

与大语言模型数据不同,具身智能需要采集物理交互中的高维动态数据(如力反馈、材质摩擦、碰撞响应等),但真实场景数据获取依赖精密传感器和硬件设备,且受限于场景多样性、安全风险及隐私等问题,目前全国范围内具身智能最大开源数据集规模也只有百万级别,相比自动驾驶领域的单日上亿条数据,相差百倍以上。
除数据规模外,在涉及具体智能体物理交互的相关问题(例如“抓取力度”“滑动摩擦系数”)时,这些数据难以用语言进行精准描述。数据标注工作需结合动作意图与环境反馈,正因如此,大量数据的标注任务仍需依赖人工完成。
针对具身智能数据问题,近日2025北京智源大会上孙富春、赵明国、王鹤、庞江淼、赵同阳、仉尚航、卢宗青、高阳、唐剑等行业领军人物 ,分享了他们在具身智能数据方面的思考。
▍孙富春:未来团队将采集200万条轨迹、数据总量52 TB 远超英伟达数据规模
清华大学计算机科学与技术系教授、中国人工智能学会副理事长孙富春指出,具身智能不应仅局限于视觉感知单一层面,更应该融合视觉、听觉、触觉等多种感官数据,从而构建更加全面的智能系统。特别是在操作物体时,触觉数据对于理解物体的物理属性和执行精确操作至关重要,这一定程度上突破了传统以视觉为中心的研究模式。

在具身智能数据获取方面,孙富春提出沉浸式感知与数字物理系统概念。他主张通过构建高精度的数字物理系统,来模拟真实的物理环境,为具身智能提供沉浸式的感知体验。这一决策不仅有助于智能体在虚拟环境中进行高效训练,还能将学到的策略迁移到真实世界中,进而提升具身智能的适应性和鲁棒性。
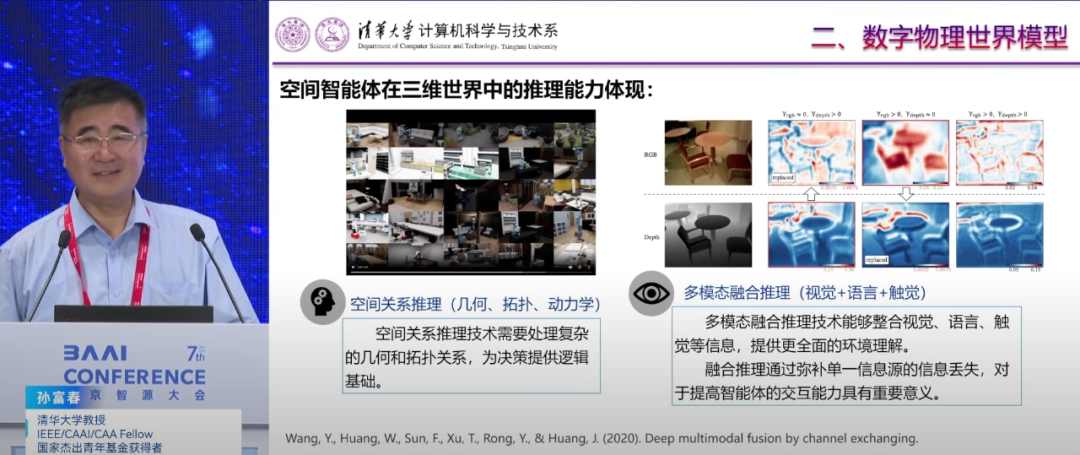
孙富春提到,在利用大模型训练具身智能的过程中,很重要一部分是需要同步采集多模态轨迹。未来团队将会实现采集200万条轨迹、数据量为52 TB的目标,远超过英伟达现在构造的120万条轨迹、32TB的数据量。
