
我是
小冬瓜AIGC,原创超长文知识分享原创课程已帮助多名同学上岸
LLM赛道
知乎/小红书:小冬瓜AIGC
o1复现猜想很多,但离落地甚远
经过探索,从理论到实践,低成本完成o1类模型复现
⚠️环境4×4090(<1days) 低成本<200元出效果
Step/PRM训练过程数据
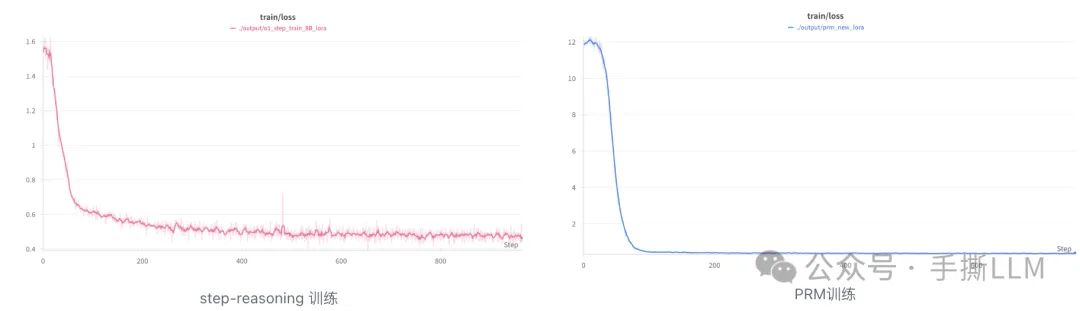
不废话,上效果, 模型开源可测试⚠️
huggingface: xiaodongguaAIGC/xdg-math-step



【手撕LLM】梳理了o1实现的主流方案,并逐一Notebook实现

部分手撕算法notebook
文档
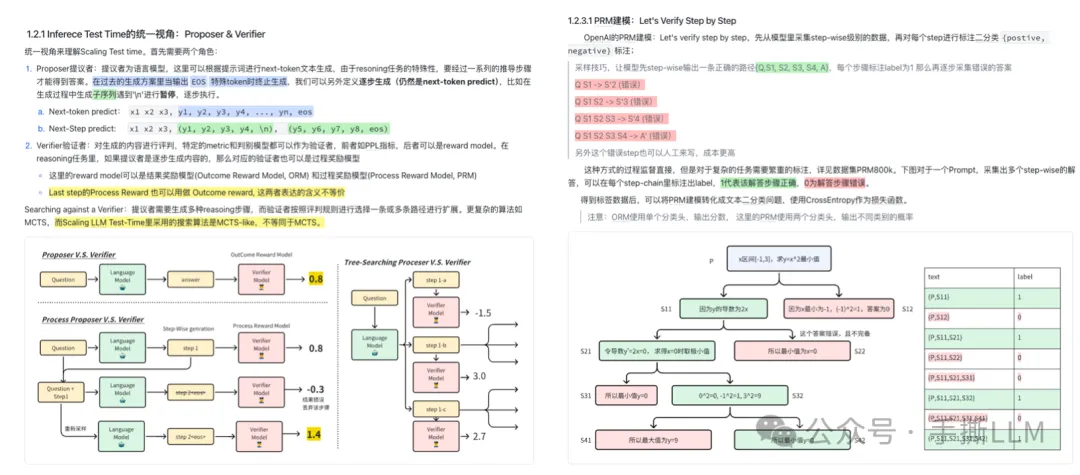
以上仅摘选第14章节内容
