
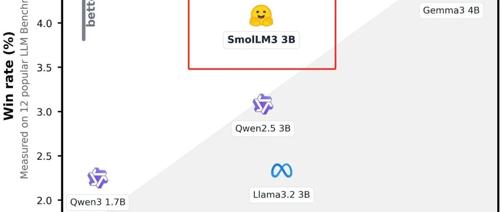
今天凌晨,全球著名大模型开放平台Hugging Face开源了,顶级小参数模型SmolLM3。
SmolLM3只有30亿参数,性能却大幅度超过了Llama-3.2-3B 、Qwen2.5-3B等同类开源模型。拥有128k上下文窗口,支持英语、法语、西班牙语、德语等6种语言。支持深度思考和非思考双推理模式,用户可以灵活切换。
值得一提的是,SmolLM3已经把架构细节、数据混合方式、三阶段预训练以及构建混合推理模型的方法全部开放了,有助于开发人员深度研究或优化自己的模型。
基础模型:https://huggingface.co/HuggingFaceTB/SmolLM3-3B-Base
推理和指导模型:https://huggingface.co/HuggingFaceTB/SmolLM3-3B
Hugging Face的联合创始人Clement Delangue和Thomas Wolf都对该模型进行了强烈推荐,认为是3B领域的SOTA模型,也非常适合用于开源模型的研究。


SmolLM3架构简单介绍
在架构方面,SmolLM3 采用了 transformer 解码器架构,与 SmolLM2 类似,基于 Llama进行了一些关键修改以提高效率和长上下文性能。使用了分组查询注意力,16 个注意力头共享 4 个查询,在保持全多头注意力性能的同时节省了推理时的内存。
训练中采用了文档内掩码,确保同一训练序列中不同文档的标记不会相互关注,有助于长上下文训练。还运用了 NoPE 技术,有选择地从每第 4 层移除旋转位置嵌入,改善长上下文性能而不影响短上下文能力。

训练配置方面,模型参数为 3.08B,初始化采用 N (0, std=0.02),有 36 层,Rope theta为50k,序列长度4096,批处理大小236万tokens,优化器为AdamW(eps=1e-8,beta1=0.8,beta2=0.95),峰值学习率 2e-4,梯度裁剪 1.0,权重衰减0.1。
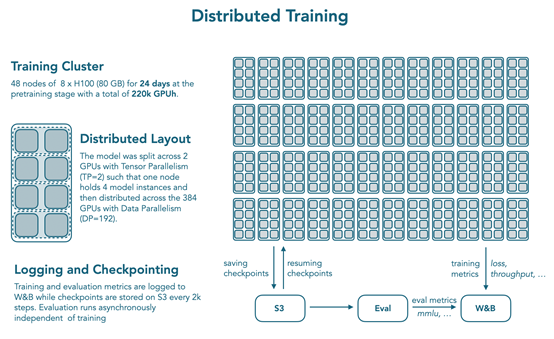
参考 OLMo 2,从嵌入层移除权重衰减以提高训练稳定性。训练使用 nanotron 框架,datatrove 进行数据处理,lighteval 进行评估,在384块H100 GPU 上训练了 24天,分布式训练设置为 48 个节点,每个节点8个H100(80 GB),模型通过张量并行(TP=2)分布在 2 个 GPU 上,一个节点容纳 4 个模型实例,再分布到 384 个节点。
训练数据和三阶段混合训练方法
数据混合和训练阶段遵循 SmolLM2 的多阶段方法,采用三阶段训练策略,在11.2 万亿 tokens 上训练,混合了网络、数学和代码数据,且比例不断变化。
阶段 1 为稳定阶段(0T→8T tokens),建立强大的通用能力,网络数据占85%(12%为多语言),包括FineWeb-Edu、DCLM、FineWeb2 和 FineWeb2-HQ;代码数据占 12%,包括The Stack v2(16 种编程语言)、StarCoder2 拉取请求、Jupyter 和 Kaggle 笔记本、GitHub 问题和 StackExchange;数学数据占3%,包括FineMath3 + 和 InfiWebMath3+。
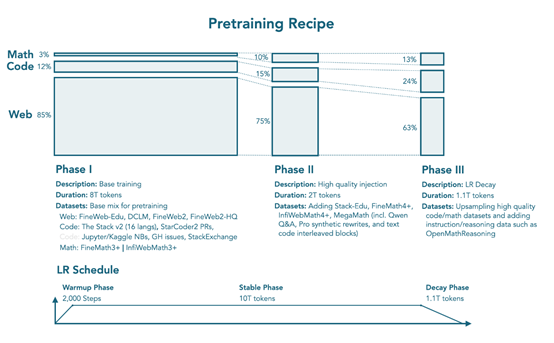
阶段 2 为稳定阶段(8T→10T tokens),引入更高质量的数学和代码数据集,同时保持良好的网络覆盖,网络数据占 75%(12% 为多语言),代码数据占15%(添加了 Stack-Edu),数学数据占 10%(引入了 FineMath4+、InfiWebMath4 + 和 MegaMath)。