此外,通过构建具有泛化能力的模型,可以将在一个场景中学到的策略迁移到其他场景中,从而提高具身智能系统的通用性和灵活性。孙富春提倡使用对抗学习等方法来生成多样化的数据,来增强模型的泛化能力。
▍王鹤:合成仿真数据是破解具身智能的数据瓶颈最优解
北京银河通用机器人有限公司创始人王鹤认为通用机器人的核心在于通过具身智能实现高自由度的仿人操作,以服务于多个行业和家庭。VLA作为实现这一目标的关键技术,整合了视觉、语言和动作模态,通过端到端的多模态大语言模型,使机器人能够理解和执行人类的语言指令。
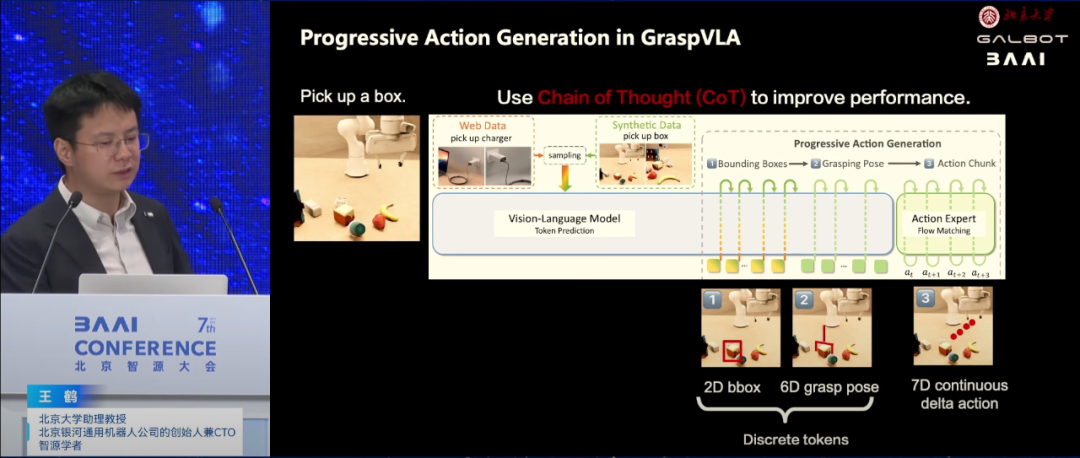
王鹤强调,视觉模态在机器人信息输入中占据重要地位,占人类每日信息输入量的80%以上。VLA模型不仅能实时生成轨迹,还具备快速闭环反馈的能力,频率从单赫兹提升至五十赫兹甚至更高,确保机器人能够迅速响应环境变化。
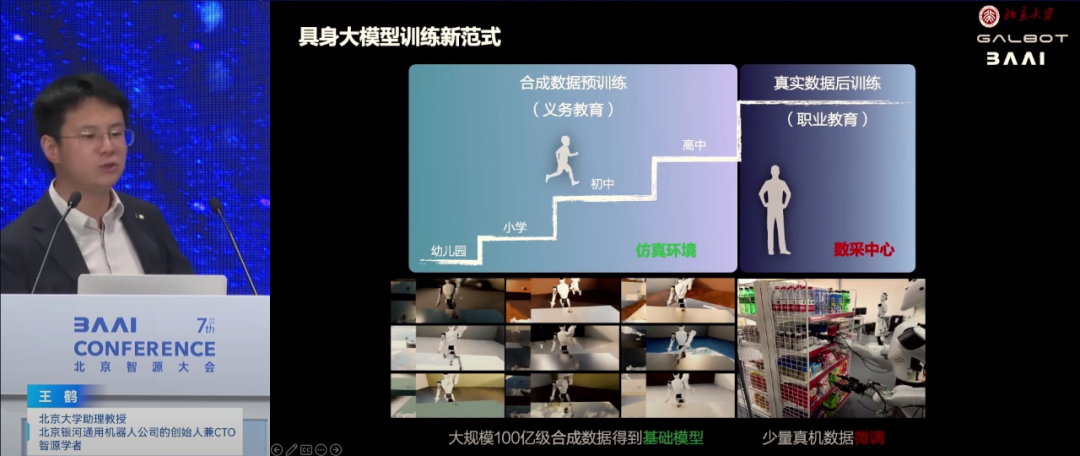
针对数据采集难题,王鹤提出利用合成仿真数据破解具身智能的数据瓶颈。他介绍了团队通过生成大量可交互的家用电器、家具等物体资产,并在这些物体上生成抓取标签和轨迹,结合强化学习进行自主探索,成功构建了完全用合成数据训练的具身端到端VLA大模型。该模型具备强大的泛化能力,能在未见过的环境中直接执行任务,成功率显著高于依赖少量真实数据训练的模型。

此外,王鹤还展示了VLA模型在真实世界中的应用,包括密集货架抓取、复杂环境导航、跟随人行走等,展示了其在零售、物流、工业等多个领域的落地潜力。他强调,通过合成数据与少量真实世界数据的结合,不仅可以大大降低数据采集成本,还能加速人形机器人技术的研发进程,推动其更快走向商业化应用。
▍北京大学卢宗青:互联网视频数据是解决人形机器人数据缺失问题的关键
