


还在使用传统的熵最小化作为模型自训练的目标?还在为缓慢降低且不稳定的模型不确定性而担忧?
来自北京大学与香港中文大学的最新研究,提出 ReCAP 框架,成功打破了 Entropy 在 Test-Time Training 的性能瓶颈,在多个场景和数据集挑战中全面超越当前的熵最小化方法,几乎零成本提升在下游任务的泛化性能!

前言:“自信”过头了?模型陷入熵最小化陷阱!
测试时训练(Test-Time Training/Adaptation)已然成为模型训练后在测试阶段微调的最重要方法之一,极大程度上增强了模型在下游应对不同下游任务的泛化能力。当前最常见的方法是熵最小化策略,以求让模型扩大自己输出的置信度。
然而,在复杂多变的测试条件下,熵最小化开始暴露出致命缺陷:模型往往对单一样本盲目“自信”,而忽视了其周围样本的预测一致性。这种局部预测的不稳定性会导致熵优化方向之间相互冲突,扰乱模型收敛过程,最终适得其反。
因此,我们迫切需要一种新的目标函数——它不仅能有效降低模型不确定性,更应能协调局部样本间的预测稳定性。

论文标题:
Beyond Entropy: Region Confidence Proxy for Wild Test-Time Adaptation
论文作者:
Zixuan Hu, Yichun Hu, Xiaotong Li, Shixiang Tang, Ling-Yu Duan
所属机构:
School of Computer Science, Peking University, Peng Cheng Laboratory, The Chinese University of Hong Kong
收录会议:
ICML 2025
开源地址:
https://github.com/hzcar/ReCAP
论文链接:
https://arxiv.org/abs/2505.20704
联系方式:
hzxuan@pku.edu.cn

区域置信度:熵最小化背后的“隐形变量”是局部一致性
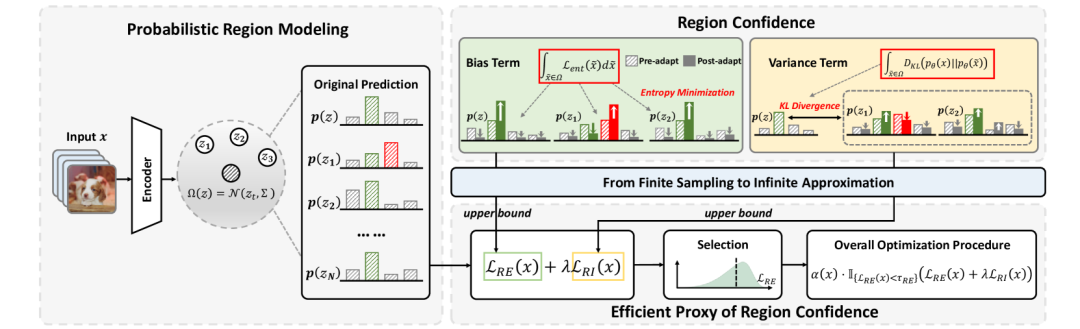
在深入分析现有方法局限性的基础上,来自北京大学与香港中文大学的研究团队提出了全新框架 ReCAP(Region Confidence Adaptive Proxy),以更加精准的方式刻画模型预测中的不确定性与稳定性之间的内在联系。
熵最小化的核心思想是通过引导预测概率向主要的类别集中收敛,其有效性很大程度上依赖于局部一致性,也就是附近的点应该有相似的预测概率。在分布偏移较复杂或者数据有限的场景中,局部不一致现象非常普遍,此时熵最小化反而会成为性能崩溃的罪魁祸首。
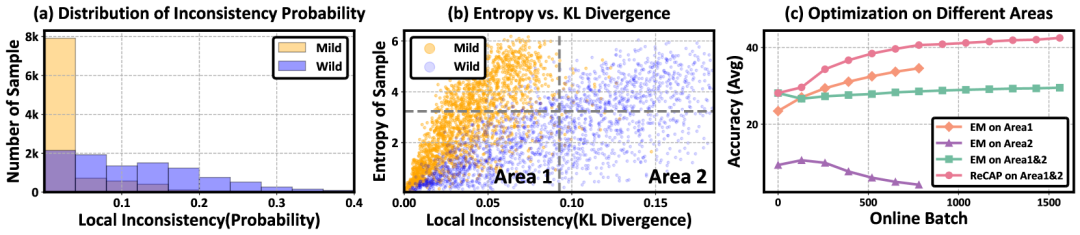
为此,团队引入了区域置信度(Region Confidence)的全新定义。它不再聚焦于单一样本的置信度提升,而是在其局部区域内同时衡量整体熵水平与一致性程度,具体形式如下:
对于样本 和其一个局部区域 , 在 上的区域置信度 (Region Confidence) 定义为:
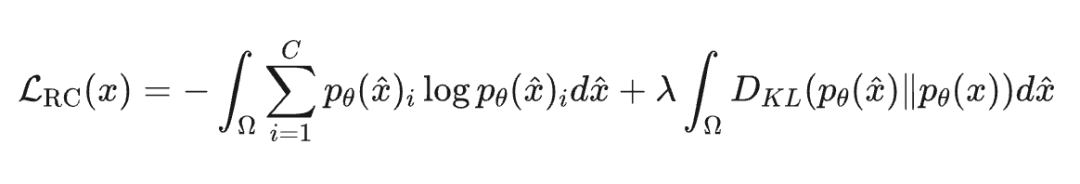
第一项熵损失函数代表了优化方向与区域目标之间的偏差,保留了熵最小化扩大置信度的思想。
第二项与中心点预测分布的 KL 散度代表了局部区域内不一致预测概率的方差,鼓励模型在局部区域内保持一致性。
研究团队在此采用积分,意味着理论可以在无限样本上整合损失项。

