


论文标题:
Learning Deliberately, Acting Intuitively: Unlocking Test-Time Reasoning in Multimodal LLMs
论文链接:
https://arxiv.org/pdf/2507.06999
一句话理解:
本文介绍了一种名为 Deliberate-to-Intuitive (D2I) 的推理框架,旨在提升多模态大型语言模型(MLLMs)在复杂推理任务中的表现。文章的核心内容包括以下几个方面:
研究背景
多模态推理的挑战:多模态推理任务(如数学问题解决)需要模型同时处理文本和图像信息。然而,现有的多模态推理方法存在两个主要问题:
1.多模态对齐(Multimodal Alignment):模型需要准确理解图像和文本之间的关系,否则推理会受到影响。
2.训练成本和可扩展性(Training Costs and Scalability):许多方法依赖额外的数据标注或复杂的规则化奖励来提升推理能力,这增加了训练成本,限制了模型的可扩展性。
D2I 推理框架
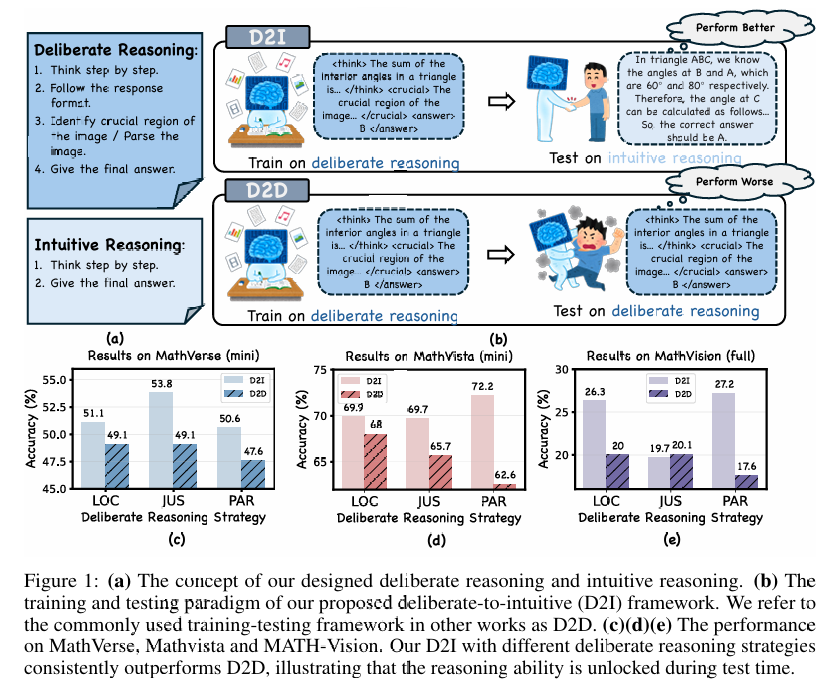
框架设计:D2I 框架的核心思想是将训练阶段的推理过程设计为“深思熟虑的(deliberate)”,而在测试阶段则切换为“直觉的(intuitive)”。具体来说:
训练阶段:模型通过规则化的格式奖励(format reward)进行深度推理训练,例如识别图像中的关键区域、解析图像结构等。
测试阶段:模型在推理时去除训练阶段的约束,更自由地生成答案,从而更好地利用训练中获得的能力。
方法细节
推理策略:D2I 设计了三种推理策略,以增强模型的多模态理解能力:
1.区域定位(Region Localization, LOC):模型需要输出图像中关键区域的坐标。
2.区域解释(Region Justification, JUS):模型需要解释图像中哪些部分对解决问题至关重要。
3.解析一致性(Parsing Consistency, PAR):模型需要在推理前输出图像的结构化解析。

实验与结果
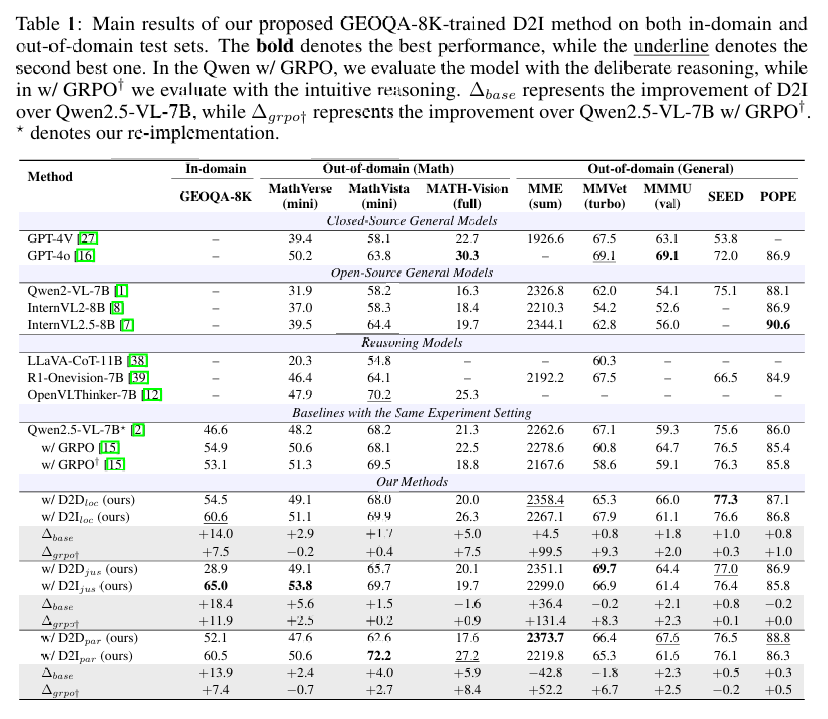
数据集:使用 GEOQA-8K 数据集进行训练,并在多个数学和多模态基准测试集上评估模型性能。
性能对比:
D2I 在多个基准测试中均优于基线模型(如 Qwen2.5-VL-7B)和采用 GRPO 训练的模型。
在数学推理任务中,D2I 的不同策略(LOC、JUS、PAR)均显示出显著的性能提升。
D2I 在跨领域(out-of-domain)基准测试中也表现出良好的泛化能力。
结论
D2I 的优势:通过在训练阶段采用深度推理策略,并在测试阶段允许模型自由生成答案,D2I 框架能够显著提升多模态模型的推理能力,同时避免了额外的数据标注和复杂的奖励机制。
推理策略的互补性:不同的推理策略在不同类型的推理任务中表现出互补的优势,说明 D2I 框架能够灵活适应多种推理场景。
未来工作
扩展应用:作者计划将 D2I 框架应用于其他多模态领域,如科学图表、教学视频或程序规划,以进一步验证其有效性和可扩展性。
总结来说,这篇文章提出了一种创新的推理框架,通过在训练和测试阶段采用不同的推理策略,有效提升了多模态语言模型在复杂推理任务中的表现,同时保持了训练的高效性和可扩展性。
(文:机器学习算法与自然语言处理)