

今天是2025年6月30日,星期一,北京,晴,今天是2025年上半年的最后一天了。
我们继续看GraphRAG的问题,基于图的检索增强生成(Graph-RAG)在处理动态增长语料库时的效率问题。
现在的一些方案,主要集中在静态语料库的检索增强生成,如Vanilla RAG、Graph-based RAG等。动态检索方法如DRAGIN、LightRAG和DyPRAG等虽然尝试解决动态语料库的问题,但在高频数据变化下的动态更新消耗仍然较高。
这个问题的难点在于如何在不需要全图重建的情况下,高效地更新语料库,并保持高检索准确性和低延迟。

所以,问题来了,既然需要动不动就重新构图,那么是否可以去个重,分个桶,然后把新更新的,归类到某个桶中,然后再根据这个桶所属的层级中,做局部更新?

这也就一种动全部,不如拉相似度分桶动局部的思路,那就会用到聚类,去重这些,所以,我们来看看一个具体的实现思路,很简单。
另外,最近也在继续造新词,还是需要新故事维持热度,继续换概念,值得就是这个上下文工程(context engineering),来看看是个啥?
一、LSH局部敏感哈希+RAPTOR动态更新的GraphRAG思路-EraRAG
顺着上面的思路,看最近的一个工作,EraRAG: Efficient and Incremental Retrieval Augmented Generation for Growing Corpora,https://arxiv.org/pdf/2506.20963,实现的代码在:https://github.com/EverM0re/EraRAG-Official
