

扩散语言模型与传统的自回归模型(如GPT系列)逐个生成单词或字符的方式不同,主要通过逐步去除文本中的噪声来生成高质量的文本,能在单次迭代中生成多个单词,生成效率也就更高。
但在实际应用中多数开源的扩散语言模型在推理效率上往往不如自回归模型,主要是由缺乏键值(KV)缓存支持和并行解码时生成质量下降两大原因造成。
所以,英伟达、香港大学和麻省理工的研究人员联合提出了Fast-dLLM来解决这些难题。

KV缓存是自回归模型中用于加速推理的关键技术。通过存储和重用先前计算的注意力状态,减少了重复计算,从而显著提高了生成速度。而扩散语言模型由于是双向注意力机制,直接应用KV缓存并不容易。
在Fast-dLLM架构中,文本生成过程被划分为多个块,每个块包含一定数量的token。这种块状生成方式的核心在于,允许模型在生成一个块之前,预先计算并存储其他块的KV缓存。
在生成过程中,模型会重用这些缓存的KV激活,从而避免了重复计算。这种近似KV缓存机制的关键在于,它利用了KV激活在相邻推理步骤中的高度相似性。
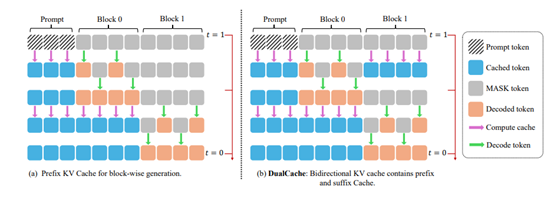
例如,在生成一个块之前,模型会针对其他块展开计算,并存储对应的 KV Cache,以便后续步骤能够进行重用。当完成一个块的生成后,再重新对所有块的KV Cache 予以计算。这种以块为单位的生成方式,在保障模型性能基本稳定的同时,成功减少了大量冗余计算。
尽管KV缓存机制显著提升了扩散语言模型的推理速度,但在并行解码时,生成质量往往会下降。这是因为扩散型模型在解码时假设了条件独立性,而实际上,标记之间可能存在复杂的依赖关系。这种依赖关系的破坏会导致生成文本的连贯性和准确性下降。
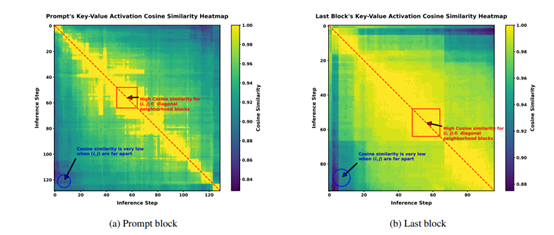
为了解决这一问题,Fast-dLLM提出了一种基于置信度的平行解码策略。Fast-dLLM在每个解码步骤中计算每个标记的置信度,并选择置信度超过阈值的标记进行解码。如果没有标记的置信度超过阈值,则模型会选择置信度最高的标记进行解码,以确保解码过程能够继续进行。
这种基于置信度的解码策略的关键在于,它能够在高置信度的情况下,安全地进行并行解码,而不会引入过多的错误。
为了测试dLLM性能,研究人员使用NVIDIA A100 80GB GPU对LLaDA和Dream两种扩散语言模型进行全面评估,测试基准包括GSM8K、MATH、HumanEval和MBPP四个数据集,涵盖数学推理与代码生成等任务。
在KV缓存机制测试中,块大小设为4至32。结果显示,块大小32时吞吐量与准确性最佳,吞吐量达54.4 tokens/s,准确率78.5%;而块大小8时吞吐量降至49.2 tokens/s,准确率略升至79.3%,但资源消耗较大。块大小64则因上下文不匹配导致准确率下降。
并行解码测试采用置信度阈值0.5至1.0,默认值0.9。
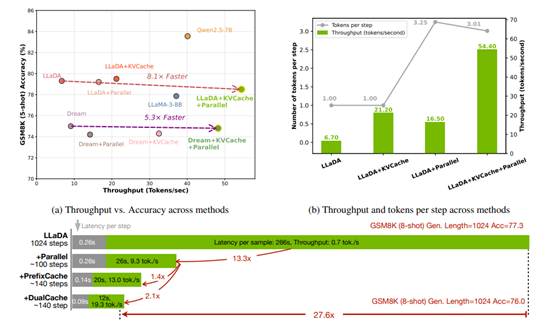
动态阈值策略优于固定token数基线。以GSM8K(5-shot)为例,阈值0.9时每步处理2个token,准确率78.5%;固定解码每步2 token时准确率79.2%。降低阈值至0.7时,每步处理4 token,准确率仍达79.3%,显示策略灵活性强。
整体吞吐量方面,LLaDA模型GSM8K(5-shot,生成长度256)任务中,仅用KV Cache加速3.2倍至21.2 tokens/s,并行解码加速2.5倍至16.5 tokens/s,二者结合加速8.1倍至54.4 tokens/s。生成长度1024时端到端加速达27.6倍。
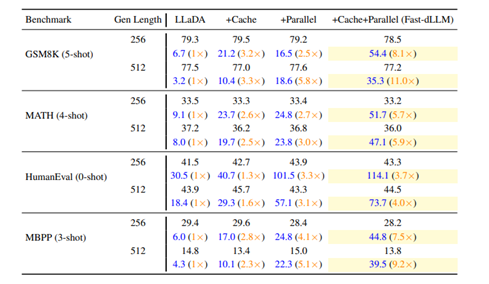
Dream模型MBPP(3-shot,生成长度512)任务中,结合策略加速7.8倍至73.6 tokens/s;GSM8K(5-shot,生成长度512)加速5.6倍至42.9 tokens/s。
准确性方面,LLaDA任务中准确率仅下降0.8个百分点至78.5%;Dream的HumanEval任务准确率反升至54.3%。所有测试准确率波动均在1-2个百分点内,表明Fast-dLLM在加速同时有效保持生成质量。
(文:AIGC开放社区)