

今天是2025年7月1日,星期二,北京,晴
今天是2025年下半年的第一天,新的起点,我们继续看技术。
从评估角度看多模态RAG中的文档信息增强,逐步整合跨模态输入(文本、图像、字幕、OCR)后对应的相应影响,虽然说,这种范式看起来像是去年的,但温故而知新。
另外,来看看一个问题,关于dify是否应该被抛弃的一些思考?还是要分具体使用场景去看。
一、从评估角度看多模态RAG中的文档信息增强
来看最近的工作《Evaluating VisualRAG: Quantifying Cross-Modal Performance in Enterprise Document Understanding》,https://arxiv.org/pdf/2506.21604,VisualRAG的多模态评估框架,使用来自多个公司HR知识库的企业文档数据集,包含约200篇文章,涵盖8个主要功能领域,如福利注册流程、保险信息、休假政策等。
看两个点,一个是实验环境,一个是实验结果。
1、实验环境
这个visrag的核心就是充分利用好文档内部的各个元素,把图像进行文本化,如下图所示:
提出的方法(顶部,绿色背景)通过从PDF文档中提取并处理文本和视觉内容,增强了信息检索能力。
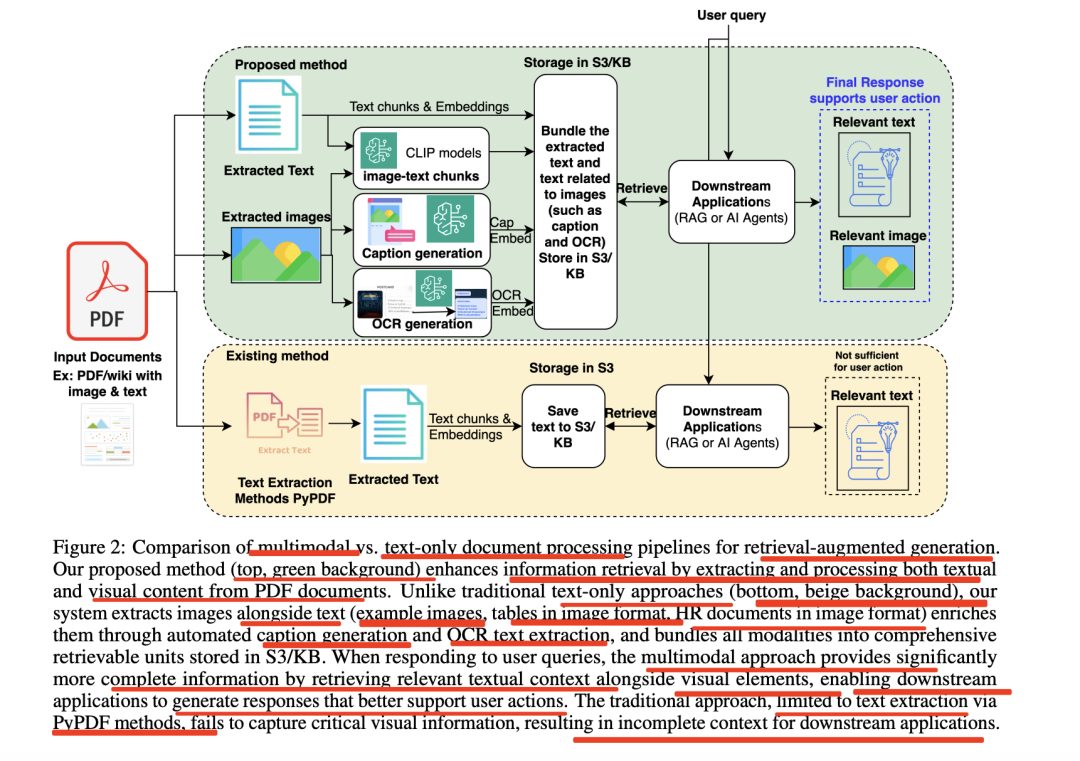
不同于传统的纯文本方法(底部,米色背景),系统同时提取文本和图像(如图片示例、表格以图像形式存在的人力资源文档等),通过自动生成标题和OCR文本提取对其进行丰富,并将所有模态整合为可检索的综合单元存储于S3/KB中。
在响应用户查询时,传统方法仅依赖PyPDF技术进行文本提取,无法捕捉关键的视觉信息,导致下游应用获取的上下文不完整。
多模态方法通过检索相关文本上下文及视觉元素,提供了更为完整的信息,使得下游应用能生成更有效支持用户动作的响应。
2、评估结论
采用四种逐步增强的方法进行评估:仅文本、文本+图像、文本+图像+标题、文本+图像+标题+OCR。
其中,三种标题生成方法:BLIP、Transformer-GPT2、Claude3.5Sonnet模型/Haiku3.5或NovaProLLM模型的基于大语言模型的标题生成。
每种方法的评估结果通过精确短语匹配、词重叠、CLIP嵌入比较和语义相似性等方法进行综合评分。
看下效果:
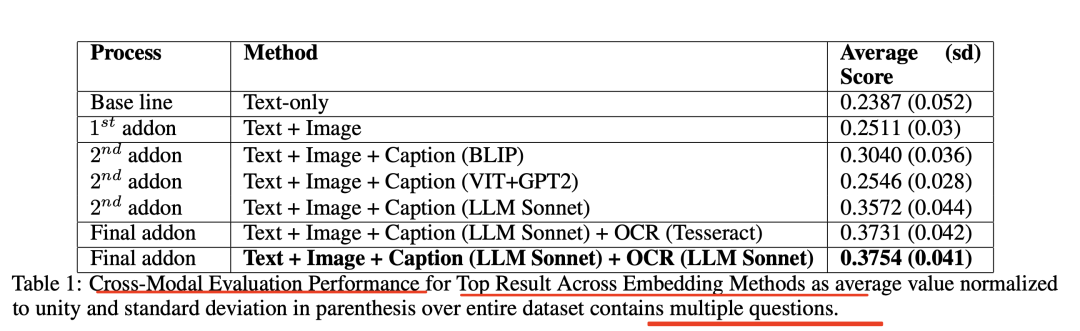
其中:
文本+图像:相较于仅文本方法,文本+图像方法的平均得分提高了5.2%,达到0.2511;
文本+图像+标题:使用Claude3.5Sonnet生成标题的方法得分最高,达到0.3572,相较于仅文本方法提高了42.3%;
文本+图像+标题+OCR:最优模态权重(30%文本,15%图像,25%字幕,30%OCR),得分最高,达到0.3754,相较于仅文本方法提高了**57.3%**。
二、关于dify是否应该被抛弃的一些思考?
使用dify这类平台搭建RAG等应用除了很容易达到上限外,还有什么缺点?如果真的要商用,打造可用的产品,是否应该自己去搭建?抛弃掉dify? dify适合做什么,不适合做什么?
实际上,如果要回答这些问题,则需要对Dify的特点和定位摸清楚。
先说下结论:
Dify是“AI应用快速试验田”,而非生产级精密工具。优势在效率,劣势在深度。短期需求:用Dify验证后,逐步替换瓶颈模块。在PoC阶段用Dify测试,再根据性能瓶颈决定模块替换或迁移,避免“全盘推翻”或“将就妥协”。
这里面的支撑逻辑是什么?
由于是个工具标品,所以很多都是内置封装最小化配置,从文本切分、排序到大模型,大多的策略都并不能解决高精度场景。
例如,Dify的RAG文档处理效果一般,特别是PDF表格识别问题严重,导致召回失败。而且切割策略并不先进,只能使用固定的正则表达式切割,对于普通用户来说操作困难,多路召回的效果也不理想,关键词召回实际上效果很差,基本依赖向量检索,所以,这个就是很容易达到上限。
而对于是否应该自己自研搭建,建议根据需求复杂度决定。
简单场景用Dify快速验证,复杂或高性能需求则需自研。提到结合部署方案,比如用Dify做前端+RAGFlow或者mineru处理文档。
当然,对于用户而言,还是要因地制宜,例如,技术能力弱、需求简单用Dify,复杂逻辑、长期投入则选自研。
一般来说,需要权衡开发效率与定制需求,Dify适合原型和简单应用,但商用产品若涉及高性能或复杂处理,可能需要自研或者魔改其他。
我们落地时,往往看的是这个东西的下限,并且要做到商用,其实很复杂,需要做许多优化策略,但是,具体选择什么,全凭自己在做的事情,没有绝对。
参考文献
1、https://arxiv.org/pdf/2506.21604
(文:老刘说NLP)