北京大学副教授、BeingBeyond创始人卢宗青指出,当前机器人训练依赖的方法,如遥操作(teleoperation)和仿真(simulation),存在明显局限。遥操作受限于机器人本体的迭代,难以采集大规模数据;仿真数据虽可合成,但强化学习难以融入真实世界的物理信息,导致模型在现实场景中表现不佳。卢宗青并不认可现有的World Model,他认为不管是像 Nvidia 说的Cosmos,还是市面上大家在做的视觉生成模型,均缺乏动作级别的信息,因此无法满足机器人训练需求。

卢宗青强调,互联网视频蕴含了大量人类运动信息,具有极高价值。卢宗青团队通过3D姿态估计技术从视频中提取人类动作,并利用生成模型和强化学习技术,将其转化为机器人可学习的动作序列。目前团队已构建大规模数据集,并实现了从文本到姿态、再到机器人控制的完整流程。
然而,互联网视频数据缺乏空间物理和本体感知信息。为此,卢宗青提出在预训练基础上,结合真机数据和仿真器进行对齐的方法。他设计了基于“强化学习物理反馈”的方法,在模拟器中调整生成的姿态,使其符合机器人的物理约束,提升模型在真实世界中的表现。
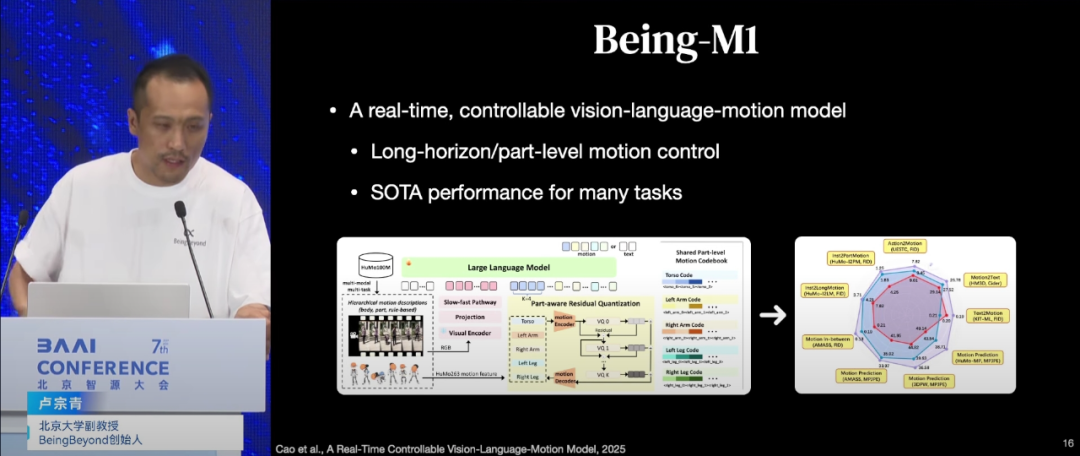
此外卢宗青展示了团队在姿态生成、动作控制及视频理解等方面的最新进展。他提到,团队通过持续优化模型架构与训练策略,不仅显著提升了机器人在复杂环境中的操作精度与效率,还在多项国际竞赛中取得了优异成绩,进一步验证了该方法的有效性。
▍高阳:机器人落地的核心问题在于智能化
千寻智能联合创始人、清华大学交叉信息研究院助理教授高阳深入探讨了如何将智能迁移至物理世界,以辅助人类完成如扫地、洗菜、切菜等家务任务。他指出,具身智能与以往机器人的核心区别在于其智能性,这一波具身智能的浪潮正是源于大语言模型在通用智能层面的重大突破。