阶段 3 为衰减阶段(10T→11.1T tokens),进一步增加数学和代码数据的采样,网络数据占 63%,代码数据占 24%(高质量代码数据的上采样),数学数据占13%,上采样数学数据并引入指令和推理数据集,如 OpenMathReasoning。
在中期训练中,进行了长上下文扩展和推理适应。长上下文扩展是在主要预训练后,额外训练 1000 亿 tokens 以扩展上下文长度,分两个阶段依次扩展上下文窗口,每个阶段500亿tokens,先从4k过渡到32k上下文,将 RoPE theta 增加到 150 万,然后从 32k 过渡到64k 上下文,将 RoPE theta 进一步增加到 500万,两个阶段都对数学、代码和推理数据进行了上采样。
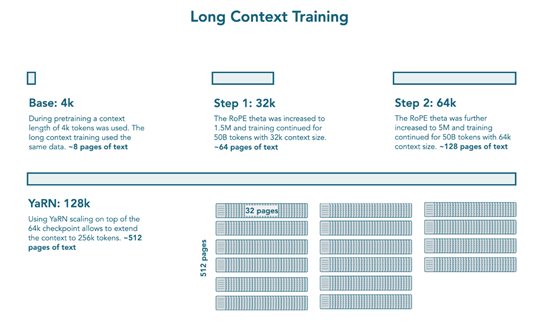
借鉴 Qwen2.5,使用 YARN 在训练上下文长度之外进行外推,推理时模型可处理高达 128k 的上下文(是 64k 训练长度的 2 倍扩展)。推理中期训练是在扩展模型上下文长度后,训练模型融入推理能力。中期训练数据集包含 350亿tokens,来自 Open Thought 的 OpenThoughts3-1.2M 和NVIDIA 的 Llama-Nemotron-Post-Training-Dataset-v1.1 的子集,使用 ChatML 聊天模板和包装打包,训练模型 4 个 epochs(约1400亿tokens),并将检查点用于后续的 SFT(监督微调)阶段。
后期训练中,构建了聊天模板,用户可通过在系统提示中包含<code>/think</code>和<code>/no_think</code>标志分别激活推理或非推理模式,在非推理模式下,会用空的思考块预填充模型的响应。
聊天模板还包含 XML 工具和 Python 工具两个不同的工具描述部分,提供了两种推理模式的默认系统消息以及包含日期、知识截止日期和当前推理模式的元数据部分,用户可通过在系统提示中使用<code>/system_override</code>标志排除元数据部分。
SFT和APO
SFT在推理中期训练阶段之后进行,该阶段在 1400 亿 tokens 的通用推理数据上训练模型,进而在数学、代码、通用推理、指令遵循、多语言和工具调用方面融合推理和非推理模式的能力。
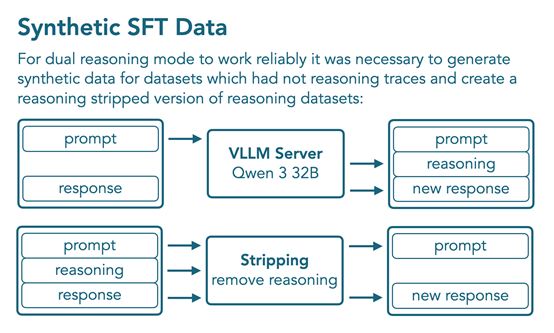
为解决某些领域缺乏包含推理轨迹的数据集的问题,通过在现有非推理数据集的提示下提示 Qwen3-32B 在推理模式下来生成合成数据。最终的 SFT数据集包含18亿tokens,其中 10 亿为非推理模式,8 亿为推理模式,包括12个非推理数据集和 10 个带有推理轨迹的数据集,使用 BFD打包训练 4 个 epochs(约 80 亿 tokens),对用户轮次和工具调用结果的损失进行掩码。
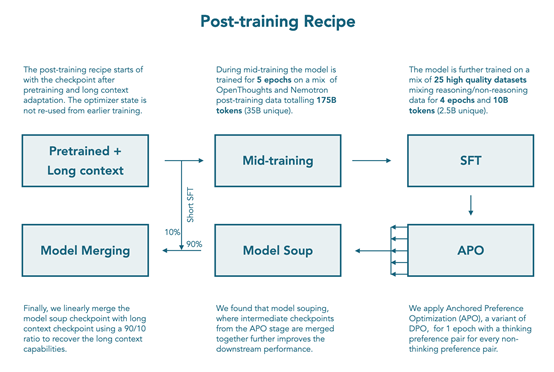
采用APO(锚定偏好优化)进行离策略模型对齐,这是直接偏好优化的一种变体,提供更稳定的优化目标。APO 步骤使用 Tulu3 偏好数据集(非推理模式)和新的合成偏好对(推理模式),合成偏好对由 Qwen3-32B 和 Qwen3-0.6B 生成。
由于在长上下文基准上观察到性能下降,采用模型合并来缓解使用 MergeKit 库,先将每个 APO 检查点创建一个模型 混合体,然后将模型混合体与具有强大长内容性能的中期训练检查点组合,APO 模型混合体和中期训练检查点的线性合并权重分别为 0.9 和 0.1,最终模型恢复了基础模型在高达 128k tokens 上下文上的 RULER 分数,并在广泛的任务中保持高性能。
(文:AIGC开放社区)