
“ 外部数据需要经过嵌入——Embedding转换成神经网络可以识别的向量格式的数据 ”
开发一个大模型或者说神经网络需要经过以下几个大致步骤:
1. 数据集的处理
2. 神经网络模型设计
3. 神经网络模型训练
前向传播
损失计算
优化器
反向传播
可能很多人觉得神经网络模型很复杂,也看不懂啥是啥;比如说很多人还分不清pytorch和Transformer的区别,也看不明白Transformer的结构图是什么。
所以,今天我们以Transformer架构为例,详细梳理一下神经网络模型的功能结构;其它神经网络架构也大致相同,不同点主要集中在神经网络的具体功能实现。
神经网络结构说明
数据集处理
其实严格来说第一步数据集的处理不属于神经网络模型功能的范畴,它只是一个前置处理功能,目的就是把外部输入的数据转化为神经网络模型可以处理的格式。
而神经网络接受的数据格式就是——向量格式。
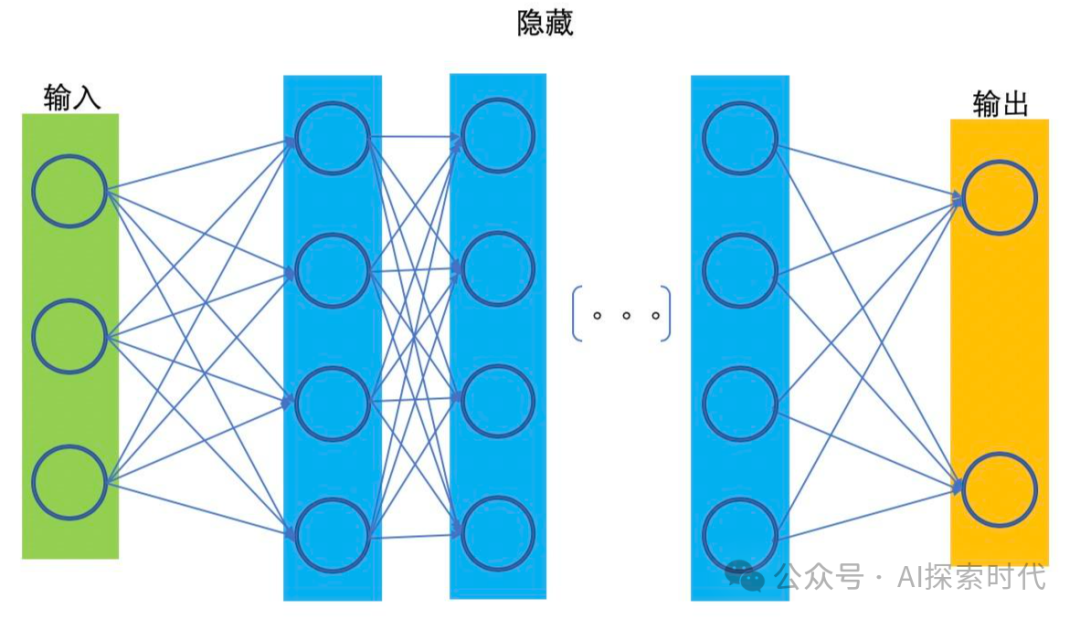
这一点从神经网络模型的拓扑图中也可以看的出来,神经网络模型虽然可以有n(n大于等于1)层网络,但有两个比较特殊的神经网络层,那就是输入层与输出层;因为输入层与输出层需要与外界交互,输入层需要接收外部输入的数据;而输出层需要把神经网络中的数据输出给外部。
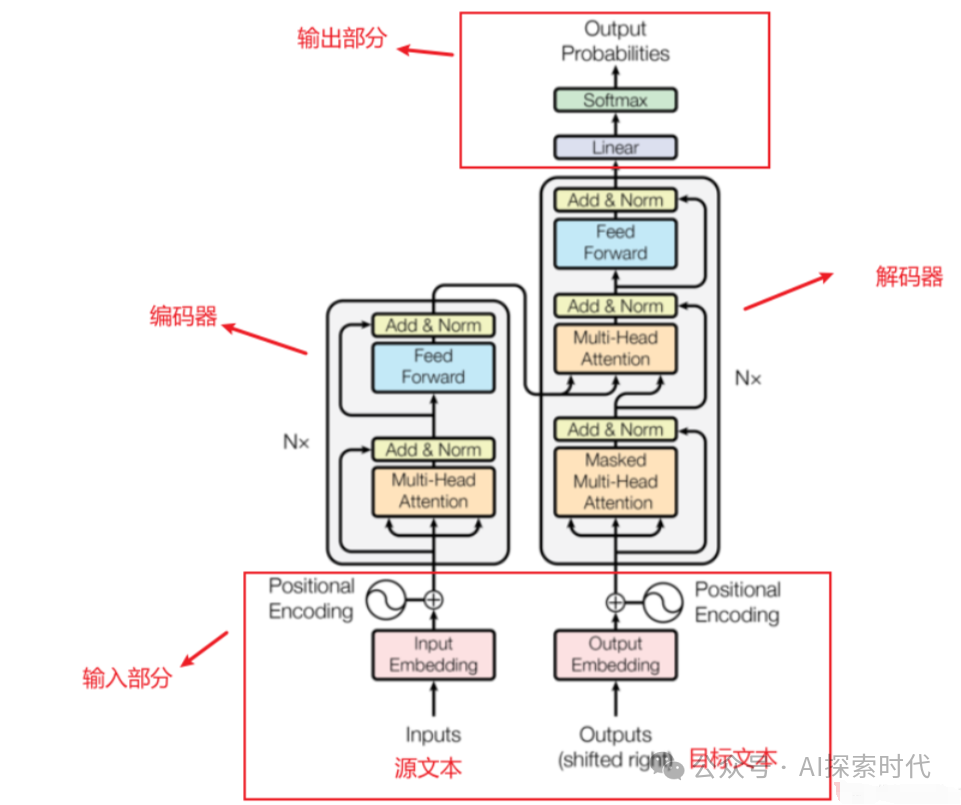
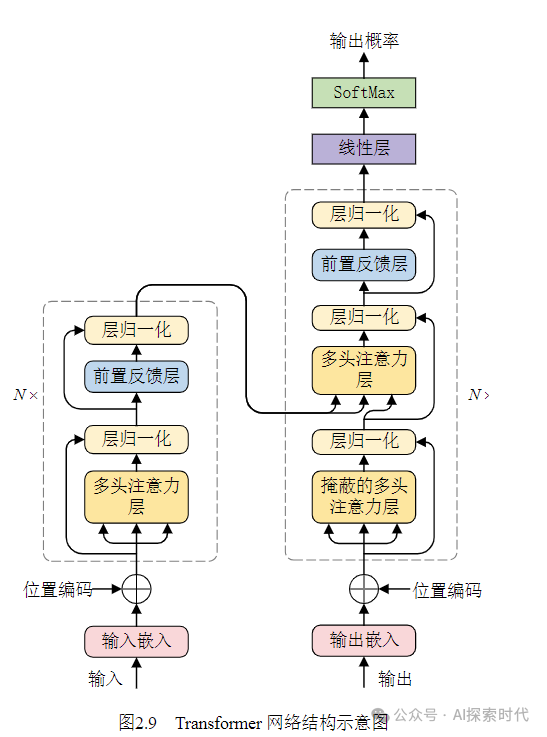
其次,从Transformer的结构图中也可以看出,Transformer架构的核心点在于多层的encoder-decoder,也就是编码器和解码器结构;而编码器是由多头注意力机制——前馈神经网络层以及两个残差链接和归一化处理层组成;而解码器与编码器几乎相同,只是多了一个多头注意力层以及残差链接和归一化层。