高效代理:ReCAP优化区域置信度几乎零成本
为了将“区域置信度”这一理论目标落地为可高效优化的形式,研究团队设计了两项关键技术创新:
区域概率建模机制:将特征空间中的局部区域视为一个高斯分布,动态建模预测概率的变化趋势,提取区域内的语义不确定性。
有限-无限近似理论推导:创新性地提出“区域置信代理损失”,无需采样、无额外前向传播,即可高效近似原始优化目标中难以计算的熵积分和KL散度项,大幅提升优化效率。
具体来说,给定一个特征 及其局部区域 ,该局部区域服从高斯分布 ,研究团队证明了两个重要结论:
整个分布上的熵损失期望具有上界:
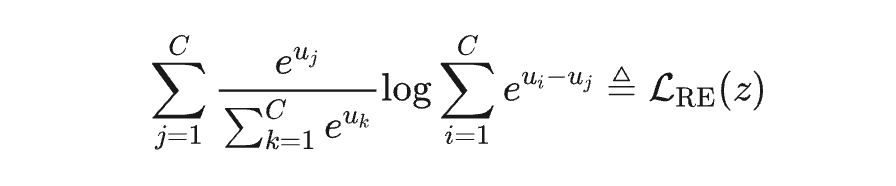
输出概率与中心概率之间的 KL 散度的期望值具有上界:
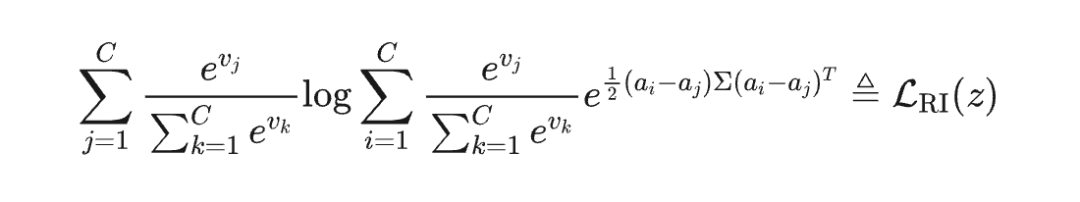
因此只需要最小化 和 即可,此运算开销几乎可以忽略不计。
在样本过滤时,使用区域熵 来识别可靠的样本参与优化:
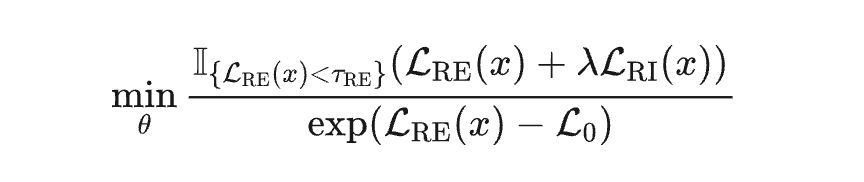
分母表示加权项, 表示区域熵的阈值, 是超参数。

