

为什么大模型会“想太多”?
当你被问到“1+1等于几”时,如果非要先写一篇《论加法本源》再回答“2”,这就是典型的“过度思考”。当前的大型视觉语言模型(LVLM)也面临同样问题:无论问题难易,它们都会生成冗长的推理过程,导致效率低下,甚至因“话多必失”降低准确率。
论文:Fast-Slow Thinking for Large Vision-Language Model Reasoning
链接:https://arxiv.org/pdf/2504.18458
如下表中简单题反被长答案拖累: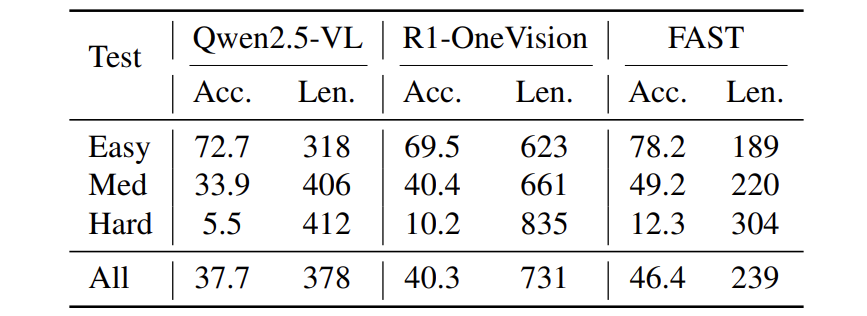
论文将这种现象称为“overthinking”,并指出其核心矛盾:
-
简单问题:长答案浪费算力,还可能引入错误细节 -
复杂问题:短答案无法覆盖关键推理步骤
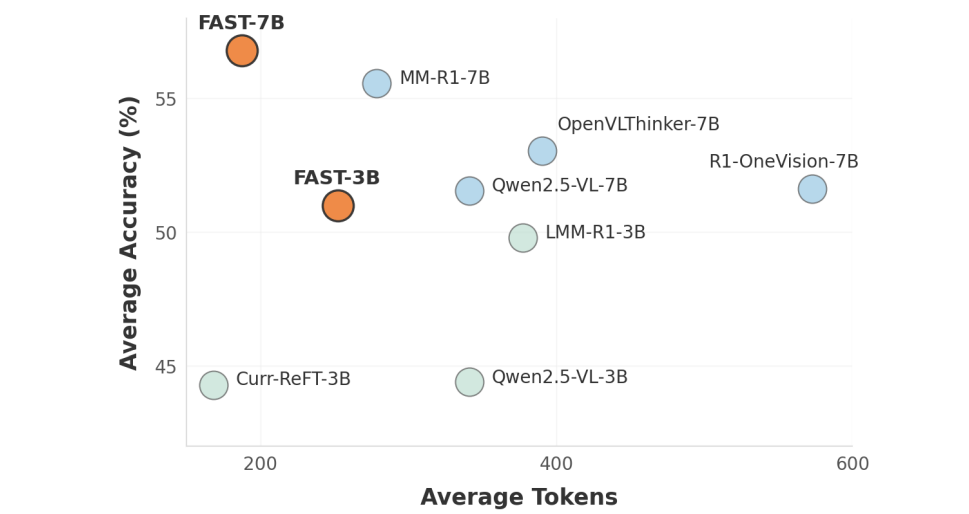
学会“偷懒”:FAST框架的三大绝招
FAST的核心是动态调节推理深度,其秘诀在于三个创新设计:
问题难度
-
难度分:通过模型多次尝试的正确率计算(公式:),实时判断题目难度。 -
复杂度分:结合图像纹理(GLCM熵)和语义(ViT分类熵),量化问题是否需要详细推理(公式:)。
奖励机制
-
准确奖:答案正确+1分 -
格式奖:按要求用标签包裹答案+0.5分 -
思维奖:简单题答得短/难题答得长+0.5分
(公式:动态调节长度奖励,见下表对比)