而输入嵌入和位置编码只属于前置处理,即不属于编码器也不属于解码器,但编码器和解码器都需要这个前置功能。
神经网络模型设计
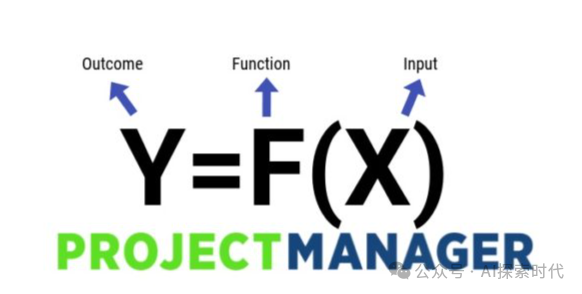
神经网络模型简单来说就是一个模拟人类大脑神经网络运作的一个数学模型,可以把它简单理解成一个函数;对使用者来说,神经网络就是一个黑盒模型,给定一个输入,神经网络就会按照特定的规则给出一个输出。
只不过这个模型比较特殊的一点就是,模型可以通过学习数据的规律实现不断进化的过程,只不过目前来看这个学习过程是被动的,而不是主动的。
从本质上来讲,神经网络就是多维向量的计算过程,通过把外部数据转化为向量,然后根据某种规则计算其在高维空间中的数学关系。
模型的训练
在上面神经网络模型设计中说过,模型可以通过学习数据规律实现不断进化,这个学习就是通过模型训练来实现的;在训练的过程中需要把模型调整到训练模式,然后模型就可以使用前/反向传播,损失计算,优化函数等来实现模型参数的调优——也就是学习的过程。
而至于模型是怎么训练的, 以及其详细的训练过程;这个就要看神经网络到底是怎么设计的,其有多少网络层,以及每层网络的功能实现过程;虽然神经网络的重点在于模型的设计,但训练数据的质量,以及训练的过程都会直接影响到模型的效果。
神经网络的执行过程是一个线性过程,这一层的输入来自上一层的输出,而这一层的输出又是下一层的输入。而每层神经网络完成什么样的任务,就看你这层神经网络是怎么设计和实现的。
这就像排水管道一样,水管就是神经网络层,向量就是“水流”里面的水。
(文:AI探索时代)