


ToMiE 与 SeqAvatar 分别从空间结构与时序建模两个维度扩展了3D Gaussian Splatting 在复杂人体重建中的表达能力。
ToMiE 提出一种可扩展关节结构(Exoskeleton),通过梯度驱动策略自动定位需要生长的骨骼节点,在无需人工绑骨的前提下实现手持物体和宽松衣物的显式建模与动画驱动。
SeqAvatar 则引入分层时空上下文建模框架,在传统 3D 高斯人体建模基础上,利用帧间姿态差分和局部速度残差构建多尺度时序输入,引导非刚性高斯变形,保证了动作的连续性与细节一致性。
二者聚焦逐场景 3D 数字人训练,推动高斯建模在真实数字人场景中的进一步落地。

骨架拓展—ToMiE

论文标题:
ToMiE: Towards Explicit Exoskeleton for the Reconstruction of Complicated 3D Human Avatars
论文链接:
https://arxiv.org/abs/2410.08082
收录会议:
ICCV 2025
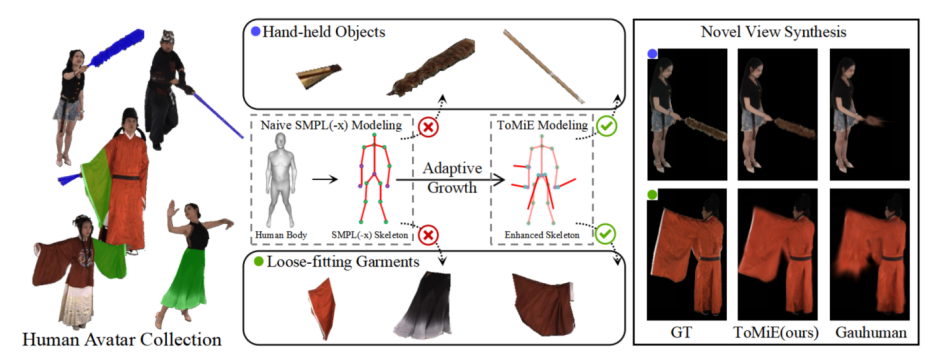
▲ 与其他数字人建模方法相比,ToMiE能通过增长外骨骼显式建模手持物和宽松衣物
研究背景
近年来,三维高斯泼溅(3D Gaussian Splatting, 3DGS)在数字人建模中展现出卓越性能,依托于 SMPL 骨架结构与 LBS(Linear Blend Skinning)形变机制,实现了从 T-pose 到任意姿态的高质量渲染与动画。
该类方法将人体视作一组绑定在骨架上的高斯单元,通过输入多视角连续人体视频,能够对紧身衣着的角色进行高保真建模。
然而,现有方法普遍依赖固定拓扑的 SMPL 骨架结构,其参数空间源自于大规模紧身人体扫描数据,在表达包含手持物体或宽松衣物的复杂人体时存在显著局限。
目前应对复杂人体多通过两种方式扩展建模能力:
一类方法借助显式定制外骨骼来扩展运动能力,但逐场景定制成本过大;
另一类方法隐式建模 SMPL 无法处理的运动,虽然能提升新视图渲染质量,但隐式表征使得数字人驱动变得困难。
为了解决上述难题,本文提出 ToMiE,一种支持骨架自适应生长的新型 3DGS 建模框架。
ToMiE 能够在训练过程中根据重建误差主动识别建模不足的区域,通过梯度引导机制定位需扩展的父关节,并显式生成外骨骼节点用于绑定与驱动附加高斯点,实现复杂附件与人体结构的有效解耦,显著提升了建模精度与动画灵活性。