高阳回顾了机器人技术的发展历程,提到20年前Honda的阿西莫机器人、Shadow Hands的灵巧手以及Boston Dynamics的四足机器人等,尽管当时这些机器人已展现出惊人的运动能力,但受限于非智能算法,其应用范围和灵活性受到极大限制。他强调,如今机器人大规模落地的核心问题在于智能化,而非硬件本身。
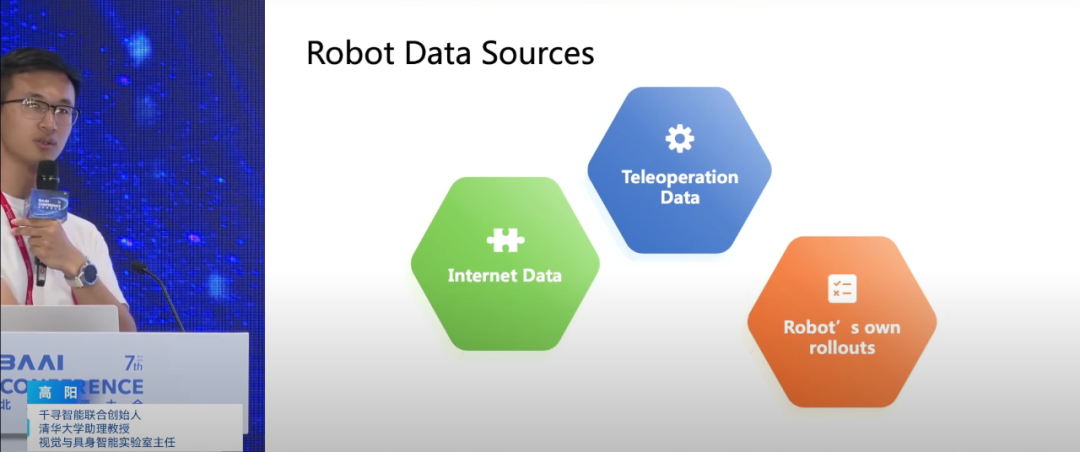
数据是解决智能化问题的关键,为解决数据瓶颈,高阳提出了三方面数据来源:互联网视频预训练、遥操作数据微调以及物理世界强化学习优化。他特别指出,通过模仿人类在视频中的行为,机器人可以学习到复杂的操作技能。千寻智能已将该方法应用于实际验证,例如通过分析人类叠毛巾的视频,模型学习到毛巾的运动轨迹和手的操作方式,并迁移到机器人上,使其能处理任意状态的衣服或在陌生环境中倒茶,展示了较高的成功率与实用性。
此外,高阳还分享了团队在具身智能领域的最新进展。团队通过采集遥操作数据对模型进行微调,使其适应具体任务和机器人硬件,并通过物理世界强化学习优化模型,以适应真实环境的复杂性和不确定性。高阳展望了未来十年具身智能的发展前景,并提出了“双十计划”,即希望在十年内让全世界10%的人拥有自己的机器人,以解放日常体力劳动。
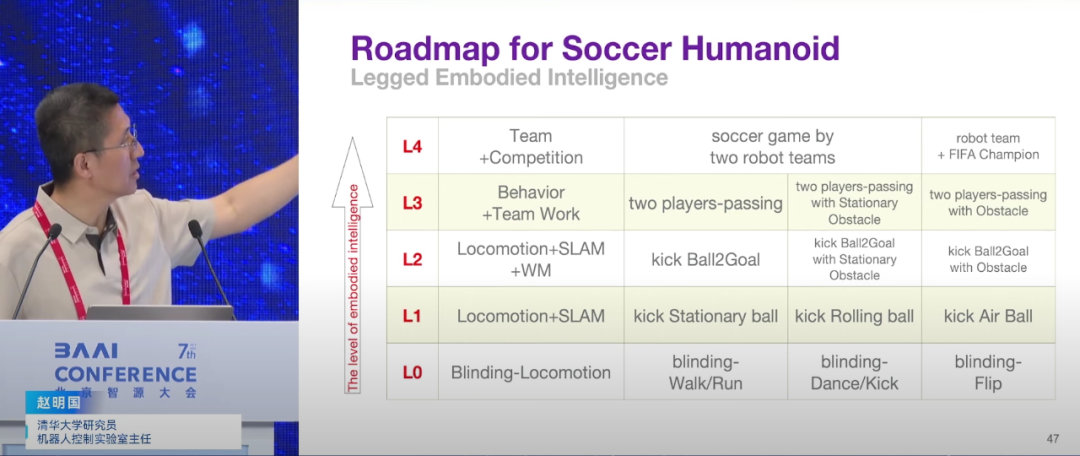
▍赵明国:具身智能的核心价值在于拥有“举一反三”的泛化能力
清华大学自动化系研究员、机器人控制实验室主任、清华大学无人系统中心类脑机器人中心主任赵明国强调了具身智能的核心价值在于其泛化能力,即“举一反三”的能力,而非仅在特定场景下执行重复性任务。他指出,物理世界的复杂性和不确定性使得泛化之路充满挑战。
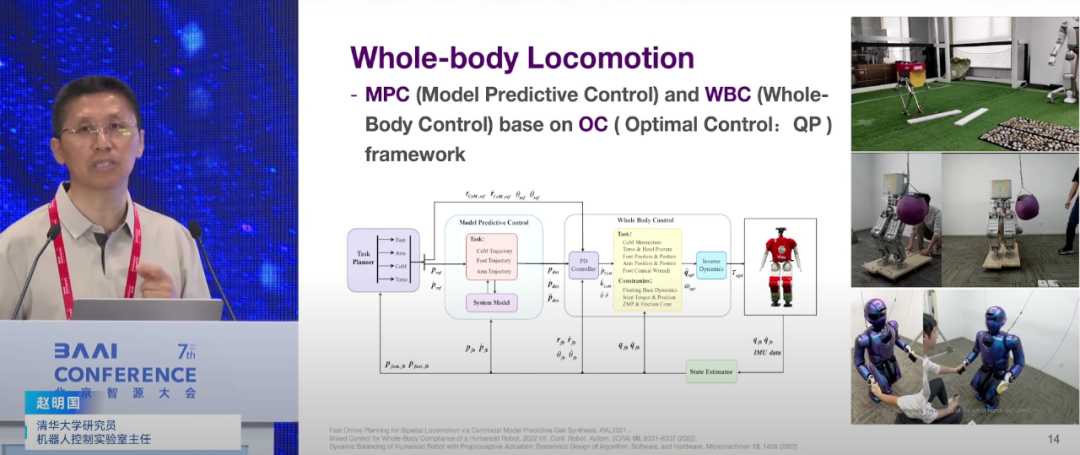
赵明国的研究根植于机器人控制理论和生物力学,他关注物理层面的泛化,即机器人如何鲁棒地适应物理世界的变化。他认为传统基于模型的控制方法,如全身控制和模型预测控制,在面对复杂动态环境时的局限性,认为这些方法计算量大,需大量人工调整,难以实时应对快速变化的场景。