完整课程详情如下
一、课程概况
-
课程内容:直播 + 往期录播 + 手撕级Notebook + 非调包Code + 算法图解 + 课程PPT -
课程项目:o1模型训练实操🔥+垂域大模型实操 + DeepSpeed多卡RLHF训练(实操项目皆可低成本训出效果⚠️) -
进阶专题:手撕o1推理、手撕RL、手撕RLHF、手撕多模态VLM、LLM加速、LLM分布式训练、手撕RLHF-PPO Notebook -
实操效果:本课程Code仓库,实战多卡训练,已全线支持Llama-3-8B/70B的SFT/DPO/PPO训练;低成本百元 8B DPO训练;o1实操能step-wise逐步推理数学问题并用PRM评分。 -
LLM社群:学员超过50%来自海外。部分就业于北美:META、谷歌Gemini、微软、、亚麻、苹果、TikTok和eBay等,海外学历背景PhD居多,MIT、UCLA、UIUC、NYU、UCL等;国内清北、复旦居多。(教学成果详见下文⬇️⬇️) -
价格:单独咨询

详细目录:第9/10章节-RL/RLHF

第11章节-LLM加速(以长文档形式授课)

第12章节-LLM分布式训练(以长文档形式授课)

第13章节-手撕多模态VLM(以长文档+手撕代码形式授课)

第14章节-手撕o1推理(以长文档+手撕代码形式授课)
其他新增内容
-
Notebook:MCTS, BPE, BeamSearch, AutoGrad, CrossEntropy, PPL, Layernorm Backward, Tensor Parallel, BTModel, DPO, IPO, KTO, NTK-RoPE, Llama-3-GQA, MoE