方法概览
ToMiE 在标准 SMPL 骨架的基础上,引入一套可生长的“外骨骼”机制,通过梯度驱动的方式,在训练中定位需增强的父关节,并为其添加新子关节,绑定附加的高斯点。
整个过程由三部分构成:
梯度引导的父关节定位,为每个高斯点计算其对各个关节的归属程度,从而精确累积每个关节的反向梯度,并根据阈值自动判定是否扩展该关节。
附加关节的显式建模与优化,从视频帧信息获得关节的运动轨迹,将归属于其的高斯点与原始 SMPL 关节解耦。
暖机训练流程,训练前期不增长,只积累梯度信息,趋于稳定后进行外骨骼生长,迅速优化。
梯度引导的父关节定位
ToMiE 的关键创新之一是利用高斯点在渲染过程中的误差反向传播信号,引导骨架结构的扩展。不同于静态定义的骨架拓扑,ToMiE 在训练过程中动态定位出“重建能力不足”的父关节节点,并为其生长新的附加关节,从而提升局部几何和动作表达能力。
为此,ToMiE 首先分析当前高斯点对整体重建误差的贡献,并将该信息传递至骨架结构。每个高斯点在其位置 计算梯度范数:
为了将这些梯度聚合到骨架关节层面,ToMiE 定义了一个联合赋权策略,结合了传统的 LBS 权重 与新引人的 Motion Kernel 权重 ,用于评估高斯与每个关节的关联强度:
最终,将 N 个高斯点的梯度聚合为每个关节 的梯度响应 :
这些梯度值 反映了每个关节在当前骨架结构下对整体误差的贡献。ToMiE 根据设定阈值和排序策略,自动选出一组响应高的父关节,为其生长新的子关节。整个过程仅依赖渲染误差本身,无需标签或手工规则。
附加关节的显式建模与优化
一旦某个父关节被选中用于扩展,ToMiE 将为其添加一个新的子关节,用于绑定与驱动无法由原始 SMPL 骨架良好建模的局部高斯区域(如手持物体或宽松衣物边缘)。
这些附加关节被维护在一个“外骨骼关节表”中,键包含{子关节的父节点编号,子关节位置,子关节旋转}。ToMiE 并不直接为每一帧保存这些参数,而是使用两组可微分的 MLP 进行建模:
关节位置网络 :
关节旋转网络 :
其中, 和 分别是外骨骼位置和旋转, 是外骨骼下标, 是时间戳。外骨骼定义在标准空间中,因此位置不随运动时间变化,而旋转是时间相关的。
由于所有参数均可微,训练过程中附加关节的空间位置、时序旋转与 LBS 权重均可端到端优化。
