
将 PDF 转成文本这件事,过去是“能做到”,现在是“轻松做到”。
最近我搭建了一个图数据库(Graph Data Store),用于 RAG 系统 —— 换句话说,我们做了一个 GraphRAG。
为什么用 GraphRAG?
相比常见的向量数据库支持的 RAG,Graph RAG 有个巨大优势 —— 推理能力更强。比如:
问题 A:「XYZ 公司去年 CFO 是谁?」
这种问题,向量搜索就能搞定,因为年报里通常直接写了。
但换成这样:
问题 B:「XYZ 公司有哪两位董事是同一所学校毕业的?」
如果年报没有直接提学校名,向量搜索就“废了”。GraphRAG 就能玩得转,因为它能推理出隐含关系。
但问题来了 —— 怎么构建这个图?
我最近写了一篇文章专门讲这个问题。但如果我们再往前一步想:怎么从 PDF 里提取信息来构建知识图谱?
这篇文章就来讲这个过程。
🛠️ 如何把 PDF 转成结构化富文本?
所有的工程步骤都从一件事开始:把 PDF 变成文本数据。
但问题是 —— 年报不是普通 PDF,它们包含大量图表、表格、结构化数据。这些内容都非常关键。
大多数 Python 开发者用过 PDF 解析库,比如:
•PyPDF2 —— 超老牌,能用,但很简陋。•PyMuPDF4LLM —— 能直接把 PDF 转成 Markdown 格式。•Docling —— IBM Deep Search 出品,提取效果惊艳。•Marker —— 另一个很新的工具,表现也不错。
我们依次测了一下这几个工具的效果。
✅ 各工具提取效果对比
•PyPDF2:纯文本提取,没有任何结构。段落、标题、表格、列表,全都混成一堆。
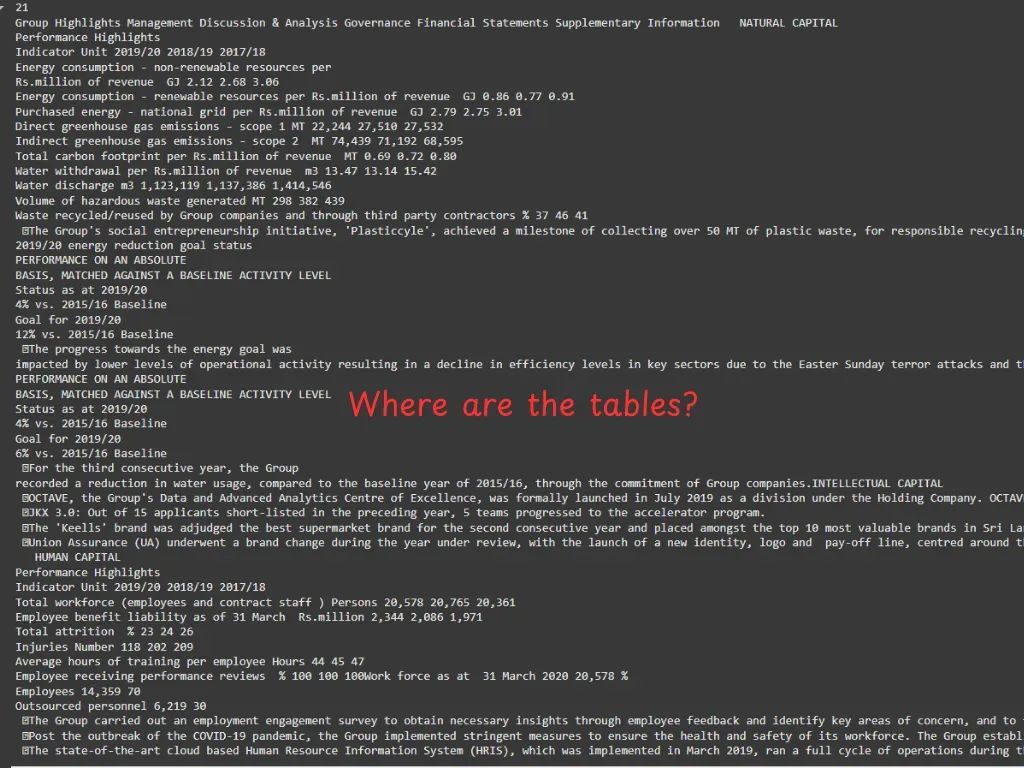
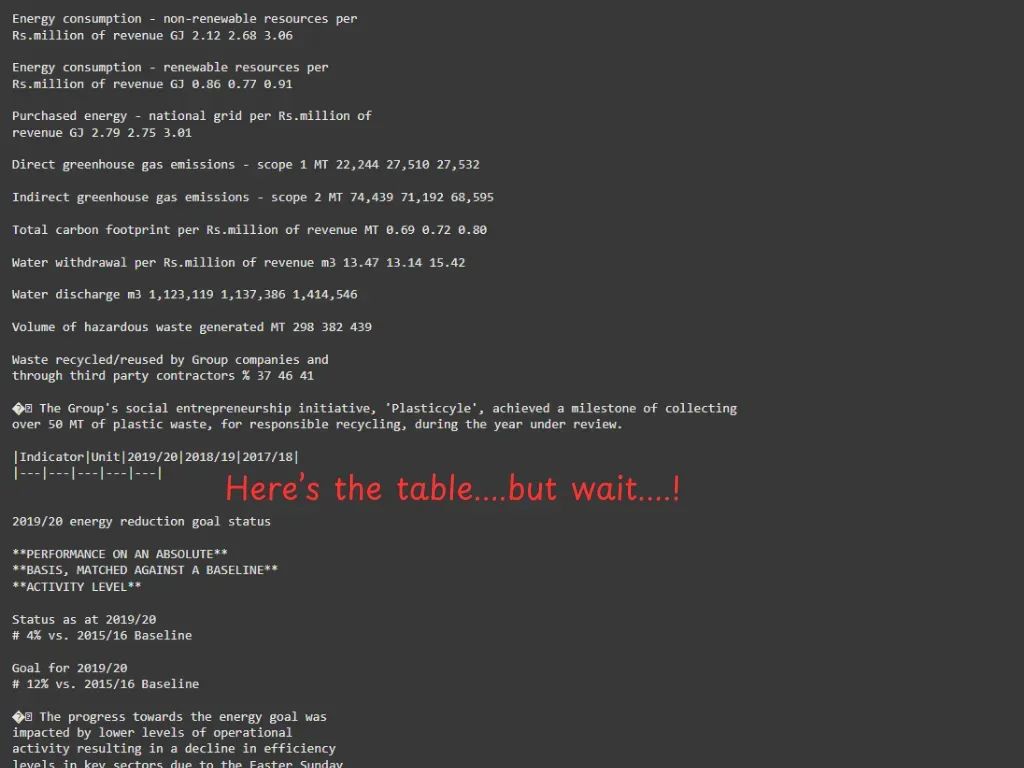
•PyMuPDF4LLM:能转成 markdown,有结构信息,LangChain 等框架支持,但表格效果拉胯。
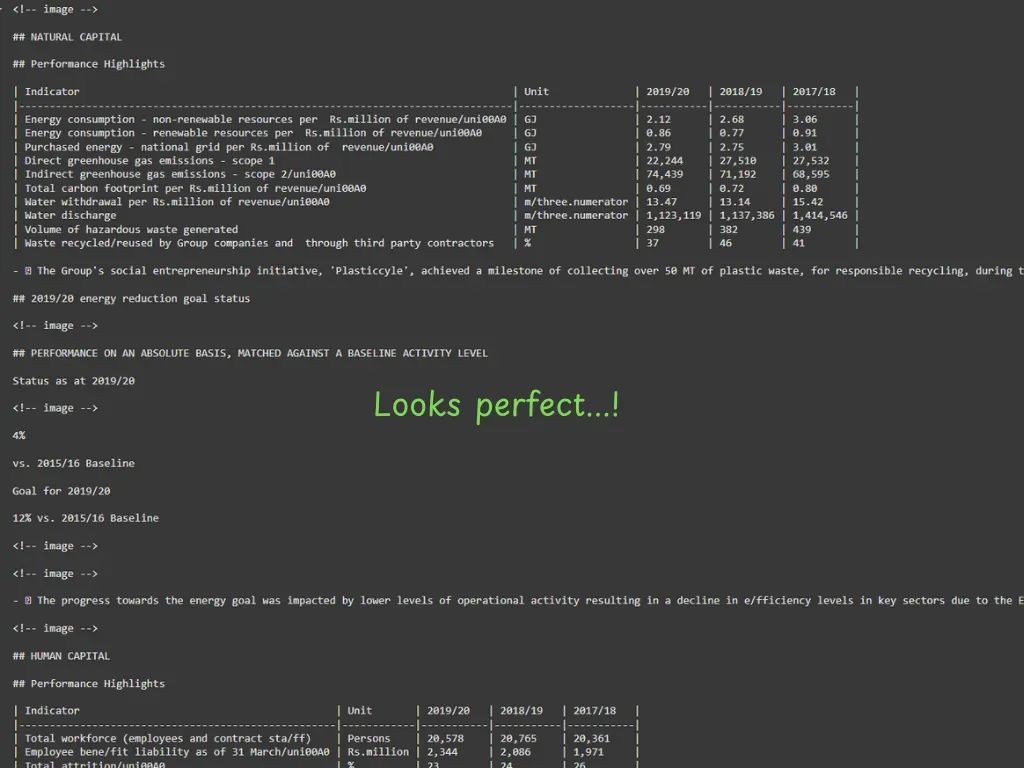
•Docling:表现最强!能保留标题层级、表格结构、甚至给图片加占位符。
•Marker:也不错,但整体信息保留度不如 Docling。
所以最后我们选了 Docling 作为主工具。
⚠️ Docling 的问题:太慢了!
