
这篇标题直接体现了核心主题,突出了技术点(RLHF 和 trl 库),让读者快速了解到内容价值。如果需要更多吸引力,也可以优化成更具互动感的标题:
“从 0 到 1:用 RLHF 和 Python 构建奖励模型,全面提升语言模型能力!”

!pip install -U argilla pandas trl plotly -qqqimport randomimport torchfrom datasets import Dataset, load_datasetfrom transformers import (AutoModelForSequenceClassification,AutoTokenizer,TrainingArguments,)from trl import RewardTrainerimport argilla as rg
rg.init(api_url="http://localhost:6900", # Replace with your Argilla server's URLapi_key="admin.apikey" # Replace with your API key if applicable)
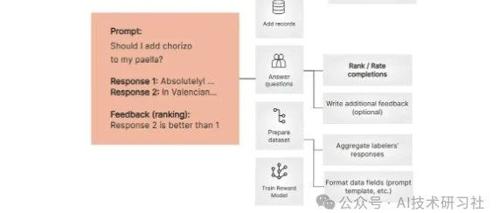
datasets集库中的load_dataset函数加载数据集。在本例中,数据集名为“ argilla/dolly-curated-comparison-falcon-7b-instruct ”,并且您专门选择数据集的“train”分割。hf_dataset = load_dataset("argilla/dolly-curated-comparison-falcon-7b-instruct", split="train")df = hf_dataset.to_pandas()df # printing the dataframe

(文:AI技术研习社)