相比隐式表示,ToMiE 的显式建模具备两个显著优势:可直接控制与插值动画,关节参数具备物理语义,可在推理阶段灵活控制;避免冗余拟合,通过与主骨架联动建模,减少对非刚性 MLP 的依赖,提升局部表达效率。
训练细节
ToMiE 的训练过程分为两个阶段:骨架预热阶段与骨架扩展阶段,分别对应基础高斯拟合与附加关节优化两个阶段,整体流程端到端进行,只需输入多视角连续视频监督。
在训练初期,ToMiE 使用标准 SMPL 骨架和 LBS 蒙皮权重进行高斯初始化和渲染。此阶段不进行骨架扩展,目的是稳定基本几何结构、建立可用的梯度信号,防止在模型尚未收敛时误导扩展判断。
一旦预热阶段完成,ToMiE 激活梯度引导的父关节定位机制(详见前节),并根据设定阈值选出需要扩展的父关节集合。
对于每个新增子关节:初始化位置为其父节点的空间坐标,初始化旋转为单位旋转,在训练中使用 MLP 学习其位置与旋转,并将其引入 LBS 蒙皮权重预测网络中。
在每一训练迭代中,ToMiE 将标准空间高斯经 LBS 后渲染至目标视角,监督信号来自真实图像与 mask。优化目标为多项损失组合:
为提升效率,ToMiE 同样支持高斯密度自适应操作(剪枝,克隆),并在附加关节生长后,动态调整剪枝阈值策略以控制计算开销。
实验效果
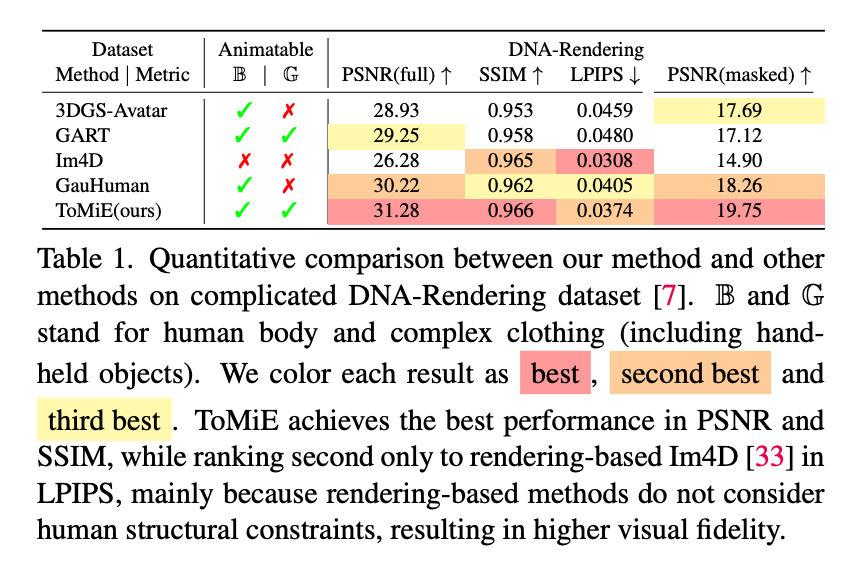
▲ DNA-Rendering数据集上的定量结果



时空拓展—SeqAvatar

论文标题:
Sequential Gaussian Avatars with Hierarchical Motion Context
项目链接:
https://zezeaaa.github.io/projects/SeqAvatar/
收录会议:
ICCV 2025
研究背景
近年来,三维高斯泼溅(3D Gaussian Splatting, 3DGS)在数字人建模中展现出极高的效率和渲染质量,成为新一代实时可驱动数字人的重要技术路线。
现有方法多借助 SMPL(-X) 骨架结构与线性蒙皮(Linear Blend Skinning, LBS)机制,从 T-pose 高斯人体表示出发,逐帧回归非刚性变形场,以实现不同人体姿态下的渲染。
然而,此前的人体驱动方式往往仅依赖于单帧骨架姿态这一全局条件,难以捕捉远离骨架区域的非刚性细节,因此在人物穿着宽松衣物、进行复杂运动等景下,常出现形变模糊、衣物反应迟滞等现象,降低了渲染的保真度。