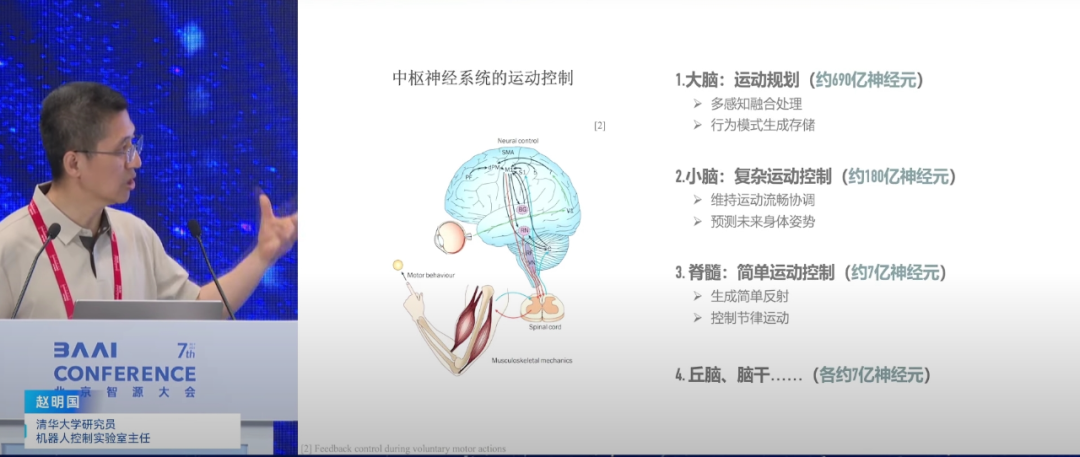
为应对泛化难题,赵明国提出了一套创新研究方法。团队借鉴生物的被动稳定性,设计了能耗低、对环境变化不敏感的机器人本体与步态,通过增加弹簧和虚拟斜坡,使机器人在不同地形上自然稳定。此外,团队还提出了类脑控制框架,一个受人脑神经系统启发的分层控制框架,通过脉冲神经网络和循环神经网络实现,具有高能量效率和高计算密度。
赵明国详细解释了生物神经系统的结构,并将其应用于机器人控制中。他提出了三个控制回路,模拟生物系统中神经信号的向上和向下传输特性,以实现快速、中等速度和慢速反应。
此外赵明国认为,人形机器人未来应该更注重智能与硬件结合,未来人形机器人想要在更多领域发挥更重要的作用,还需解决智能水平提升、硬件性能优化及人机交互改善等技术难题。
▍赵同阳:专注人形机器人核心技术自主研发 亲民价格抢占市场
众擎机器人创始人赵同阳分享了团队在人形机器人领域的最新进展。他表示,早期市场上,人形机器人技术主要由日本等少数国家掌握,价格昂贵。众擎机器人坚持自主研发,致力于打破技术壁垒,实现人形机器人的技术突破。
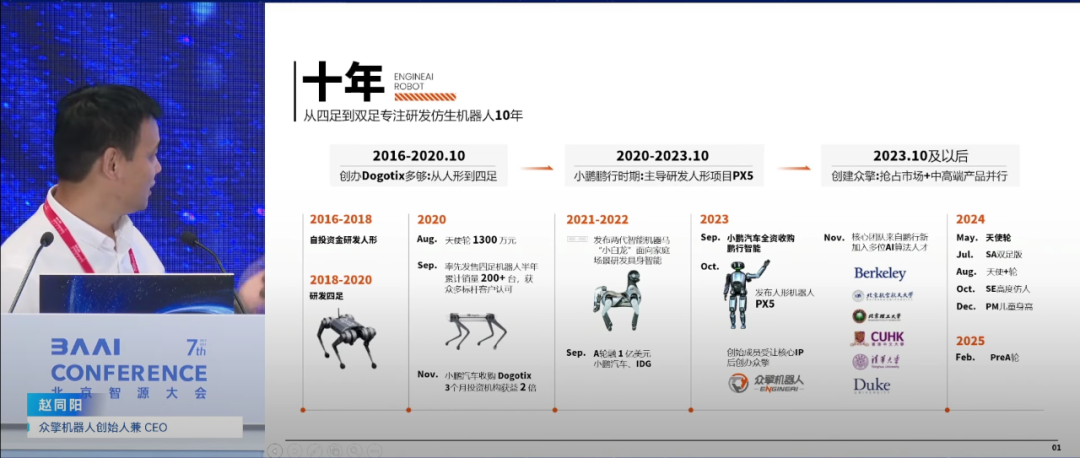
赵同阳介绍了团队如何自主研发核心部件,如电机、控制器、传感器等,逐步攻克技术难题,实现了人形机器人的稳定行走和奔跑。他强调,产品创新不仅体现在技术上,也体现在人性化设计和用户体验上。团队要求机器人行走自然流畅,动作协调,以接近人类表现为目标。
回顾创业历程,赵同阳提到,团队从独自奋斗开始,逐步成立公司、组建团队,并经历了被收购和再次创业的过程。他指出,资金、人才和市场是创业过程中的关键因素。团队通过自身努力和吸引优秀人才,逐步解决了这些问题。他强调了团队管理的重要性,认为优秀团队应具备共同目标、互补技能和良好沟通协作能力。在团队管理中,他注重扁平化管理,鼓励团队成员提出创新想法并参与决策。