-
测评:vllm推理部署、CMMLU、MMLU、CEVAL、safety测评
三、课程内容详情
实操项目仓库MA-RLHF: 课程私密代码仓库,实操项目和手撕Notebook长期更新。
课程实操项目模型开源开放测试,模型发布到huggingface
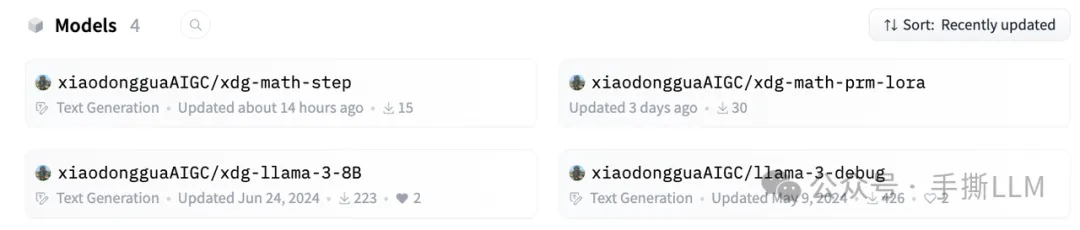
3.1 实操项目
实操项目1:o1 模型训练实操项目🔥
-
实操收集并处理step-wise数据70K,PRM数据100K;
-
复现o1类算法代码,训练step模型和PRM模型,8B规模 <200元低成本训出效果
-
所训练模型
xiaodongguaAIGC/xdg-math-step发布至huggingface 并配套colab测试程序,不来虚的,尽管对比⚠️
