AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文介绍刚刚被 IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 录用的一篇文章:Uni-AdaFocus: Spatial-temporal Dynamic Computation for Video Recognition,会议版本 AdaFocus V1/V2/V3 分别发表于 ICCV-2021 (oral)、CVPR-2022、ECCV-2022。
-
论文链接:https://arxiv.org/abs/2412.11228
-
项目链接:https://github.com/LeapLabTHU/Uni-AdaFocus
Uni-AdaFocus 是一个通用的高效视频理解框架,实现了降低时间、空间、样本三维度冗余性的统一建模。代码和预训练模型已开源,还有在自定义数据集上使用的完善教程,请访问项目链接。
Uni-AdaFocus 的关键思想与设计思路在于,它建立了一个统一的框架,实现了降低时间、空间、样本冗余性的统一建模,并且使用一些数学方法处理了时空动态计算不可微分的问题,可以方便地进行高效端到端训练,无需强化学习等更为复杂的方法。
-
降低时间冗余性:动态定位和聚焦于任务相关的关键视频帧;
-
降低空间冗余性:动态定位和聚焦于视频帧中的任务相关空间区域;
-
降低样本冗余性:将计算资源集中于更加困难的样本,在不同样本间差异化分配;
在长视频理解上,Uni-AdaFocus 比现有最好的同类 baseline 加速了 5 倍。它可以兼容于现有的高效 backbone,利用动态计算的思想进一步提升其效率,例如将 TSM 和 X3D 各自加速了 4 倍左右。在上述加速情形中,Uni-AdaFocus 基本上都在加速的同时实现了比较显著的准确性提升。
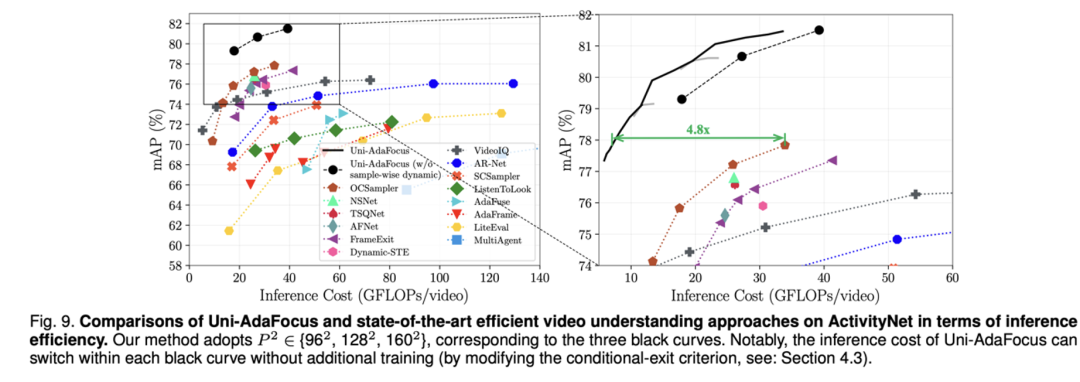
在 7 个学术数据集(ActivityNet, FCVID, Mini-Kinetics, Sth-Sth V1&V2, Jester, Kinetics-400)和 3 个应用场景(使用脑 MRI 诊断阿尔兹海默症和帕金森综合征、细粒度跳水动作识别、互联网不良视频检测)上进行了验证,Uni-AdaFocus 发挥稳定,特定典型情况下可实现多达 23 倍的(性能无损)推理加速或高达 7.7% 的准确性提升。
