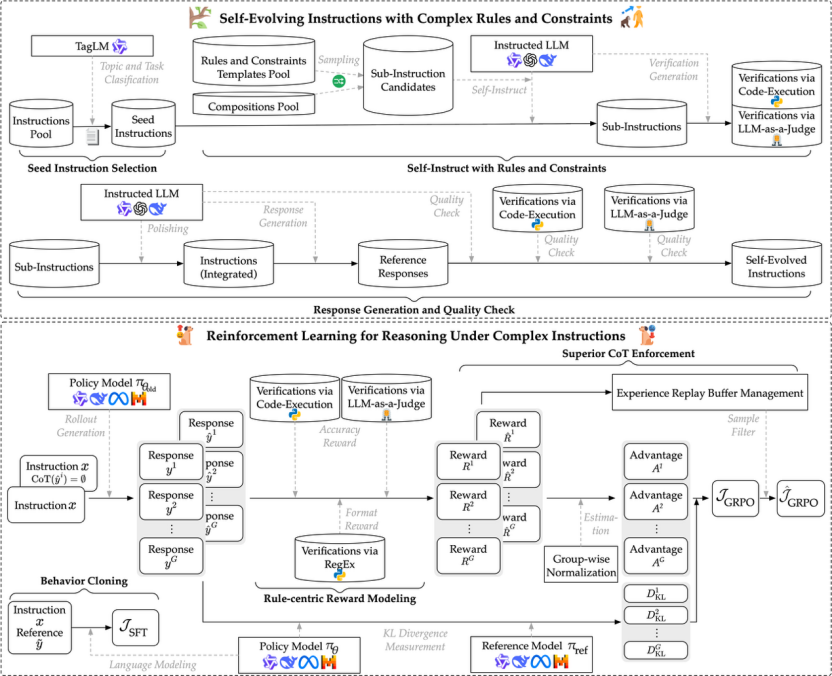
面向复杂指令任务下推理的强化学习
团队提出利用强化学习(RL)方法(采用GRPO算法),通过规则驱动的奖励机制,优化大语言模型在复杂指令下的结构化推理能力,提升最终答案的准确性。
基于规则的奖励建模:团队设计了基于规则的奖励函数,分别对推理格式和多约束满足度进行评价,结合启发式与奖励模型,实现对复杂指令响应的精细化引导。
经验回放缓冲区筛选:团队引入自适应经验回放机制,通过对比有无推理过程的样本表现,筛选并强化能带来更优结果的推理链,提升模型在复杂任务下的推理有效性。
策略模型分布偏移控制:采用行为克隆约束策略分布,防止模型在片面追求约束满足时牺牲语义或遗忘原有知识,确保推理内容与答案的语义一致性和流畅性。
结果与讨论
与基线方法的比较
此方法能有效提升大多数现有LLM在处理复杂指令时的表现,体现了深度推理的泛化能力。
相比之下,CoT提示会导致所有模型性能大幅下降,进一步证实了浅层思考的负面影响。SDC方法将推理与回答分为两步,但由于其本质上的表面性,仍未能提升推理质量。
SFT技术通过知识蒸馏让小模型模仿强模型的推理模式,保证了思考的深度和广度。但SFT的缺点是对训练外样本的泛化能力较差。基于RL的训练方式则教会LLM如何思考,推动多样化推理的自我发展,而非简单记忆。
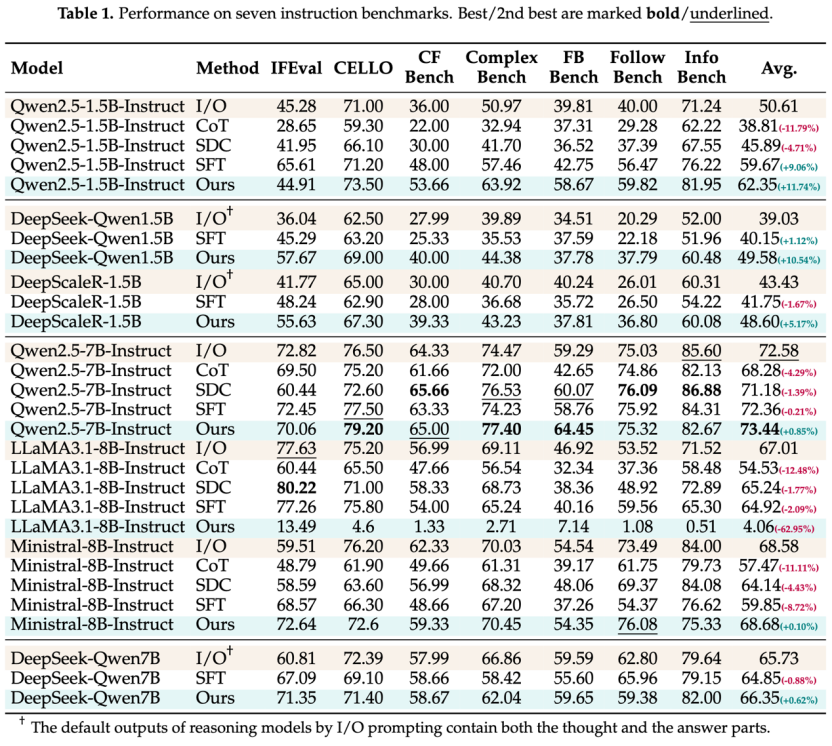
不同模型大小与基座的比较
小模型(1.5B)在训练中获得的提升远大于大模型,显示了小模型通过测试时扩展的潜力。
DeepSeek蒸馏的LLM因广泛模仿任务而在推理的结构学习上有更好的起点。Ministral和LLaMA的能力不如Qwen,且LLaMA3.1-8B在训练中出现模型崩溃。
LLaMA模型在训练中出现响应急剧缩短和KL惩罚激增,表明其偏离初始状态。这可能与底座模型的预训练知识有关,LLaMA倾向于无休止地生成思考,难以输出一致的语义响应,最终导致崩溃。