ReCAP:重塑测试时训练范式的“加速引擎”
研究团队重磅推出的 ReCAP 框架,不仅给出了熵最小化训练困难的理论分析,也给出了区域内模型预测不确定性的度量方法。
更关键的是,ReCAP 拥有极强的模块兼容性与方法泛化性:它无需改变原有网络结构,可无缝集成到主流的 TTT 框架中,以替换原有的熵目标函数,轻松提升性能。
文章对多种数据偏移,多种测试场景做了综合实验分析,均取得显著的性能提升:
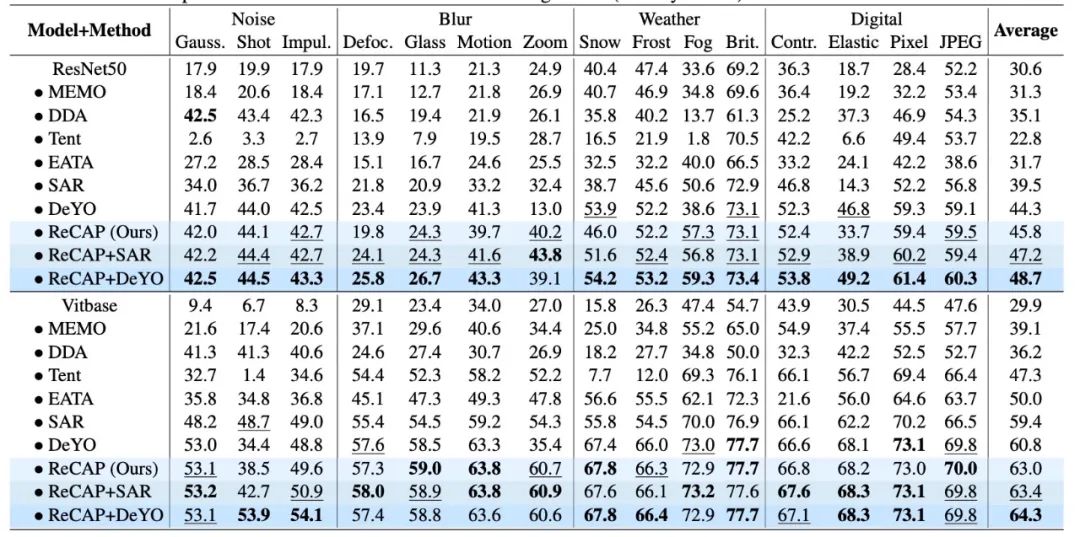
相较于传统熵最小化方法,ReCAP 在多个关键维度上实现突破:
1. 强鲁棒性:数据限制和复杂偏移下更高效:在多种场景和数据集下,ReCAP 均显著优于现有SOTA方法,带来 2~5 个百分点的性能提升。
2. 强兼容性:几行代码替代原有熵目标:ReCAP 可直接作为 drop-in 替代模块,嵌入到各种框架中,无需任何结构或训练流程修改,即可取得增益。
3. 高效率:近零成本、无冗余操作的理论优化路径:借助推导出的上界代理损失,ReCAP 无需使用如扩散模型、数据增强、生成式补全等昂贵操作,显著降低测试时训练成本,适合部署在边缘设备和工业环境中。

结语:在更多场景和任务中积极探索区域置信度的效果
ReCAP 框架的提出是对测试时训练目标函数设计的一次重新审视与范式突破。它不仅揭示了传统熵最小化方法在复杂环境下的局限性,更通过区域置信代理优化,兼顾了不确定性抑制与局部预测稳定性,实现了理论优雅、实践高效的完美结合。
当前,ReCAP 已在图像分类领域多个高强度扰动数据集(如 ImageNet-C、ImageNet-R、VisDA)上展现出显著优势。而我们相信,这只是一个开始——
1. 在目标检测、语义分割、视频理解等任务中,局部区域一致性同样扮演着关键角色;
2. 在 3D 视觉、医学图像、工业缺陷检测等现实场景中,数据稀缺性与分布偏移问题尤为突出,ReCAP 的无监督适应潜力亟待释放;
3. 在更大尺度、更高复杂度的模型体系中,ReCAP 所倡导的“区域视角”,或许正是提升稳健性与可解释性的关键。
研究团队也将持续开源和完善相关工具链,欢迎更多研究者和工程团队将“区域置信”理念扩展到更多测试时适应应用中,共同推动更稳健、更通用的视觉模型构建路径。
(文:PaperWeekly)