在 CPU/GPU 实测速度、吞吐量上,Uni-AdaFocus 与理论结果高度一致。
相较于图像,视频理解是一个分布范围更广、应用场景更多的任务。例如,每分钟,即有超过 300 小时的视频上传至 YouTube,超过 82% 的消费互联网流量由在线视频组成。
自动识别这些海量视频中的人类行为、交互、事件、紧急情况等内容,对于视频推荐、视频监控、智能编辑与创作、教育与培训、健康医疗等受众广泛的应用具有重要意义。
同时,面向视频数据的视觉理解技术在具身智能、自动驾驶、机器人等物理世界的实际场景中也有广泛的应用空间。
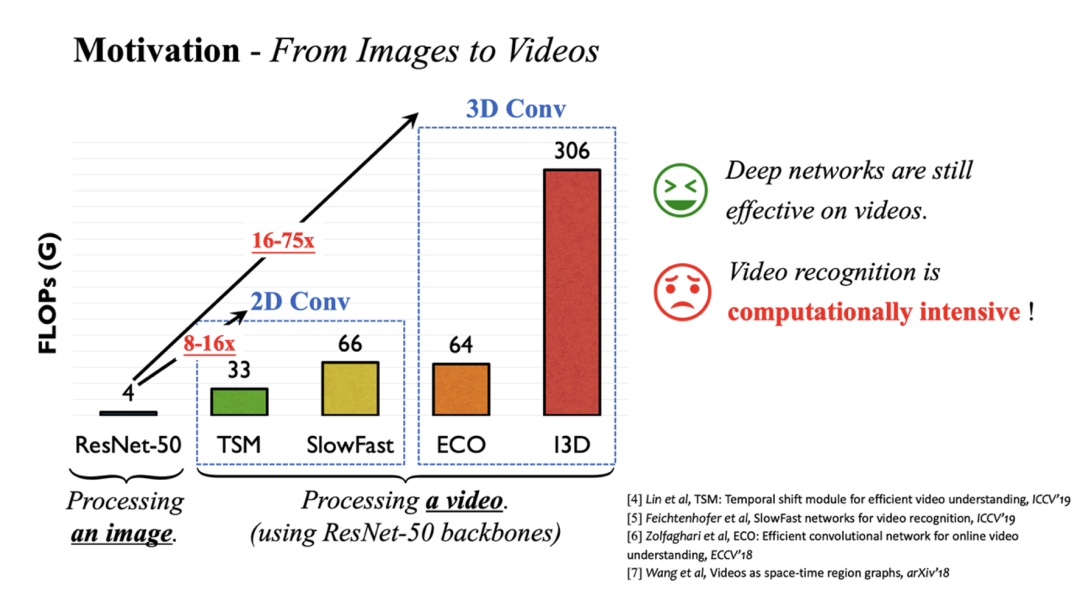
近年来,已有很多基于深度神经网络的视频理解算法取得了较佳的性能,如 TSM、SlowFast、I3D、X3D、ViViT 等。然而,一个严重的问题是,相较于图像,使用深度神经网络处理视频通常会引入急剧增长的计算开销。如下图所示,将 ResNet-50 应用于视频理解将使运算量(FLOPs)扩大 8-75 倍。