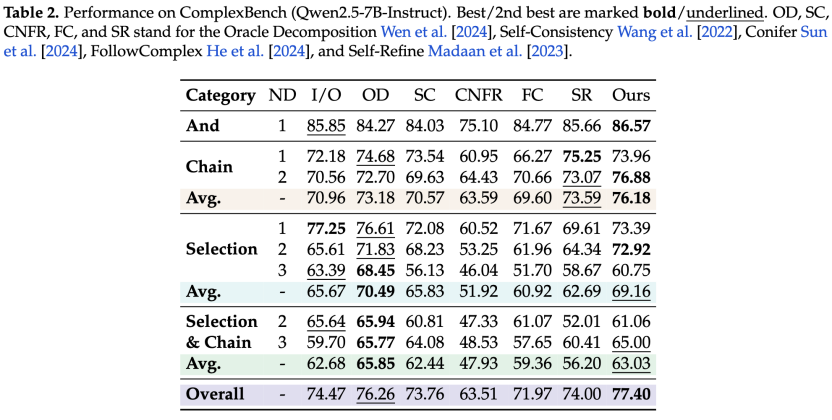
与SOTA方法的比较
团队在ComplexBench上实现了多种SOTA方法,并在最复杂的Chain和Selection类别上表现出色。这表明深度推理确实有助于LLM分析并完成真正相关且有约束的请求。
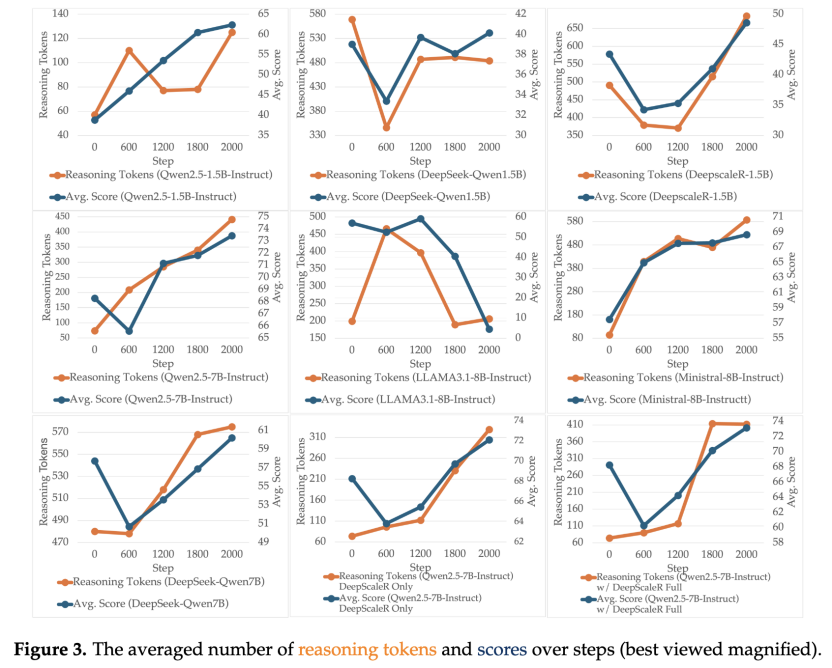
推理模式的变化
关键词如“first”“second”等的变化显示,所有LLM在CFBench和ComplexBench等高难度基准上推理词频增加,证实了深度推理的重要性。对于没有复杂结构的指令,慢思考LLM的关键词频率随着响应长度变短而略有下降。

数学数据的重要性
DeepScaleR在推理能力培养上起到了积极作用,数学题数量的增加与CoT token增长和性能提升正相关。
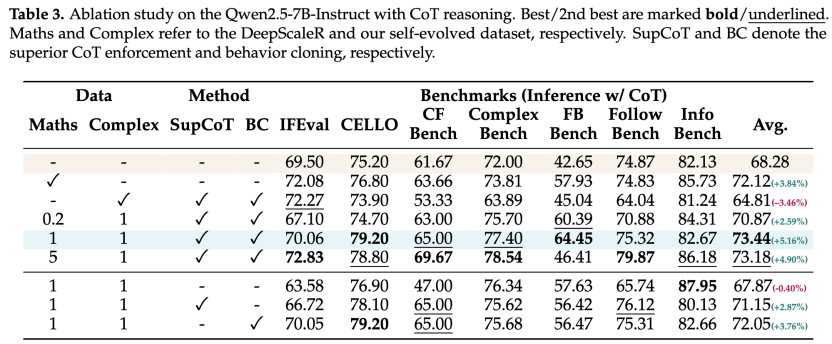
筛选机制的作用
优秀CoT样本比例先降后升,说明训练中浅层到深层推理的转变被促进,最终带来更高奖励的响应。经验回放中筛选优秀CoT样本有助于满足输出格式约束,防止劣质推理获得奖励,并为模仿专家思维留出时间。

团队发现,直接模仿专家推理不仅鼓励模型获得格式奖励,还能稳定训练并弥补规则奖励的不足。
论文地址:https://arxiv.org/pdf/2506.01413
项目地址:https://github.com/yuleiqin/RAIF
数据:
https://huggingface.co/collections/yolay/raif-arxivorg-pdf-250601413-682b16e5c0c2fa9b73811369
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)