在推出第一款机器人产品时,团队注重价格亲民和市场定位。通过市场调研和用户需求分析,团队确定了目标用户群体和功能设计。推出的机器人产品价格适中,适合高校和个人购买,目的在于推动整个行业的快速成长。这种市场定位策略使团队在竞争激烈的市场中脱颖而出。
赵同阳认为,随着技术进步和成本降低,机器人将在更多领域得到应用和推广。他提到,未来机器人将更加智能化、人性化,并具备更强的自主决策能力。
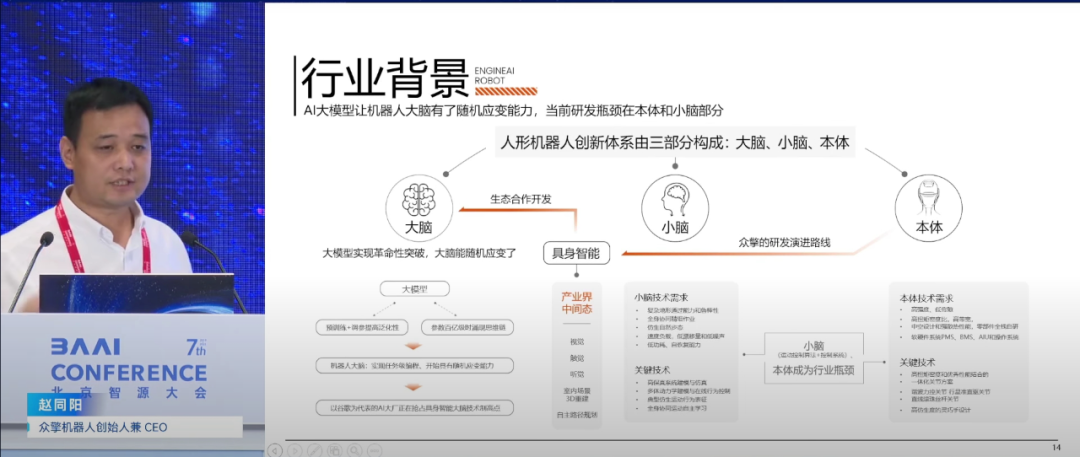
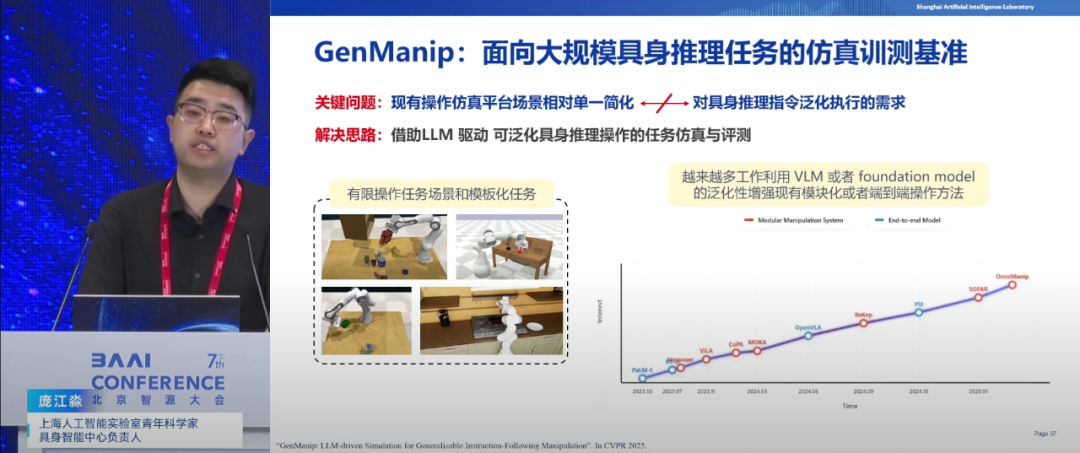
▍庞江淼:通过仿真技术生成合成数据 有效实现成本优化和零样本泛化
上海人工智能实验室青年科学家负责人庞江淼认为,人工智能算法需解决本体泛化、任务泛化和场景泛化三大核心问题,这是与传统机器人技术的关键区别。在数据层面,合成数据因其可高效生成和场景编辑能力,在促进本体泛化和场景泛化上具有显著优势;而真实数据则更有助于任务转化。庞江淼强调,通过仿真技术生成合成数据,并减少真实数据采集量,是实现成本优化和零样本泛化的重要途径。
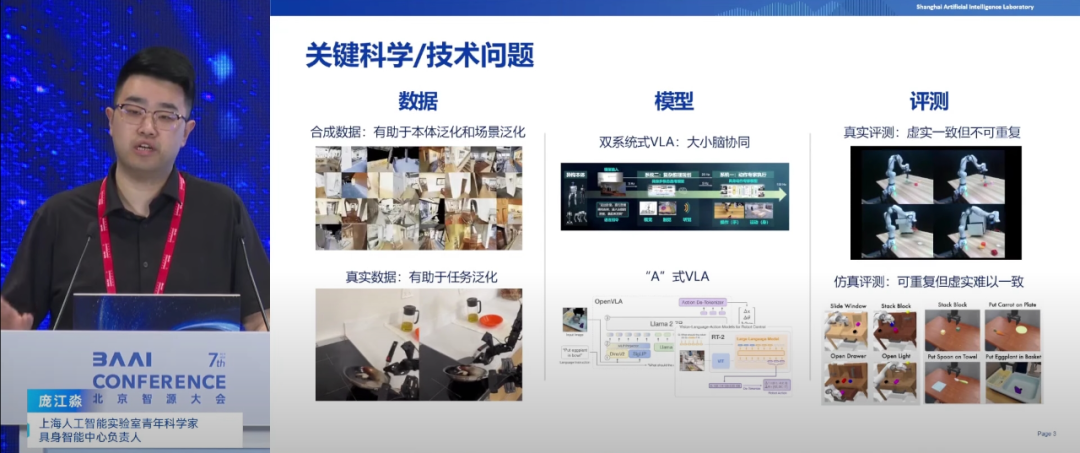
模型方面,庞江淼讨论了VLA(视觉-操作-语言模型)的多种实现方式,特别指出基于动态大模型预训练权重和添加Action Encoder的方法更具潜力。同时,他也提到了如何保持模型的语言交互能力并有效添加Action能力,是当前研究的重要方向。
评测体系上,庞江淼强调了建立公正、可重复的任务评测体系的重要性。尽管真实世界评测不可重复,但仿真环境为此提供了可能。此外庞江淼还介绍了通过编程生成多样化数据资产,用于机器人自主轨迹生成和技能泛化的实践案例。在导航和操作方面,庞江淼介绍了虚实结合技术在实现零样本泛化和动态环境处理上的优势,以及视觉预测引导动作执行在提升模型泛化能力上的作用。