此外,现有基于高斯驱动的方法在建模非刚性变形时往往忽略了时间序列中的动态变化,其所依赖的人体姿态条件仅描述了当前帧的人体结构,无法刻画同一姿态在不同运动阶段所对应的外观差异,导致出现“同姿异形”的模糊映射问题。
虽然部分基于 NeRF 的方法尝试引入姿态残差等时序编码机制,但由于缺乏对局部运动细节的显式建模,仍难以精准刻画细粒度的人体外观变化。
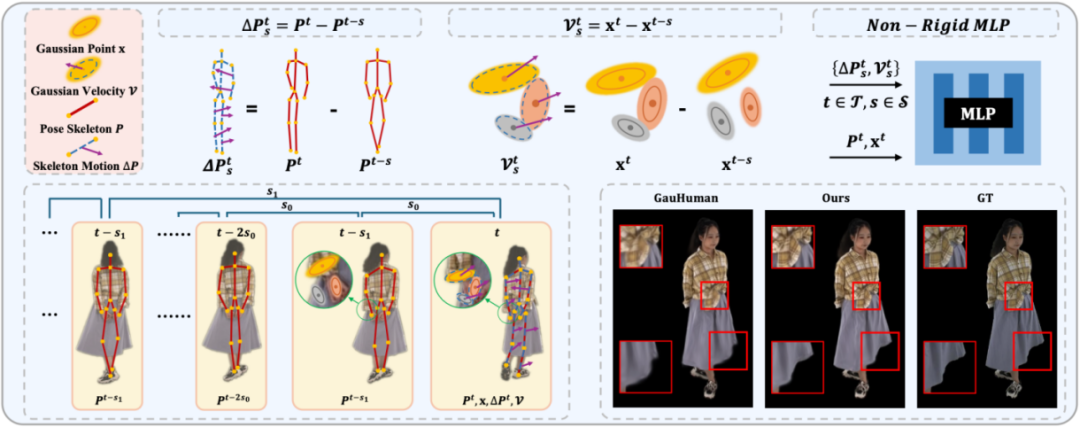
为解决上述挑战,本文提出一种适用于 3DGS 的层次化运动上下文建模方法,结合骨架级整体运动到单个高斯级的点运动,显式引入时序与局部信息,以提升非刚性变形建模能力。
通过空间与时间的多尺度的采样策略,模型能够更鲁邦地建模高斯点的动态变化,在保持建模精度的同时增强对复杂动作与局部细节的表达能力。
方法概览
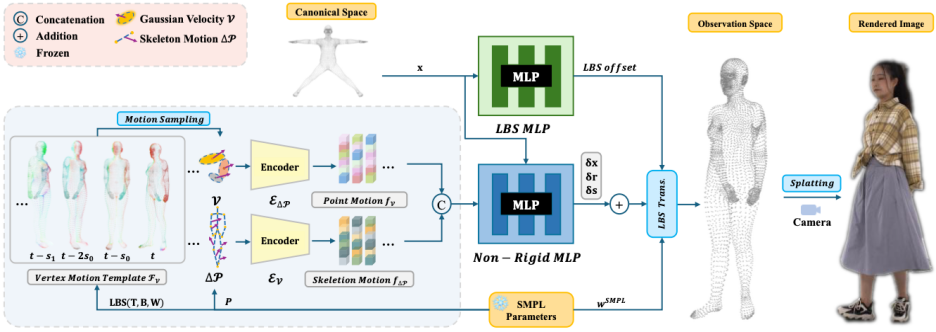
SeqAvatar 采用标准的 SMPL 骨架以及 LBS(Linear Blend Skinning)形变机制,来实现 T-pose 到任意姿态的高质量渲染与动画。
为了解决动态场景中人体姿态与外观的一对多复杂映射问题,以及实现更细粒度的人体建模,SeqAvatar 提出了一种由粗到细的层次化运动上下文信息。具体而言,人体骨架整体的时序运动信息以及每个高斯点的运动状态均会作为非刚性形变预测网络的条件输入,从而更精确地建模人体的非刚性形变。
此外,SeqAvatar 提出了一种时空多尺度采样策略,将不同时间窗口以及空间上临近高斯点的运动状态共同作为条件输入,通过结合长期与短期的时序运动变化以及局部的空间运动差异,来进一步提高预测的鲁棒性。
由粗到细的层次化运动上下文信息
SeqAvatar 通过引入更丰富的时序运动信息来更好的解决静态人体姿态无法建模复杂运动中人体姿态与外观的复杂映射问题。具体而言,人体时序信息分为全局的骨架运动和细粒度的高斯点运动两部分。
给定 个等间隔 采样等前序时间帧:
全局的骨架运动信息计算方式如下:
其中 表示轴角形式下两个人体骨架的差异。
这一骨架运动信息用于描述人体整体的运动信息,为了实现更细粒度的非刚性变形建模, SeqAvatar 对每个高斯点的运动状态进行建模。一种思路是,像计算人体骨架的运动信息那样去计算前后帧每个高斯点的位置差异来描述每个高斯点的运动状态。