因此,一个关键问题在于,如何降低视频理解模型的计算开销。一个非常自然的想法是从视频的时间维度入手:一方面,相邻的视频帧之间往往具有较大的相似性,逐帧处理将引入冗余计算。另一方面,并非全部视频帧的内容都与理解任务相关。现有工作大多从这一时间冗余性出发,动态寻找视频中的若干关键帧进行重点处理,以降低计算成本,如下图第二行 (b) 所示。
然而,值得注意的一点是,该团队发现,目前尚未有工作关注于视频中的空间冗余性。具体而言,在每一帧视频中,事实上只有一部分空间区域与任务相关,如图中的运动员、起跳动作、水花等。
受此启发,该团队提出了 AdaFocus 方法来动态定位每帧中的任务相关区域,并将最多的计算资源分配到这些区域以实现高效处理,如上图第三行 (c) 所示。
以 AdaFocus 为基础,该团队进一步实现了时间、空间、样本三个维度的统一动态计算,提出了一个通用于大多数骨干网络(backbone)的 Uni-AdaFocus 框架。
Uni-AdaFocus 能够自适应地关注于视频中任务相关的关键帧、关键帧中任务相关的重要区域、以及将计算资源更多地分配给更为困难的样本,如上图第四行 (d) 所示。
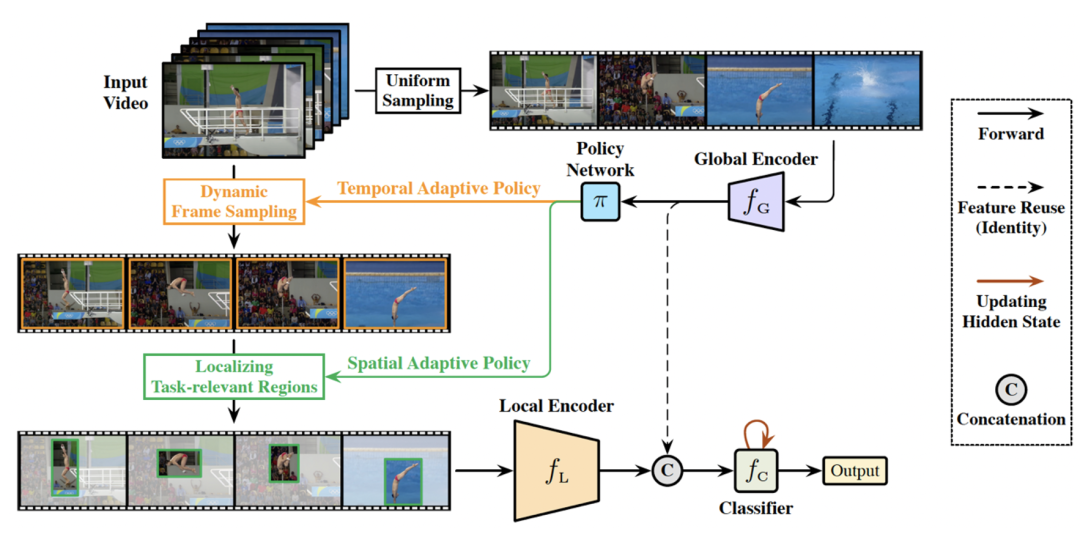
如上图所示,Uni-AdaFocus 首先使用全局编码器 f_G(轻量化的特征提取网络,例如 MobileNet-V2 等)用低成本对均匀采样的视频帧进行粗略处理,获得视频整体的时空分布信息,即全局特征。