▍仉尚航:探索开放世界具身多模态大模型新范式
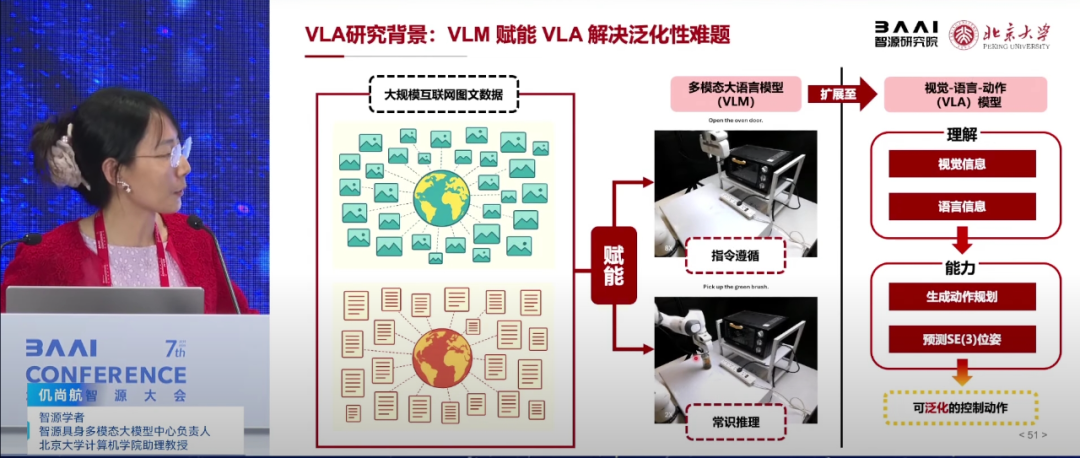
北京大学助理教授仉尚航在分享中探讨了开放世界具身多模态基础模型与系统的研究进展。她指出,随着大模型技术的兴起,人工智能与机器人技术迎来了新的融合点,推动了具身智能研究的新范式。

仉尚航强调了当前具身大模型面临的挑战,即如何实现跨本体、跨场景和泛化的具身智能。她提到,已有研究呈现出百花齐放的状态,包括端到端技术路线、分层技术路线等。北京大学团队基于人类快慢系统思维方式,提出了分层快慢系统框架,通过大脑模型(负责推理)和小脑模型(负责具体动作执行)的协作,实现了模块化、可解释性强的具身智能系统。
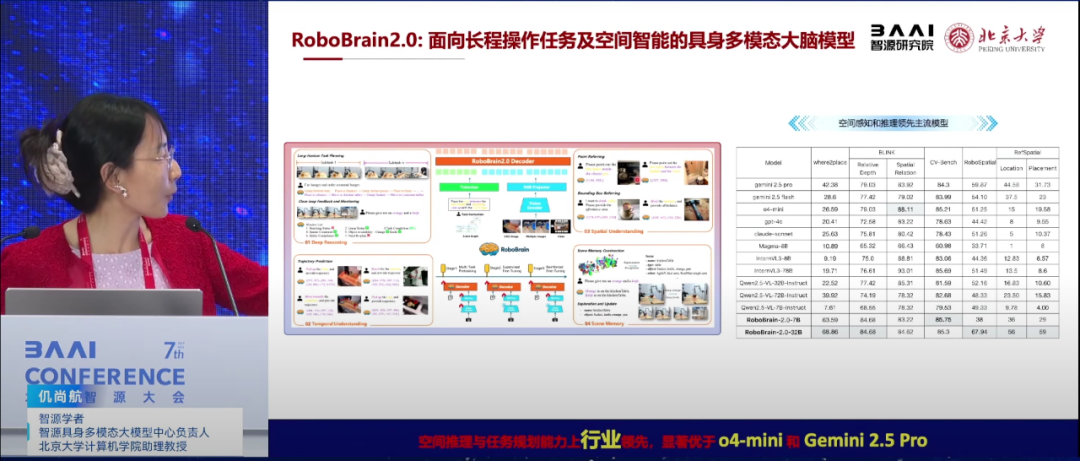
在大脑模型的设计上,仉尚航团队构建了面向具身智能的VLM(视觉语言模型),并强调其应具备任务规划、区域感知和轨迹预测三大能力。为此,团队专门构建了具身大脑数据集,并通过两阶段的训练策略,使模型既保持常识知识推理能力,又具备机器人的三大核心能力。

仉尚航还介绍了团队在端到端快慢系统方面的研究,特别是Hybrid VLA和Fast in Slow两个工作。Hybrid VLA通过统一框架融合扩散生成和自回归预测,实现了动作预测的相互增强;而Fast in Slow则首次将快慢系统一体化到VLA模型中,通过系统一(快速动作生成)和系统二(高级任务推理)的协同工作,提高了模型的频率和推理能力。
此外,仉尚航强调了模型评测的重要性,并介绍了团队提出的Robobench和Real bench两个评测基准,用于全面评估具身智能模型的性能。
▍唐剑:“慧思开物”平台如何让机器人像人一样思考与行动?