然而,计算观测空间下高斯点的位置差异需要先对标准空间下 T-pose 的人体高斯点进行变换(这其中包括期望预测的非刚体形变),会造成循环依赖。因此,SeqAvatar 采用一种折中的方式,通过采样 SMPL 模版的速度信息来为每个高斯点添加运动状态描述。
具体而言,首先将标准空间下 T-pose 高斯点通过 LBS 变换至观测空间:
其中, 为 SMPL 模版点, 为每个关节点的变换矩阵, 为 LBS 权重。由此,可以计算出前后两帧中 SMPL 模版的速度信息:
基于上述两种运动描述信息,可以通过一定的采样策略来获取用于预测非刚性变形的条件。
时空多尺度采样
在空间维度上,为了更鲁邦地获取细粒度的高斯点运动条件,对于每一个高斯点,SeqAvatar 从 SMPL 速度模版上采样 K 个近邻点的速度用于描述其运动状态,并作为条件输入至非刚性变形网络。
在时间维度上,为了捕捉人体整体运动趋势和帧间运动细节,SeqAvatar 采用了多尺度序列采样策略。
具体而言,采样若干间隔逐步增加的时序序列,以获得跨越不同时间窗口的人体运动信息:
其中, 为采样间隔的增加率, 为所有间隔的集合。在采样时,会根据不同的间隔 采样若干序列,并将这些序列的运动信息共同作为条件输入非刚性形变网络。
优化
通过上述方法采样得到运动条件并输入非刚性变形网络后,可以根据预测得到的非刚性变形结果更新每个高斯点的位置:
然后根据标准 LBS 流程将高斯点变换至观测空间下并进行渲染:
并计算损失、更新高斯参数:
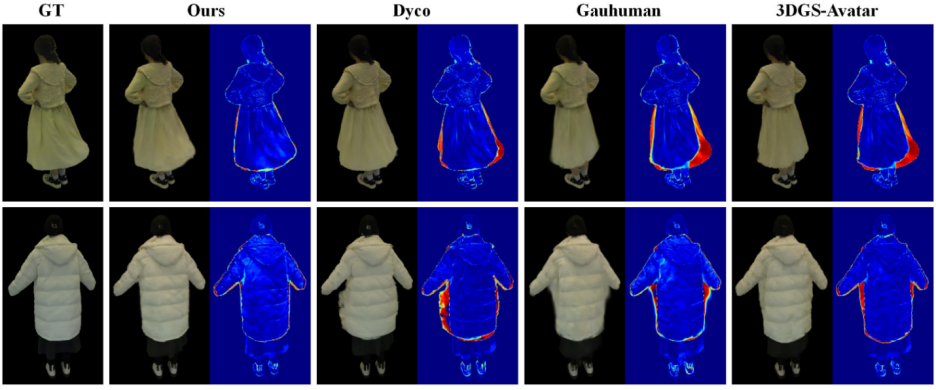
实验效果

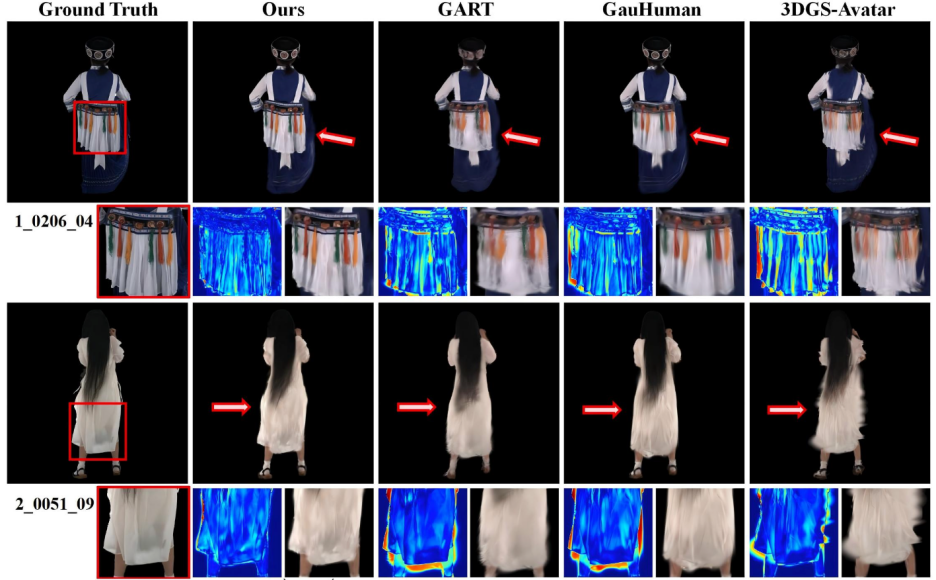

▲


总结一下
ToMiE 与 SeqAvatar 分别从空间结构和时序建模两个维度拓展了 3D Gaussian Splatting 在复杂人体建模中的表达能力。
ToMiE 聚焦结构层面,通过梯度引导策略实现显式骨架结构的自动生长与绑定优化,提升对手持物体与宽松衣物的建模与动画表现;SeqAvatar 聚焦动态建模,引入分层时空上下文条件来预测非刚性高斯变形,从而更稳定地表达复杂动作下的外观变化。
两者均可集成至 3DGS 框架,在保证建模精度的同时显著提升了数字人驱动与渲染的真实性,为高保真、可动画的三维数字人重建提供了更具泛化性与灵活性的解决方案。
(文:PaperWeekly)