其实现思路很简单,利用基于超平面的局部敏感哈希(LSH)将原始语料库分区和组织成层次化的图结构,通过将相似项映射到相同的桶中,实现高效的分组。通过递归的LSH分割和总结,构建了一个多层次的图结构,当新语料条目到达时,EraRAG通过将新块编码为向量嵌入,并将其插入到适当的桶中,进行向上传播的调整,这些调整仅限于受影响的部分,而不会改变图的其他部分。
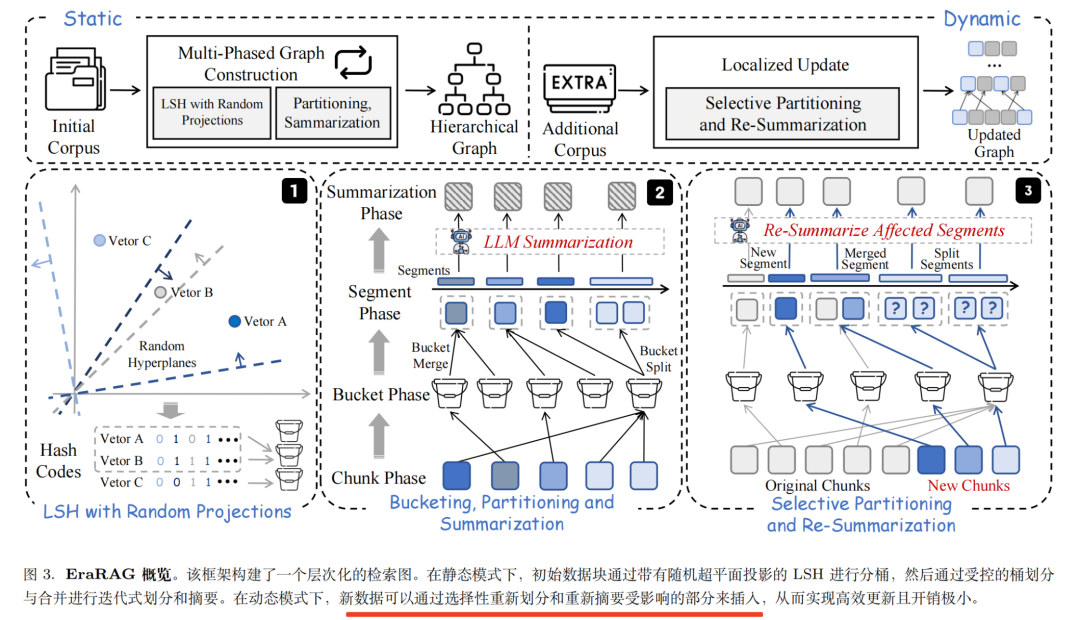
进一步的拆分开来,核心步骤就几个:
1、LSH-based图构建
LSH局部敏感哈希,是常见的相似度方案,利用哈希将相似项映射到同一桶中。
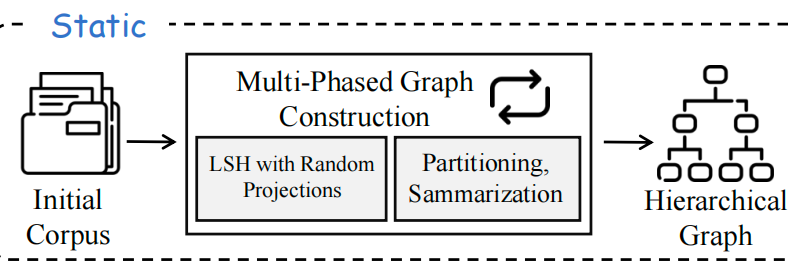
1)LSH分段
在这个方案中,给定输入语料库后,首先将其处理为文本块,然后将它们编码为向量嵌入。然后,将这些向量投影到n个随机采样的超平面上,并编码为一个n位二进制哈希码。具有相似哈希值的向量被分组到同一个桶中。
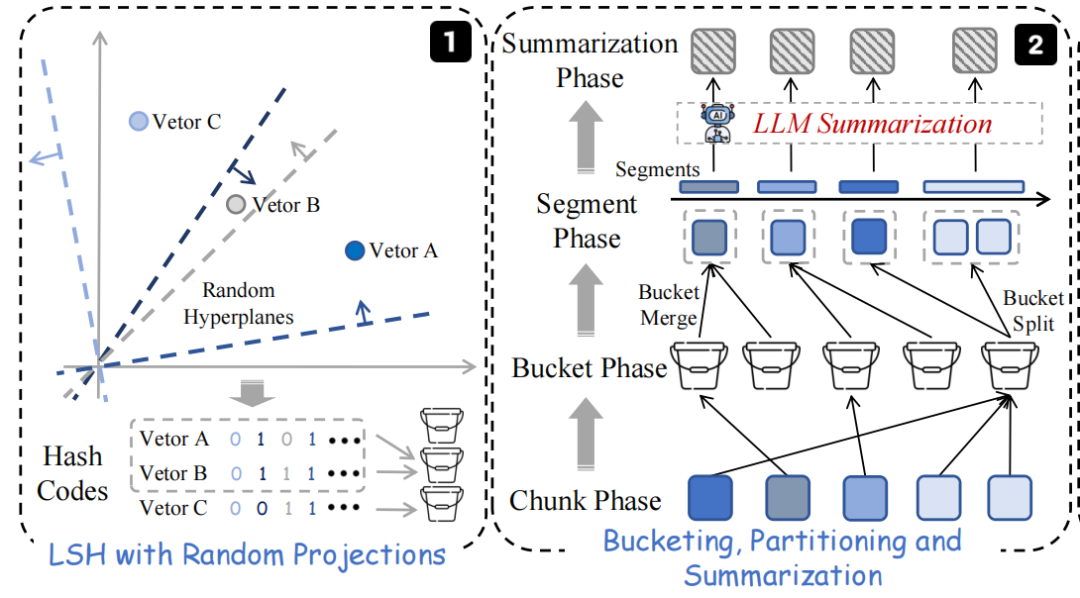
2)分段调整
每个分段的大小受到用户定义的上下限控制。较小的桶会与相邻的桶合并,而较大的桶会被分割。对于每个生成的分段,使用LLM将其包含的文本块总结为一个新的块。
3)构建层次图
递归调用哈希、分段和总结这个过程,采用RAPTOR方案,构建多层次的图结构。
4)局部更新

当新语料库条目到达时,新块被编码成向量嵌入,插入到相应的桶中,并进行向上的传播调整,仅限于受影响的部分,而不改变无关部分。
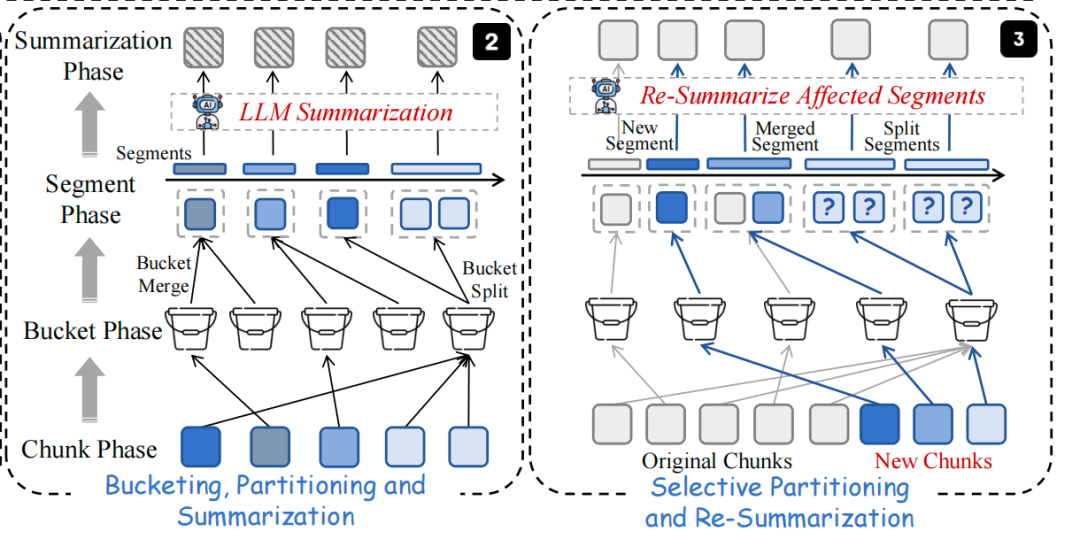