北京机器人创新中心CTO唐剑分享了北京人形机器人创新中心在具身智能方向上的进展,并介绍了创新中心在具身智能领域的两大核心任务:一是研发通用人形机器人本体,二是构建软件平台“慧思开物”,该平台颠覆传统机器人应用开发模式,实现一脑多能、一脑多机的通用具身智能。
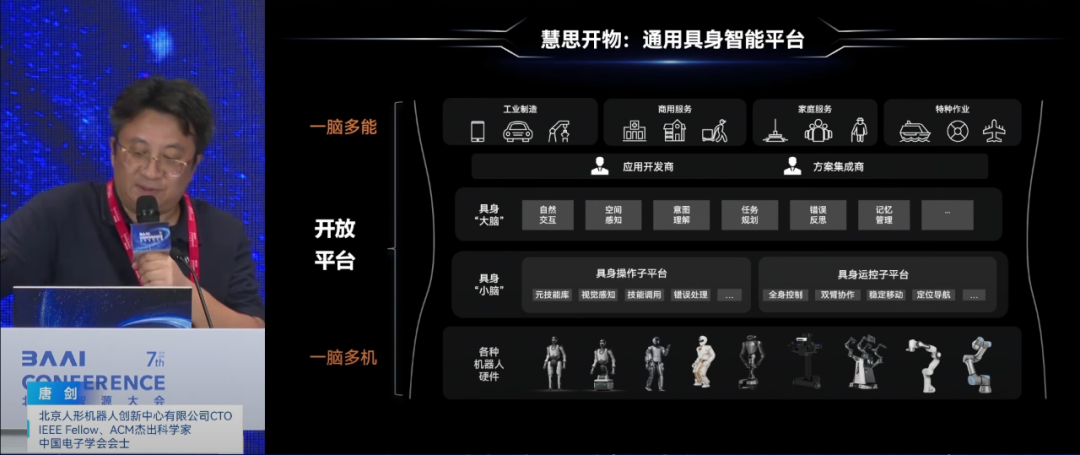
“慧思开物”平台由具身大脑和具身小脑组成,大脑负责自然交互、空间感知、意图理解和任务规划,小脑则负责操作控制和运动控制。平台通过构建技能库,利用端到端的VLA模型实现各种动作,覆盖物理世界的绝大部分任务。
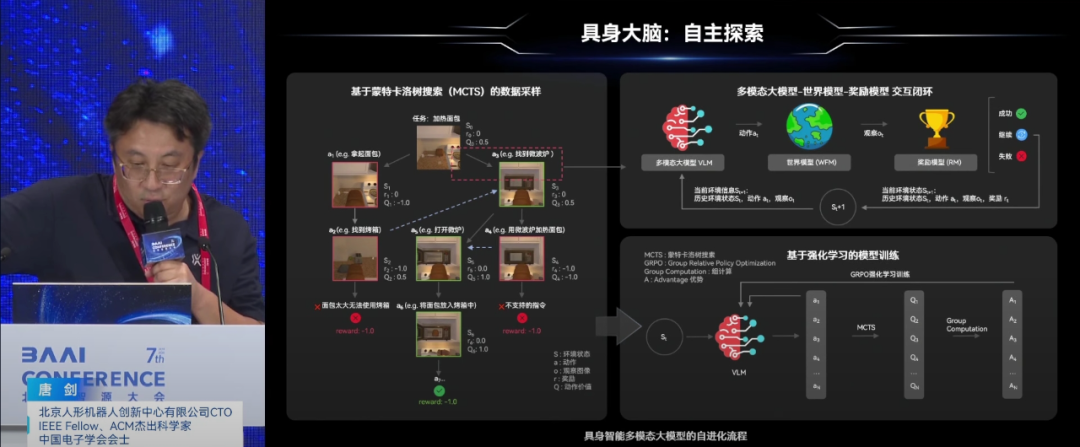
在技术实现上,创新中心采用了基于蒙特卡洛搜索的任务规划方法,结合世界模型进行模拟和奖励评估,提高了任务规划的精准度和效率。同时,平台还注重数据的自动清洗、标注和治理,构建了高质量的具身智能数据集,支持虚实数据结合的训练方式。

唐剑还介绍了创新中心在机器人自主导航、操作技能及全身运动控制等方面的研究成果,并展示了在多个场景下的应用案例。在具身智能的技术发展趋势上,唐剑强调了自主探索、自主学习、强泛化能力及通用全身运动控制器的重要性。
来源:具身智能大讲堂
(文:机器人大讲堂)