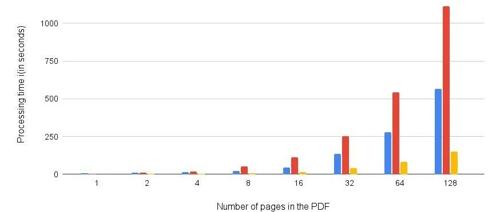
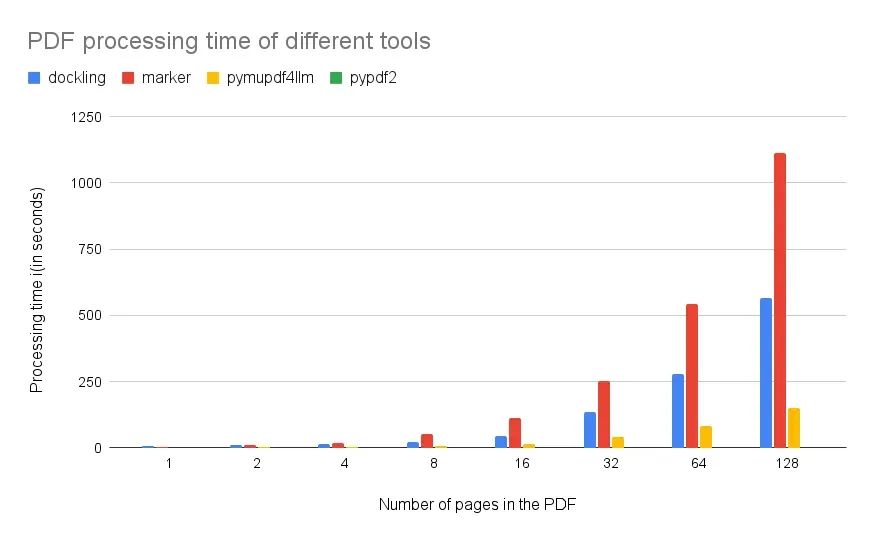
我们做了一个实验,把年报里包含文字、表格、图片的混合段落提取出来,放在不同页数的 PDF 中,测试不同工具的处理速度。
结果如下:
•Docling:每页大概 4 秒•Marker:每页大概 8 秒•PyPDF2:飞快,但结构信息很少
如果你要处理几十份报告(比如 50 份,每份 300 页),那就意味着:
300页×50份×4秒÷3600秒≈17小时这还可以接受。但如果扩展到 S&P500 所有公司的 30 年年报 —— 就得处理上百万页。
靠单机做是不现实的,所以我们选择了:
☁️ 云服务 + 并行处理
我们用云服务搭了一个转换服务,可以并行处理 PDF,提取结构化 Markdown,然后自动更新 GraphDB。
这个架构可以很好地扩展,未来接更多数据没问题。
✅ 最终结论
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以,我们最后选择:
•结构提取用 Docling•大规模处理时,用云服务并行跑•如果你对速度极度敏感,PyPDF2 还是最快的选择
🙌 总结
PDF 转 Markdown 的工具这些年进步巨大,但 表格提取仍然是个挑战。
我们比较了四个开源工具,最后用 markdown 构建了图谱,并在 GraphRAG 系统中实现了应用。
Docling 是效果最好的提取工具,但速度较慢 —— 所以我们搭了云服务来处理。
这就是我们在从 PDF 到智能图谱路上的第一步!🚀
(文:PyTorch研习社)