

近日,法国AI实验室Kyutai正式开源其高性能TTS语音模型:Kyutai TTS。

它是一款基于Delayed Streams Modeling(DSM)框架的实时文本转语音(TTS)模型,支持流式文本输入、超低延迟和高保真语音生成。
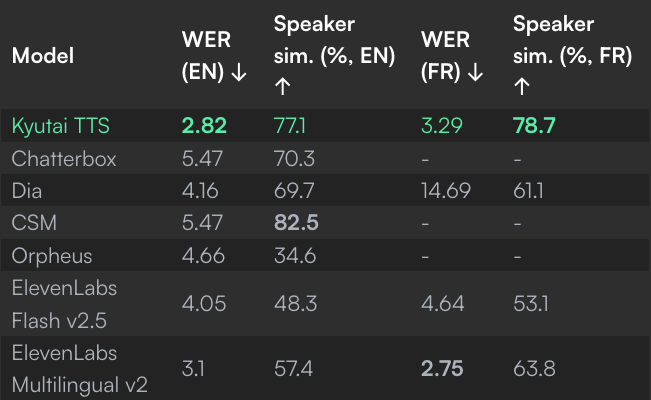
1.6B参数,英语/法语WER低至2.82/3.29,语音相似度77.1%/78.7%,支持流式文本输入,适配实时交互和长文本生成。
使用L40S GPU,可同时处理32个请求,延迟为 350毫秒。
模型亮点
-
• 流式文本输入:逐词处理文本,生成音频无需完整输入,适配实时交互。 -
• 超低延迟:L40S GPU上,32并发请求延迟仅350ms。 -
• 高保真语音:英语WER 2.82%,法语3.29%;说话者相似度77.1%(英语)、78.7%(法语)。 -
• 时间戳输出:提供单词级时间戳,适合实时字幕或中断检测。 -
• 长文处理:轻松处理长文章,无需逐句拆分。
快速入手
可在Kyutai TTS主页直接体验其效果。
同时官方为不同的使用场景也提供不同的 Kyutai TTS 实现。
方式一:PyTorch – 用于研究和调试
# From stdin, plays audio immediately
echo "Hey, how are you?" | python scripts/tts_pytorch.py - -
# From text file to audio file
python scripts/tts_pytorch.py text_to_say.txt audio_output.wav方式二:Rust – 用于生产环境
可通过该方式提供Kyutai TTS服务,基于强大Rust服务器可通过websockets提供对模型的流式访问。
通过以下命令安装moshi-server
cargo install --features cuda moshi-server然后可以通过以下命令使用此存储库中的配置文件启动服务器。
moshi-server worker --config configs/config-tts.toml一旦服务器启动,就可以使用下面脚本连接到它。
# From stdin, plays audio immediately
echo "Hey, how are you?" | python scripts/tts_rust_server.py - -
# From text file to audio file
python scripts/tts_rust_server.py text_to_say.txt audio_output.wav方式三:MLX – 用于在iPhone和Mac上进行设备端推理。
MLX是苹果的机器学习框架,允许在苹果M芯片上使用硬件加速。当流式传输输出时,如果模型速度不够快,无法实时处理,可以使用–quantize 8或–quantize 4标志来量化模型,从而加快推理速度。
# From stdin, plays audio immediately
echo "Hey, how are you?" | python scripts/tts_mlx.py - - --quantize 8
# From text file to audio file
python scripts/tts_mlx.py text_to_say.txt audio_output.wav该方式需要安装 moshi-mlx包。安装指令 uvx --with moshi-mlx
应用场景推荐
-
• 实时语音助手:结合Unmute(unmute.sh),支持低延迟对话。 -
• 内容创作:为长文章生成播客音频。 -
• 字幕生成:时间戳支持,适配视频编辑。 -
• 本地推理:MLX支持iPhone/Mac,隐私敏感场景。
写在最后
不仅支持实时语音流式输出,还能输出逐字时间戳,非常适合播报、字幕、语音代理等复杂应用场景。
Kyutai TTS 是当前少有的支持“流式生成 + 时间戳 + 多语言”的开源 TTS 模型,音质真实、延迟极低,是 AI 创作、语音产品落地的理想选择。
虽然目前仅支持英语、法语,但是一款广受好评的TTS模型(闭源期间)。
GitHub 项目地址:https://github.com/kyutai-labs/delayed-streams-modeling
TTS 项目地址:https://kyutai.org/next/tts

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)