一个策略网络 π 基于 f_G 提取的全局特征自适应地采样关键帧以及其中的关键区域,得到值得关注的 patches,patch 的形状和大小根据视频帧的具体特性自适应地决定。局部编码器 f_L(参数量大的大容量神经网络,准确率高但计算开销较大)仅处理策略网络 π 选择出的 patches,即局部特征。
最后分类器 f_C 逐帧聚合全局特征和局部特征以得到最优的视频理解结果,同时通过早退机制实现对样本维度计算冗余性的建模。
关于 Uni-AdaFocus 模型设计和训练方法的更多细节,由于比较繁杂,可以移步参阅论文。
使用 MobileNet-V2 和 ResNet-50 为 backbone, Uni-AdaFocus 在 ActivityNet,FCVID 和 Mini-Kinetics 上的实验结果,以及与现有最佳同类方法的比较。
蓝色文字表示基于 baseline 模型的提升幅度
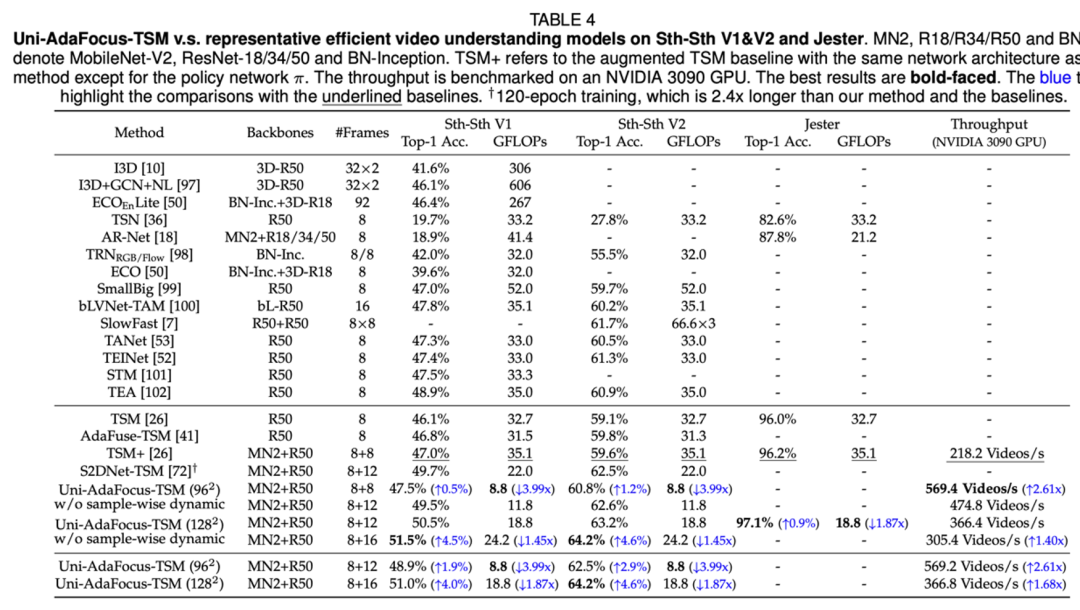
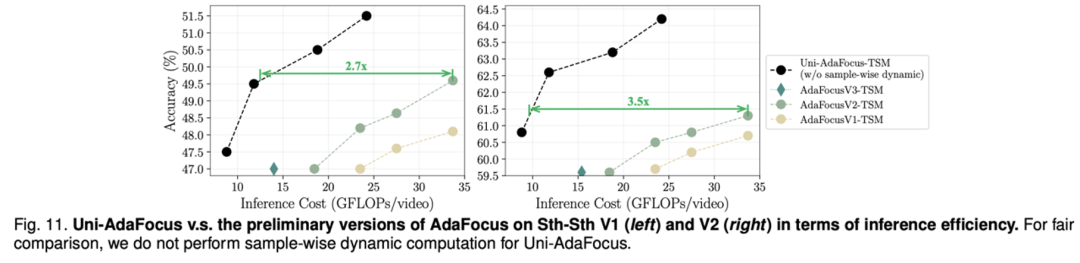