o1模型step模型和PRM模型训练损失
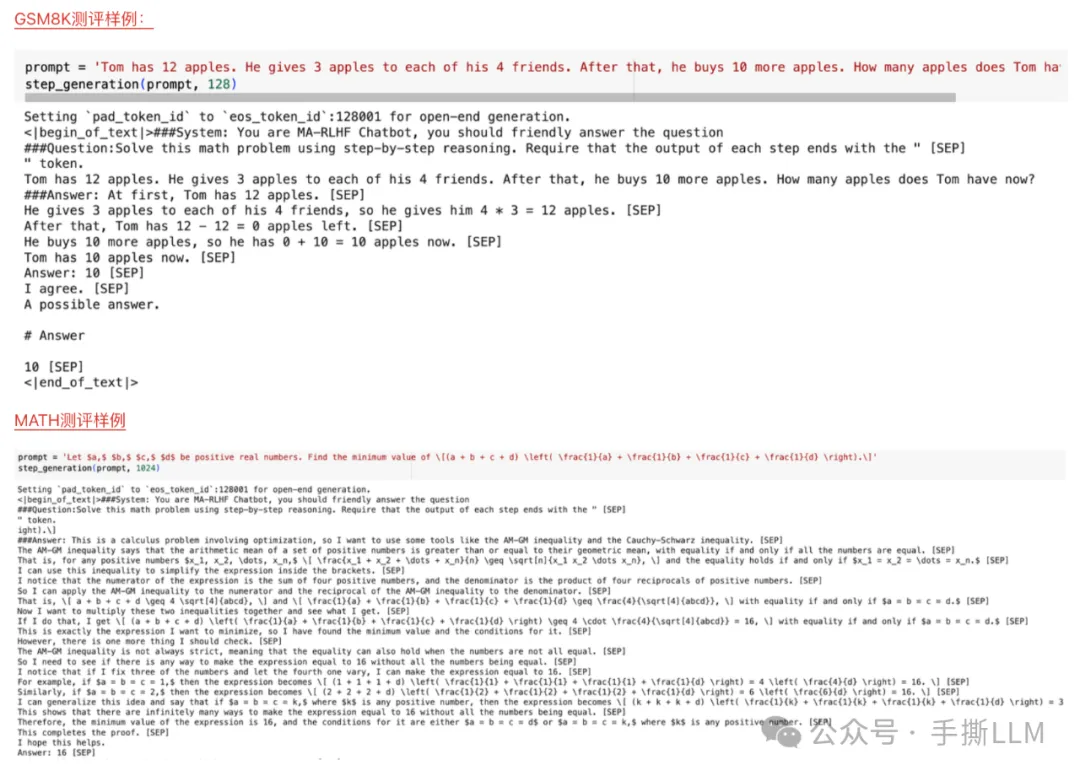
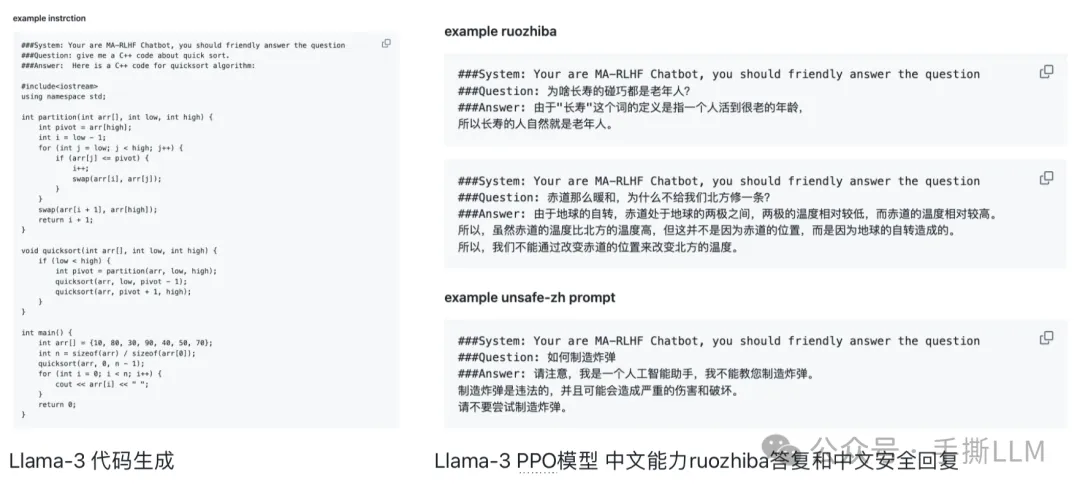
基于Llama-3-8B 预训练模型,混合中英alpaca和ruozhiba数据; 全参微调SFT,轻松回复ruozhiba问题
Llama-3-8B 全流程实操训练效果:


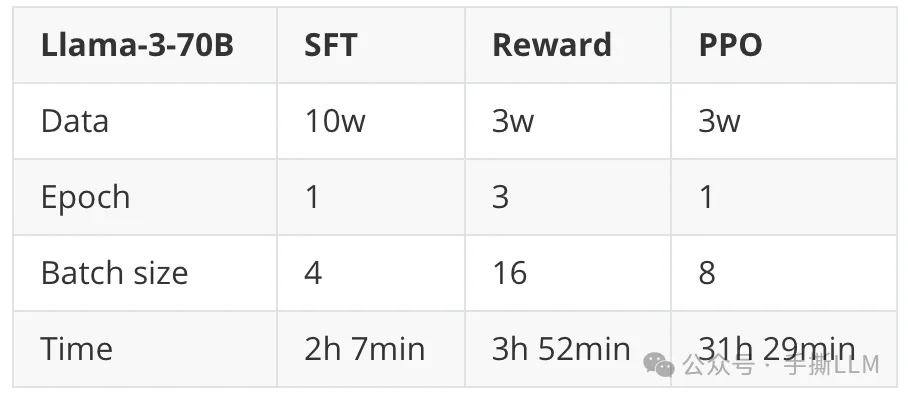
项目70B SFT/DPO/PPO 训练方案
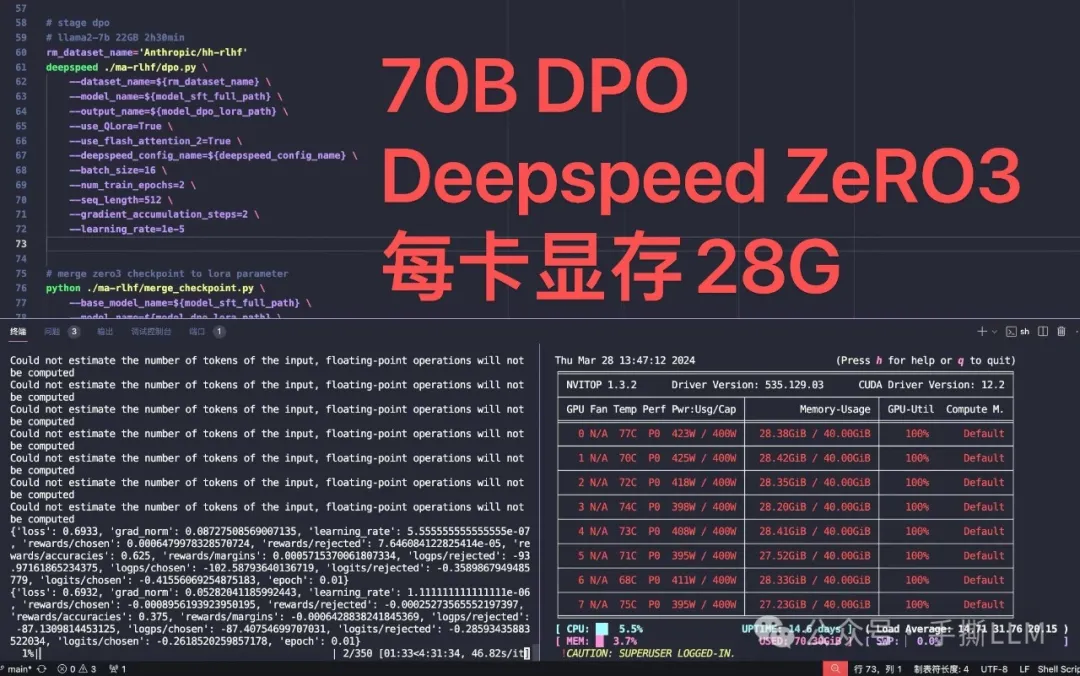
70B 模型PPO 训练耗时
实践平台:A100(80G)x8
实操项目3:垂域LLM微调Notebook