动态刹车系统
通过KL散度系数控制模型“放飞自我”的程度:
-
难题(如微积分):松开刹车(β 趋近0.001),鼓励探索 -
简单题(如识图):踩紧刹车(β 趋近0.03),避免跑偏
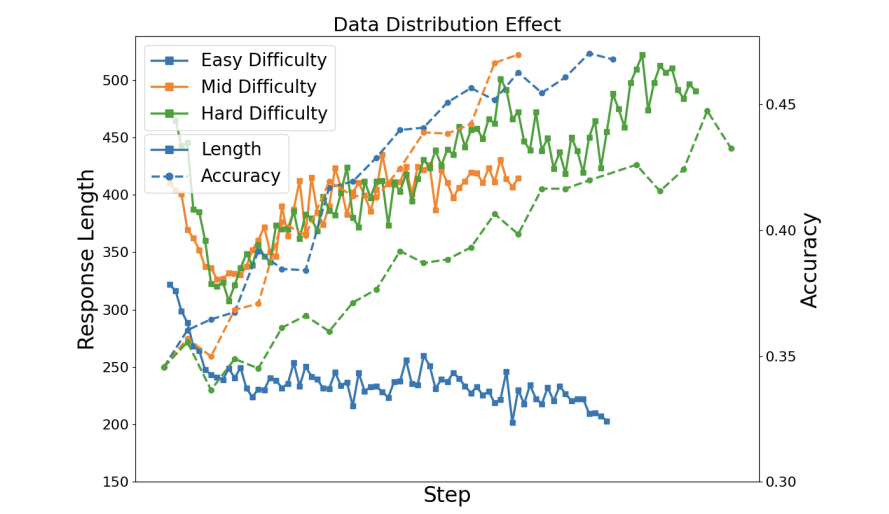
实验:准确率飙升10%,推理长度砍半
论文在7个多模态推理基准测试中验证FAST:
-
准确率:相比基础模型平均提升超10%,在MathVista等复杂任务中超越GPT-4o -
效率:推理长度比传统“慢思考”方法减少32.7%-67.3%(如下表中R1-OneVision长度692 vs. FAST仅204) 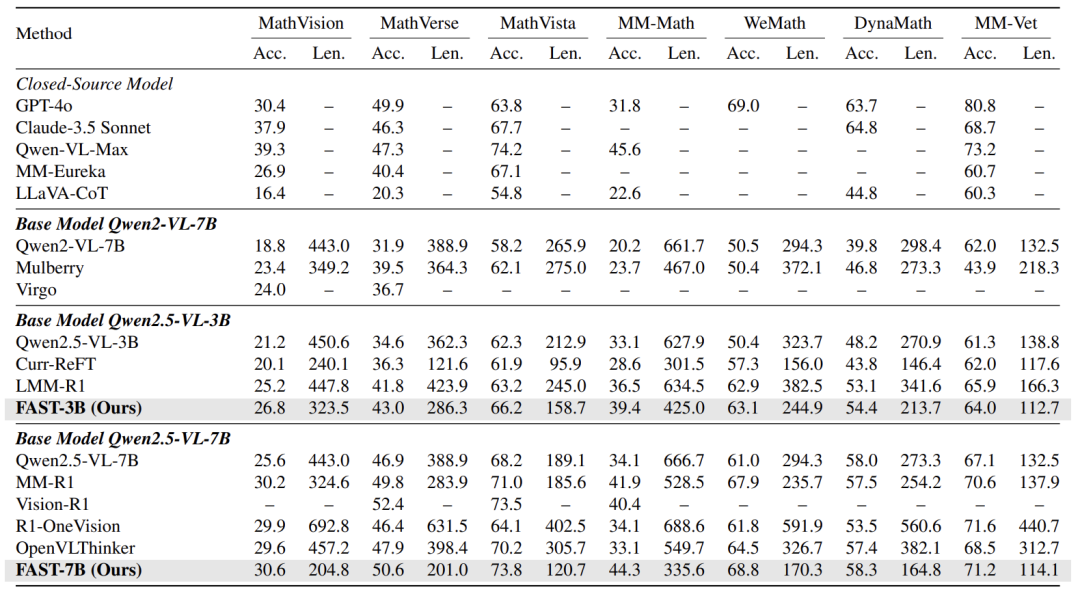
-
智能平衡:对难题自动延长推理(如几何题硬核模式长度+60%),简单题则“秒答”

技术灵魂:动态调节的“刹车”与“油门”
FAST最精妙的设计在于动态性:
-
数据筛选:训练前期专攻难题(“慢思考”),后期专练速答(“快思考”) -
奖励机制:不是一刀切鼓励长或短,而是根据题目类型“按需分配” -
正则化调节:KL系数随难度浮动,如同开车时自动切换经济/运动模式
这种设计让AI像人类一样具备元认知能力——知道何时该深思熟虑,何时该果断决策。
最后,论文也指出待解难题:如何让模型自主判断“未知问题”该快该慢?这可能成为下一阶段的研究重点。
(文:机器学习算法与自然语言处理)