使用 MobileNet-V2-TSM 和 ResNet-50-TSM 为 backbone,Uni-AdaFocus 在 Something-Something-V1 / V2 和 Jester 上的实验结果。
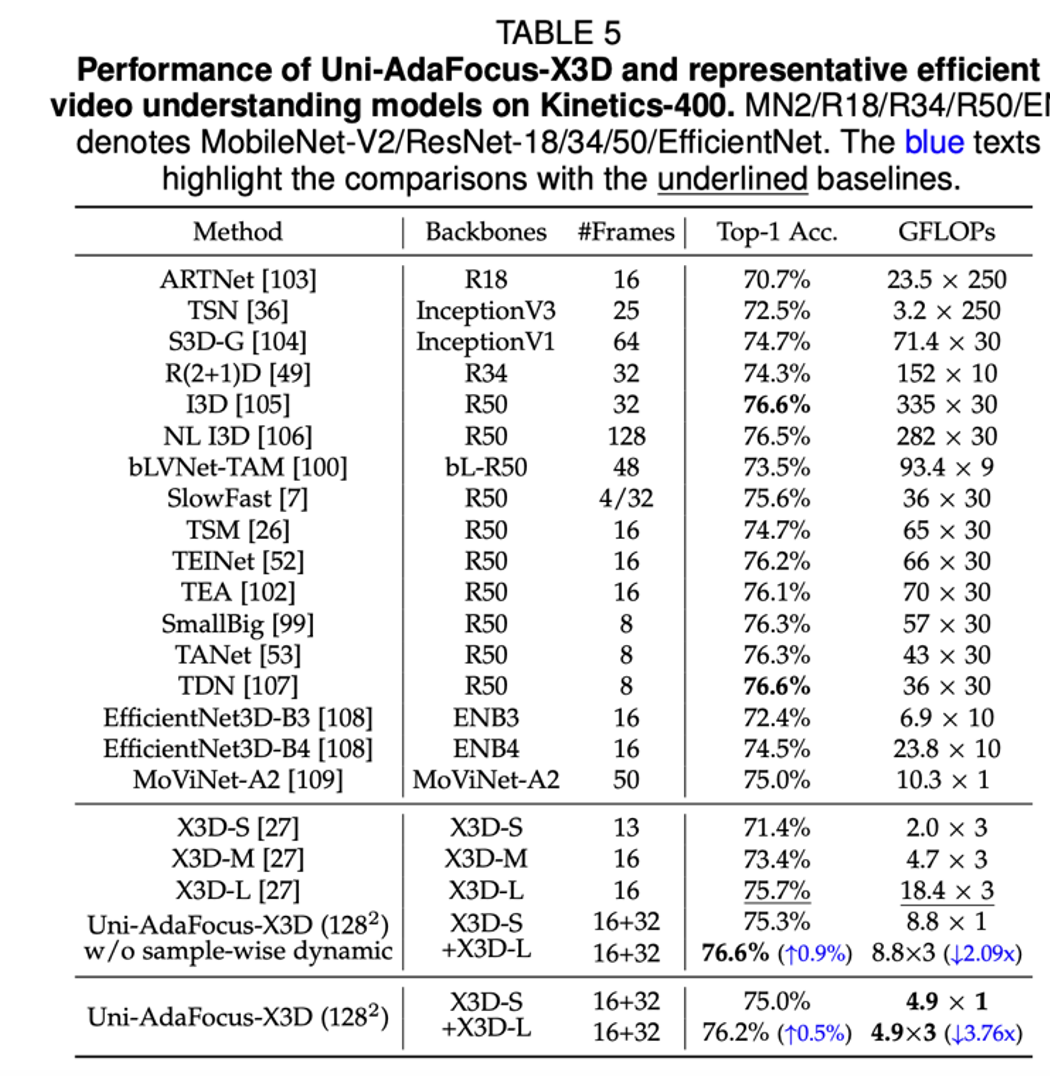
使用 X3D-S 和 X3D-L 为 backbone,Uni-AdaFocus 在 Kinetics-400 上的实验结果。
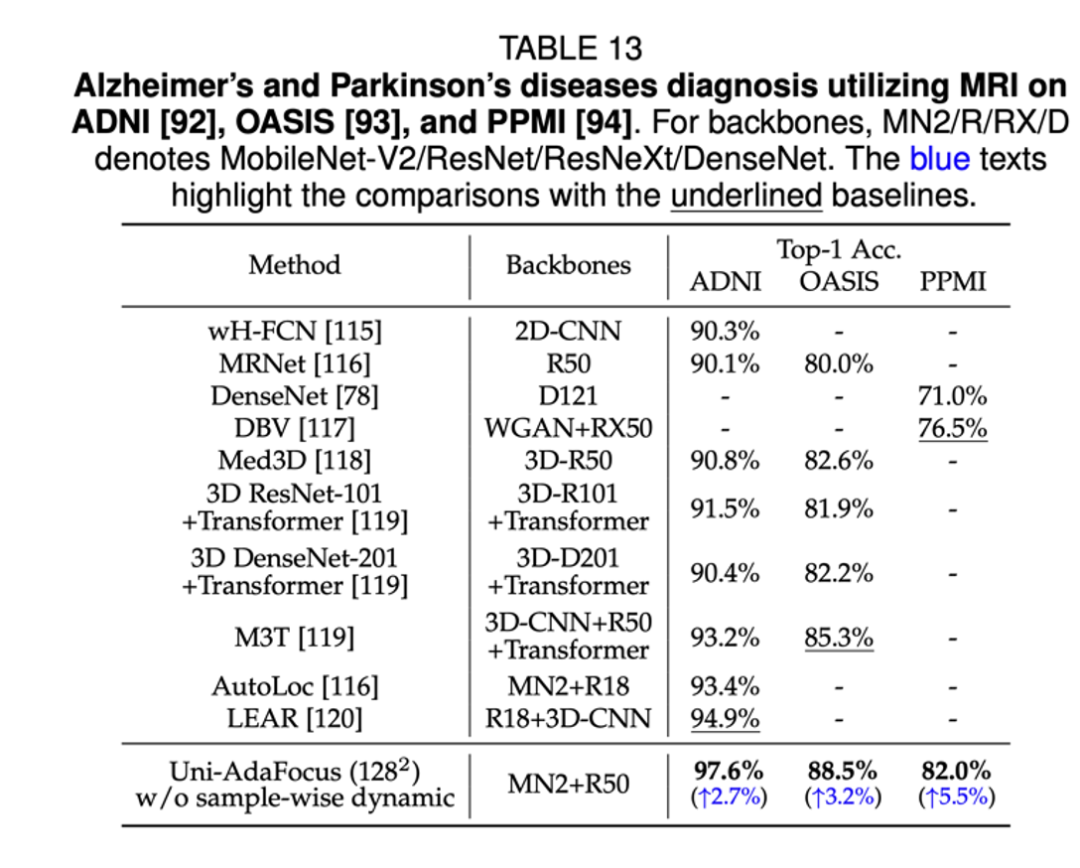
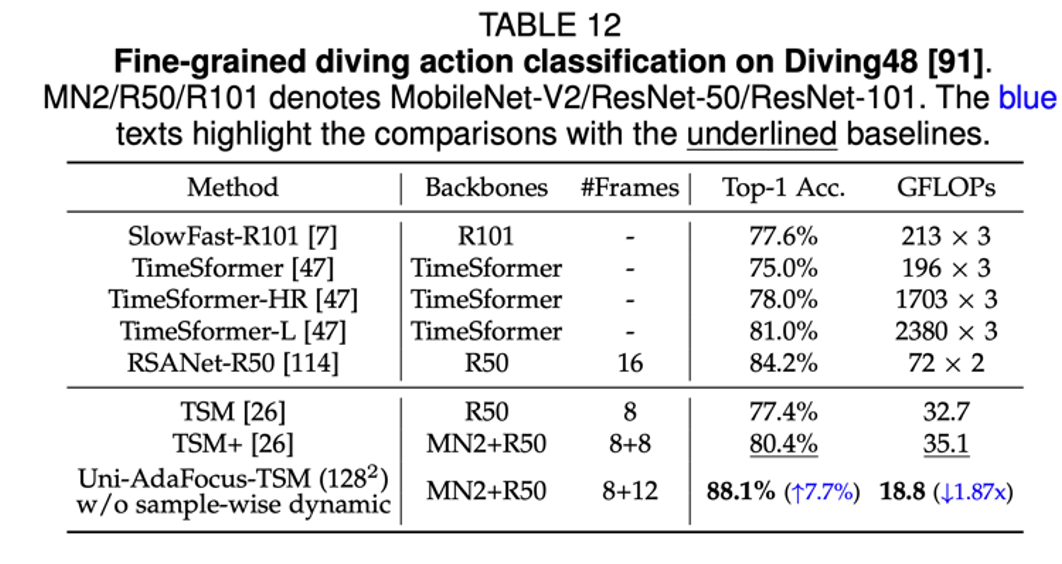
Uni-AdaFocus 在 3 个应用场景(使用脑 MRI 诊断阿尔兹海默症和帕金森综合征、细粒度跳水动作识别、互联网不良视频检测)上的实验结果。
Uni-AdaFocus 的可视化结果。所示的视频帧为 Uni-AdaFocus 所选取的任务相关帧,浅蓝色方块表示 Uni-AdaFocus 在每一帧选择的 patch。可以看到 Uni-AdaFocus 成功定位到任务相关视频帧中的任务相关区域,例如长笛、小狗、圣诞树、马术运动员等,并能自适应地调整 patch 的大小和形状、以及任务相关视频帧的数目。
(文:机器之心)