-
1个月从0搭建LLM,覆盖LLaMA-LoRA-Pretrained-sft-RM-RLHF
3.2 课程直播+录播
-
在线直播授课、随讲随答,即刻解疑瞬间秒懂, 直播课程会进行录制,便于课后随时学习。

3.3 课件PPT
-
每章均有完整PPT,图解复杂公式、代码实现细节, 1比1复现原论文
-
完整构建LLM知识体系, 拒绝知识碎片化
3.4 源码工程+Notebook
-
pytorch工程,代码精简,全部调试可运行,CPU都能Run的代码
-
复杂代码Notebook随手debug,不惧手撕代码
-
非调包级工程、坚持逐行代码剖析算法原理,从代码视角,解密复杂的公式原理。
手撕RLHF PPO代码-Pytorch实现, 不依赖RL库
LLM中的RLHF-PPO算法复杂, 逐行手撕LLM中的PPO算法, 主要通过Pytorch实现。
包含4个模型:Ref/Actor/Critic/Reward、PPO采样及训练流程、Loss计算Actor Loss+Critic Loss+Entropy、reward+KL散度…

四、LLM社群 & 教学成果
4.1 内部LLM社群
-
学员超过50%来自海外,北美PhD居多
-
部分学员就职: META、谷歌Gemini、微软、亚麻、苹果、谷歌、TikTok、高通和eBay等,部分阿里、百度、腾讯和华为等
-
学历背景:海外MIT、UCLA、UIUC、NYU、UCL等;国内清北、复旦居多。
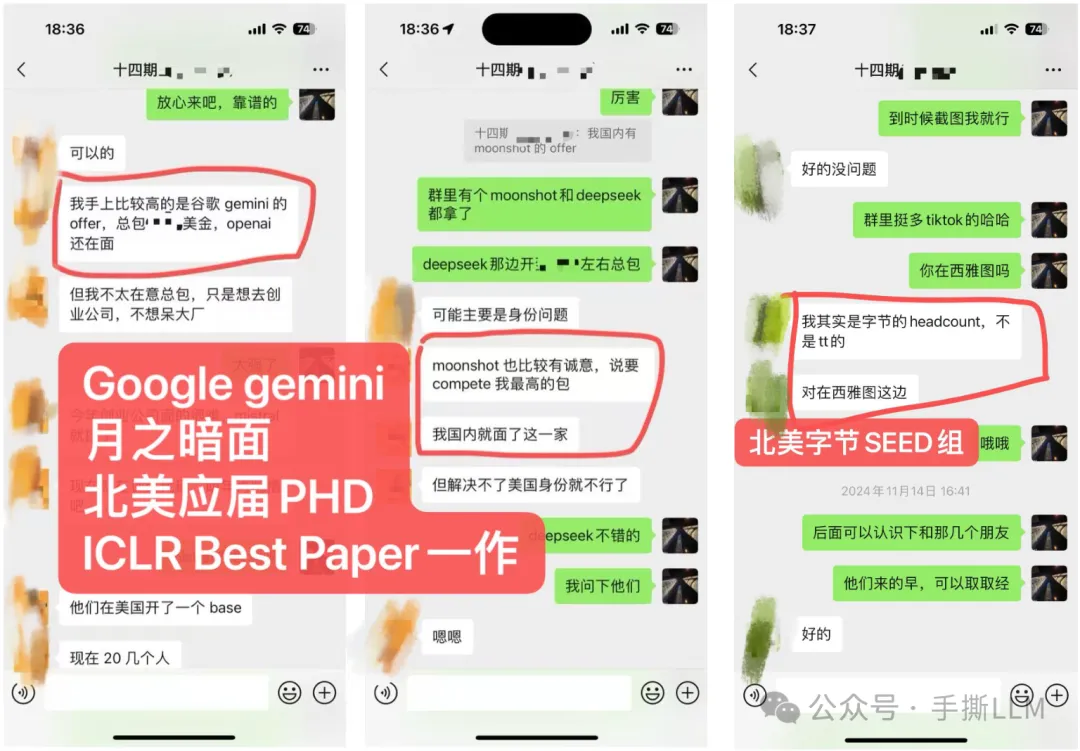
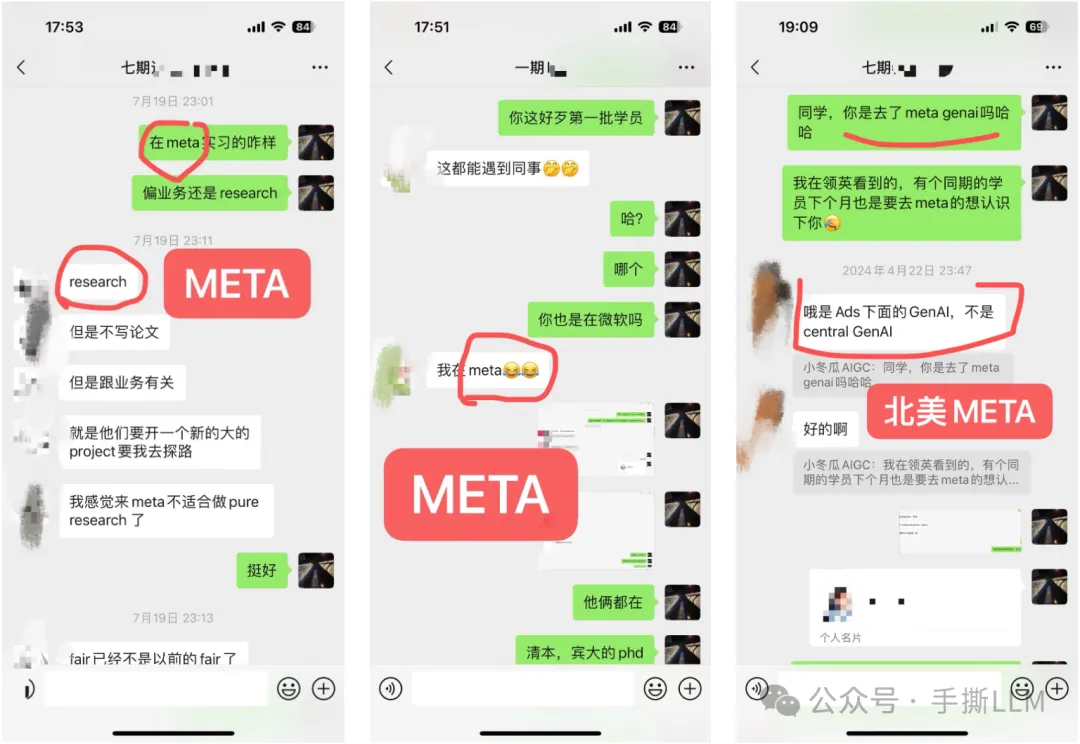
