
“ RAG技术成本最低的方式就是把非结构化文档转换成markdown格式进行处理 。”
在大模型应用领域中——RAG技术应该属于一项基础技术,不论做什么业务基本都离不开RAG的存在;但RAG技术属于典型的入门五分钟,想做好却需要花费大量时间和精力,以及成本。
所以,今天我们就来讨论一下RAG技术在企业应用中的解决方案,既要考虑技术问题,也要考虑成本问题。
怎么做好RAG
RAG技术从整体上来说主要分为两块,一块是文档预处理,也就是把文档处理成向量格式,但需要尽量保证文档的语义完整性;其次,就是检索召回,具体要求是能快速并准确地召回需要的数据。
但从实践的角度来看,目前对RAG影响最大的是第一步——文档预处理,文档处理的质量越高,召回的精准度就越高。其实这一点也很好理解,在一个有完善管理系统的图书馆里找书,肯定会比在一堆没人管理的书堆里找书要快,要好。
那在文档预处理这块,主要存在的难点是什么?
在文档处理领域,主要存在两种数据形式,结构化数据和非结构化数据;结构化数据主要以excel这种二维表的形式存在,其处理起来相对比较简单;而非结构化数据的格式就比较多,并且比较混乱,比如说txt,word,pdf,markdown,ppt等多种形式。
结构化数据今天我们就不讨论了,因为其比较简单;所以,我们今天主要讨论的是非结构化数据,就以word文档为例。
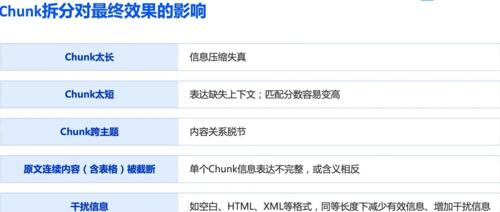
由于大模型有窗口上下文长度限制,并且从成本的角度考虑;文档处理首先需要进行文档切分,把文档按照长度,段落或其它方式拆分成多个小段。
但非结构化文档拆分的难点是其文档的结构,以word文档为例;文档内容可以是文字,图片,表格,结构图,架构图等多种形式。由于其文档的复杂性,就导致其文档处理起来相对比较复杂。
原因就在于,对人类来说,文档中的文字,图片和表格很好区分,但对大模型来说怎么区分那些是文字,那些是图片,那些是表格就有相当大的挑战性。虽然说现在有了多模态模型的存在,可以部门解决这个问题,但不论从成本,还是处理速度,亦或者是效果来看,都有点差强人意。
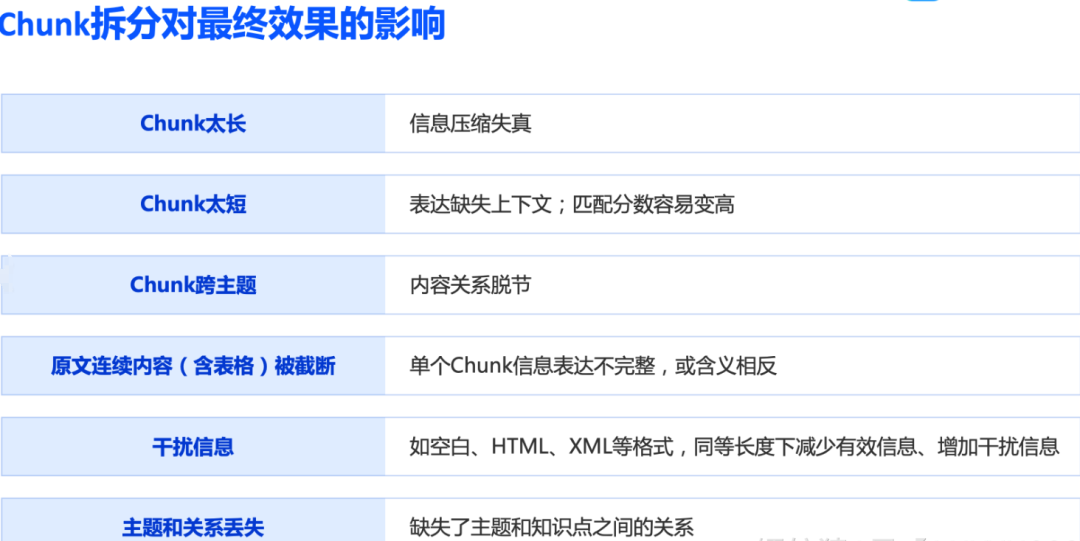
在文档中文字和图片需要分开进行处理,对长表格来说也需要保证表格的完整性;并且,要保证拆分之后的文档存在一定的关联性,否则很容易导致驴头不对马嘴。
举例来说,一个技术文档,一个运营文档,可能都存在前言,介绍这种段落;而在文档拆分之后,需要分清楚,那些段落是属于技术文档的,那些段落属于运营文档。
所以面对这种问题,目前比较好的解决方案是把这些文档转换成markdown格式;原因在于,虽然markdown文档也是非结构化数据,但markdown又一套属于自己的规范,比如说用一到多个#可以表示多个层级;也就是说markdown文档属于非结构化文档中,相对比较结构化的文档格式,这也是为什么目前各大模型厂商的前端展示格式主要以markdown为主。

在处理markdown文档时,可以把拆分的每段文档都带上其上级标题;比如说,一个RAG的技术文档,一级标题是RAG解决方案,二级标题可以是文档拆分,文档向量化,文档召回等等;当然,也可以根据不同的需要,存在三级标题,四级标题等等。
这样每个拆分的段落都携带上层一级或多级标题,这样就可以尽量保证每段文档的关联性。
然后在具体处理时,就可以根据段落进行向量化,如果段落超长,则可以对段落进行再次拆分,但一定要带上其上级标题。
而至于文档中存在的图片和表格,也需要进行特殊的处理,对表格来说主要是保证表格数据的完整性,在非长表格的情况下,尽量不要对表格数据进行拆分;而对于图片格式,可以使用OCR技术,读取图片中的数据并转换成文字,但这种处理方式会导致架构图,流程图等失去其本身的逻辑结构。
当然,也可以使用多模态模型或其它方式进行处理,但其整体上来看,效果不是特别好,但成本又特别高,并不是一个好的选择。
所以,在RAG中最好尽量避免处理带图片的文档,很多时候处理不好,反而会降低文档本身的质量,污染正常的文本数据,导致召回效果变差。
最后,需要注意的是RAG增强检索,并不限制文档数据的来源,也不一定非要使用向量检索;传统的数据检索技术同样可以应用于RAG技术中;在某些大数据量处理的RAG系统中,传统的检索技术依然占据着主导地位,原因就在于基于向量检索的速度问题,相对于传统检索方式会更慢。
(文:AI探索时代)