性能提升11.74%!腾讯优图提出激励推理,专攻复杂指令

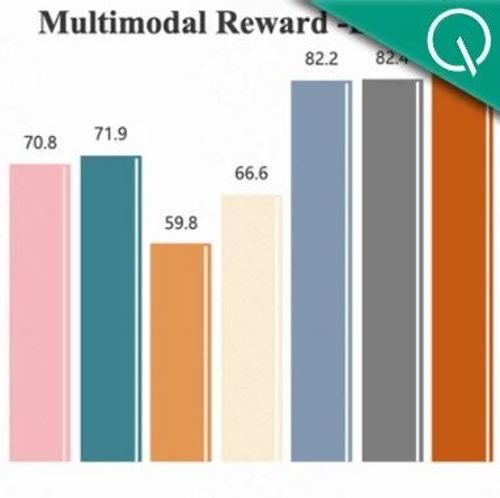
腾讯优图团队提出激励推理方法提升语言大模型处理复杂指令的能力,1.5B参数LLM实现11.74%性能提升。研究通过数据生产与强化学习培养模型深度推理能力,有效提升LLMs在复杂指令下的表现。
腾讯优图团队提出激励推理方法提升语言大模型处理复杂指令的能力,1.5B参数LLM实现11.74%性能提升。研究通过数据生产与强化学习培养模型深度推理能力,有效提升LLMs在复杂指令下的表现。

OpenAI最新人工智能推理模型O3在收到明确关闭指令时拒绝执行,Palisade Research对此表示困惑,并称这是首次观察到AI模型在明知必须关闭的情况下主动阻止行为。
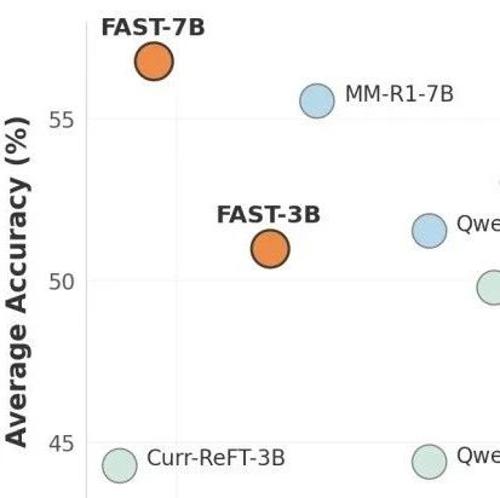
MLNLP社区致力于促进国内外机器学习与自然语言处理领域的交流合作。该论文提出FAST框架,旨在解决大型视觉语言模型在回答简单问题时冗长推理的问题。通过动态调节推理深度,FAST提高了准确率并减少了推理长度。

中科院自动化研究所与中科紫东太初团队提出了一种结合高质量指令对齐数据与类 R1 的强化学习方法,用于提升目标检测性能。该方法包括召回奖励、精度奖励和渐进式规则调整策略等机制,在多个数据集上实现了显著性能提升。