所以说,这个想法很自然,动全部,不如拉相似度分桶动局部,结果也很直接,例如,在HotpotQA数据集上,EraRAG相比RAPTOR减少了高达77.5%的图重建时间。
但是,这种方法也存在一些问题,这个很依赖于分桶的质量,以及初始形成的图结构。适当的分段大小有助于平衡效率和检索质量,过大或过小的分段都会影响性能。
二、继续造词包装-“上下文工程”概念
也是昨天,看到一个新词,叫“上下文工程”,来自https://blog.langchain.com/the-rise-of-context-engineering/,有人调侃到,提示工程又换个说法,下一个名字我已想好,“语义态势感知管理”,缩写LSDM。
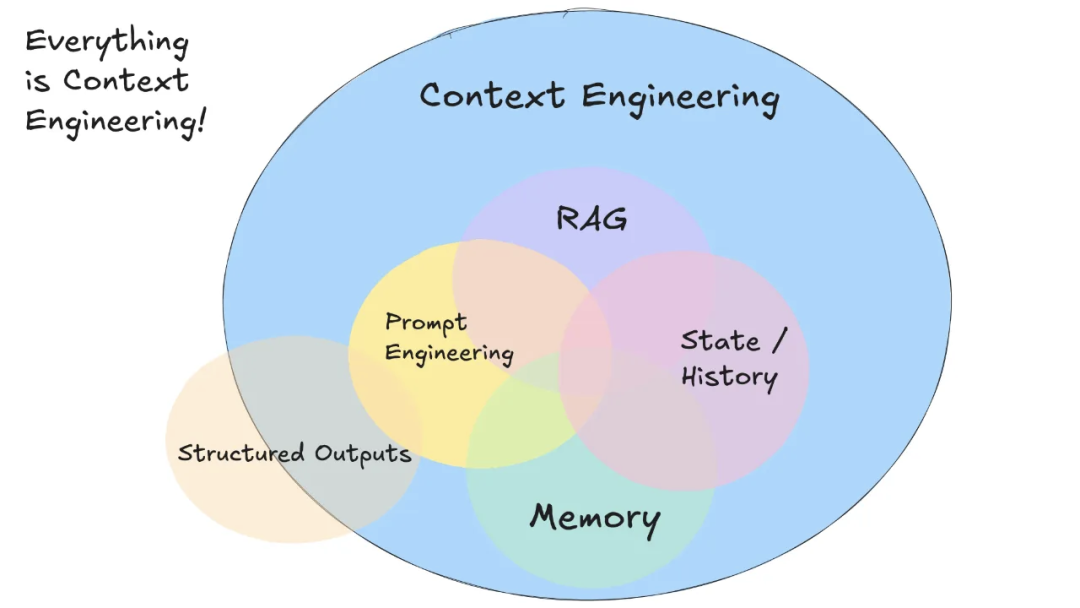
从这张图上,可以很直接的看到“上下文工程”是个啥,就是把RAG、提示词工程、记忆、历史记录这些包成了一个整体的新词。
用这个blog的话来说,上下文工程就是构建动态系统,以提供正确格式的信息和工具,使大型语言模型(LLM)能够合理地完成任务。
大多数情况下,当代理(agent)不可靠地执行任务时,根本原因是没有将适当的上下文、指令和工具传达给模型(这是个废话,因为现在大模型做应用,prompt是媒介。)
MCP\ACP这些也不火了,Agent继续炒,就要新的名词,新的概念,这样,才有新的故事,但这并不好,并没有新的东西产生,反而加重了认知负担。
参考文献
1、https://github.com/EverM0re/EraRAG-Official
2、https://blog.langchain.com/the-rise-of-context-engineering/
(文:老刘说NLP)