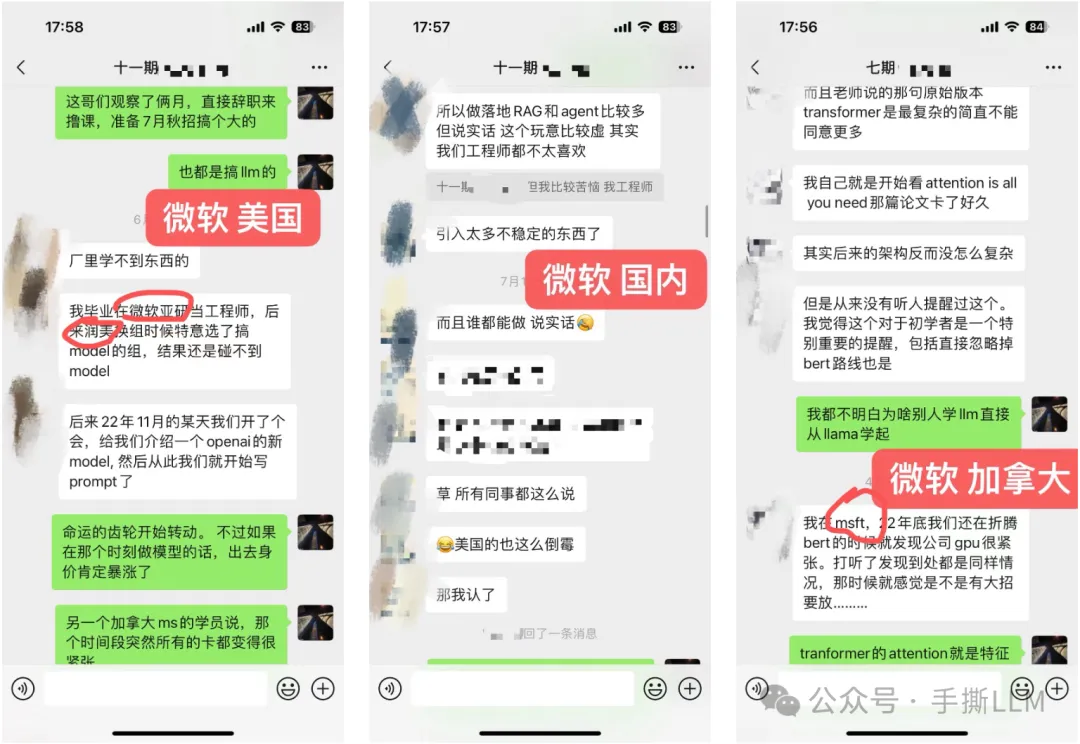
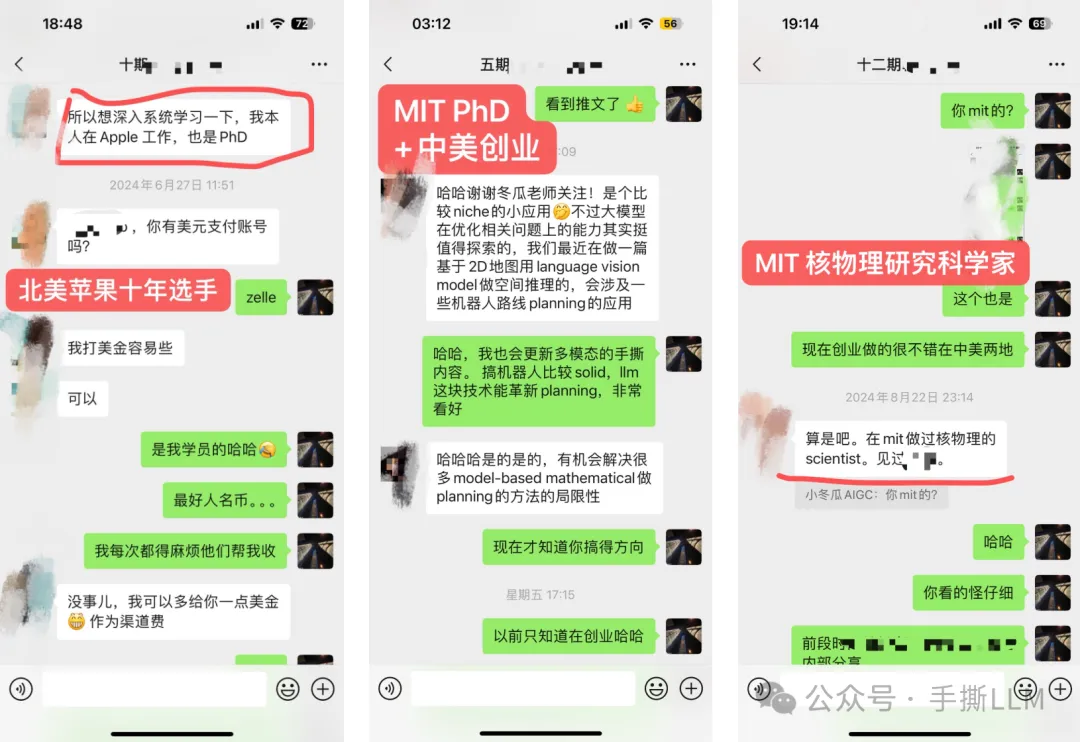
4.2 教学成果(已知部分展示)
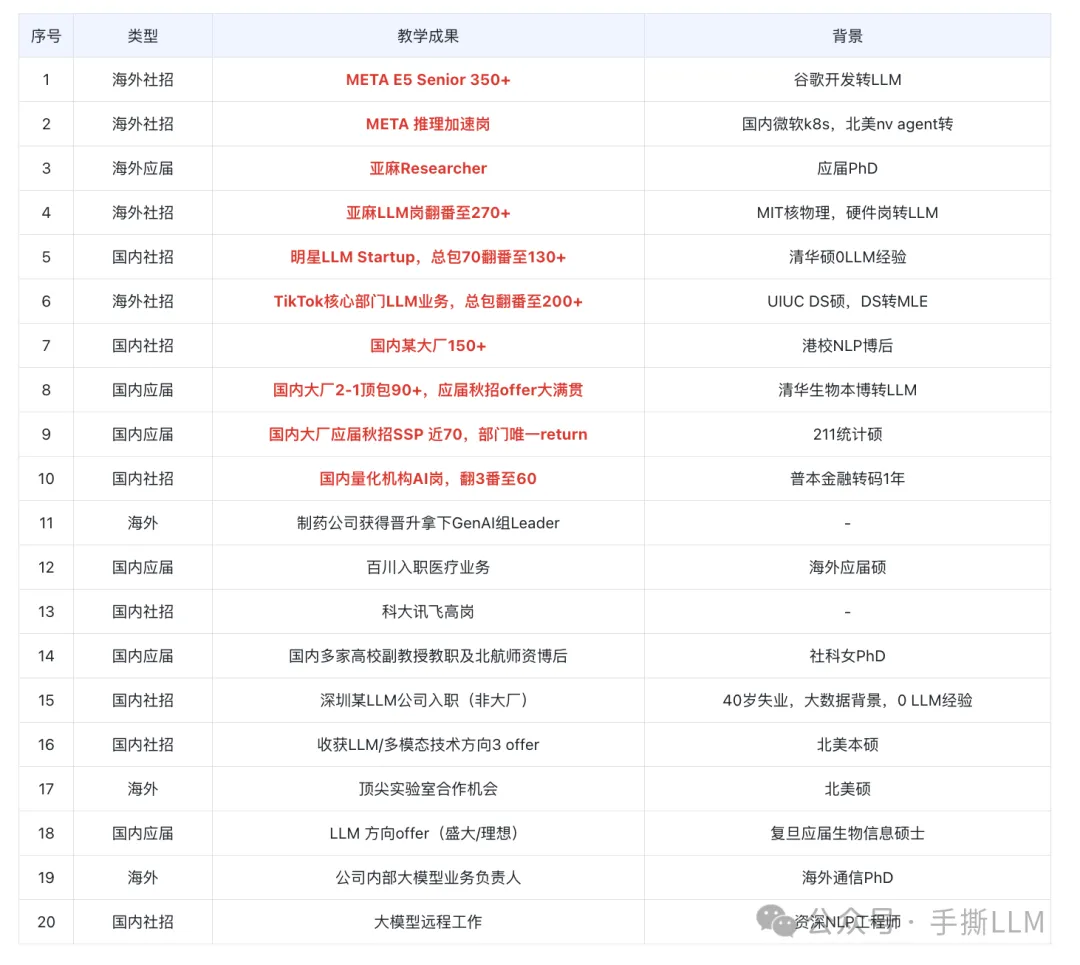
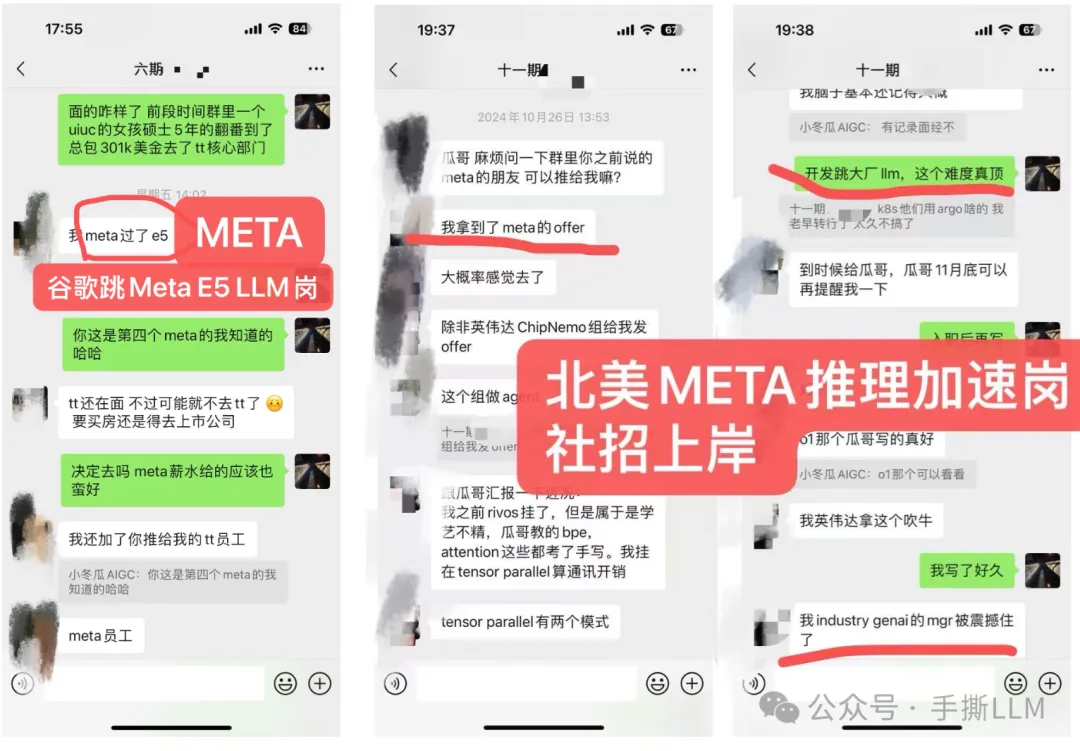
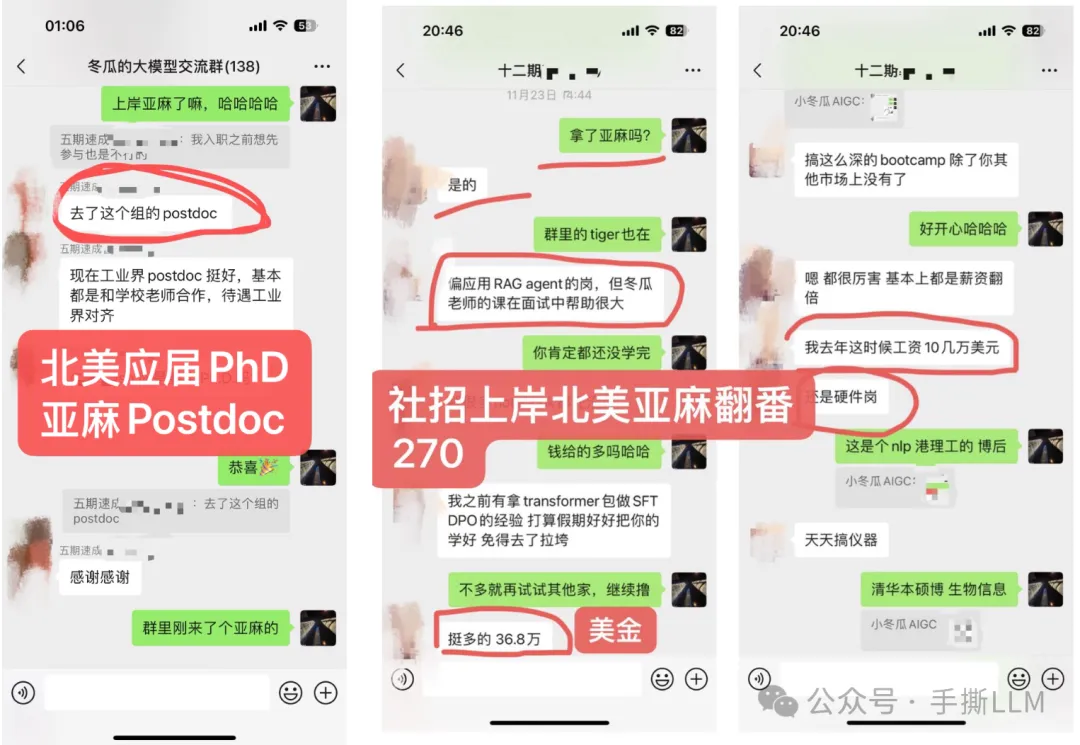
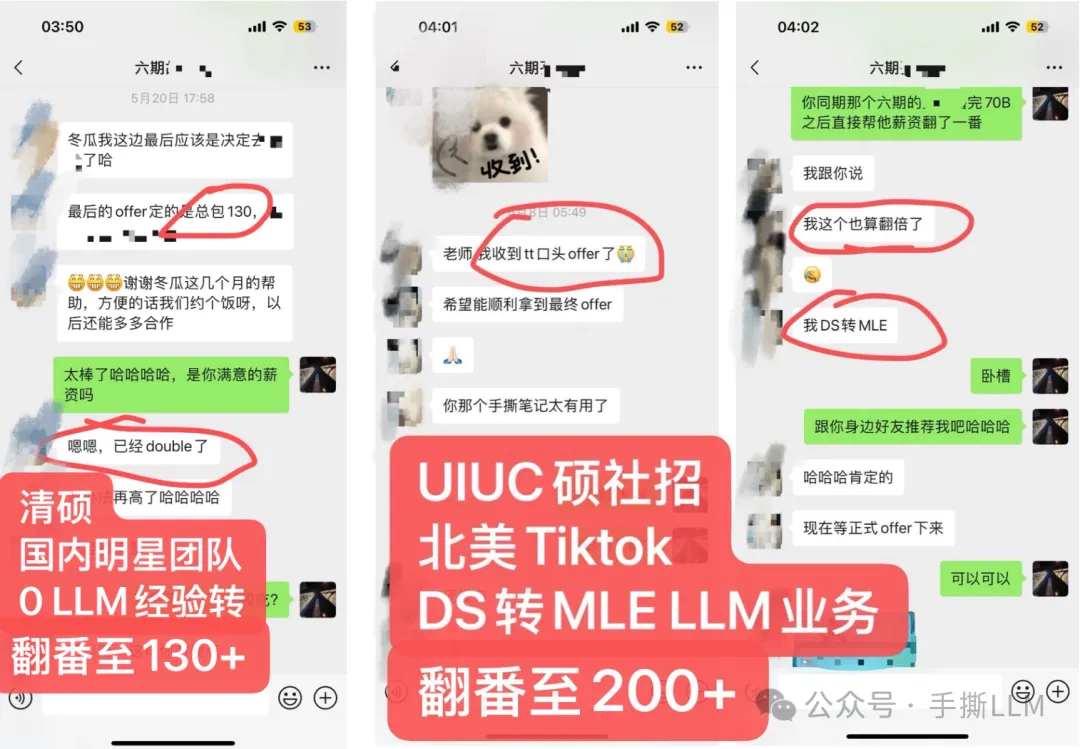

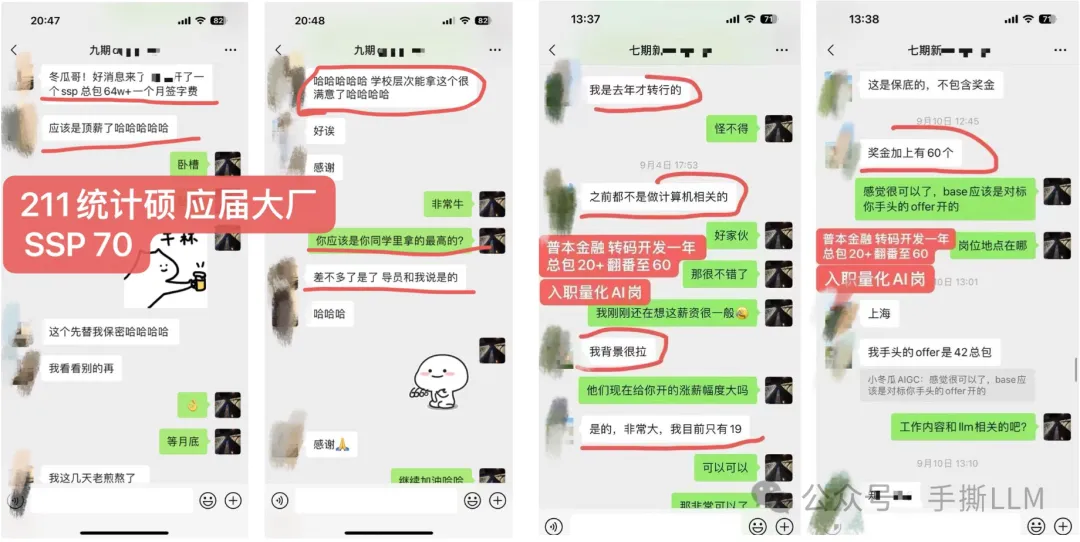
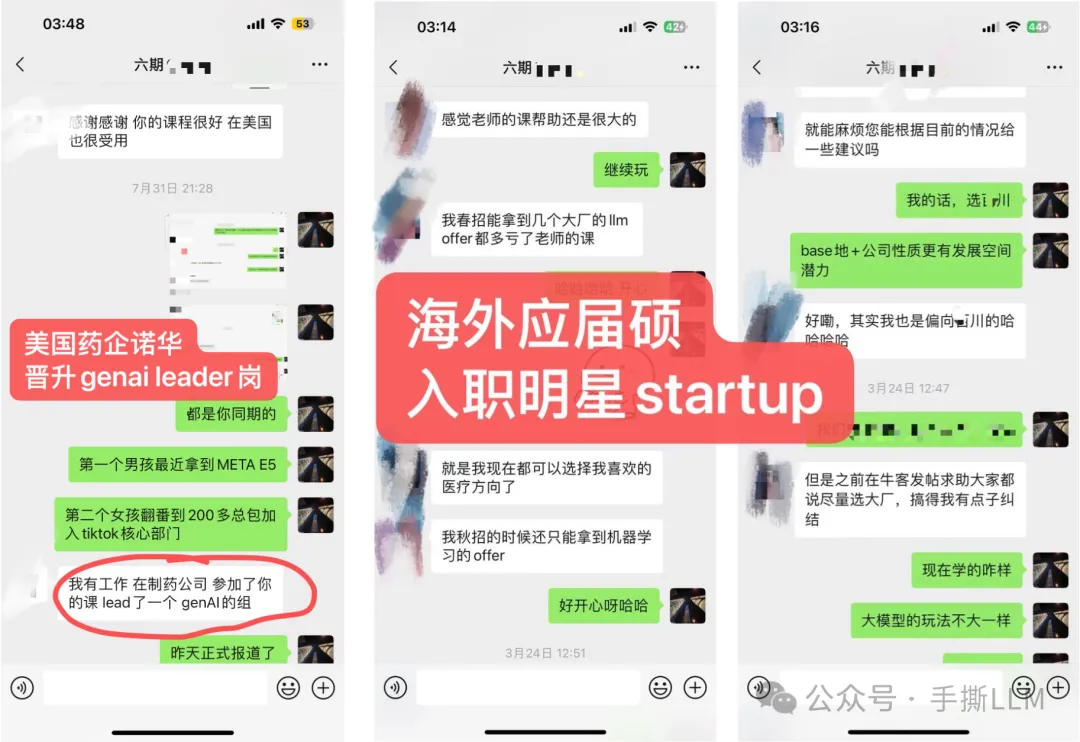
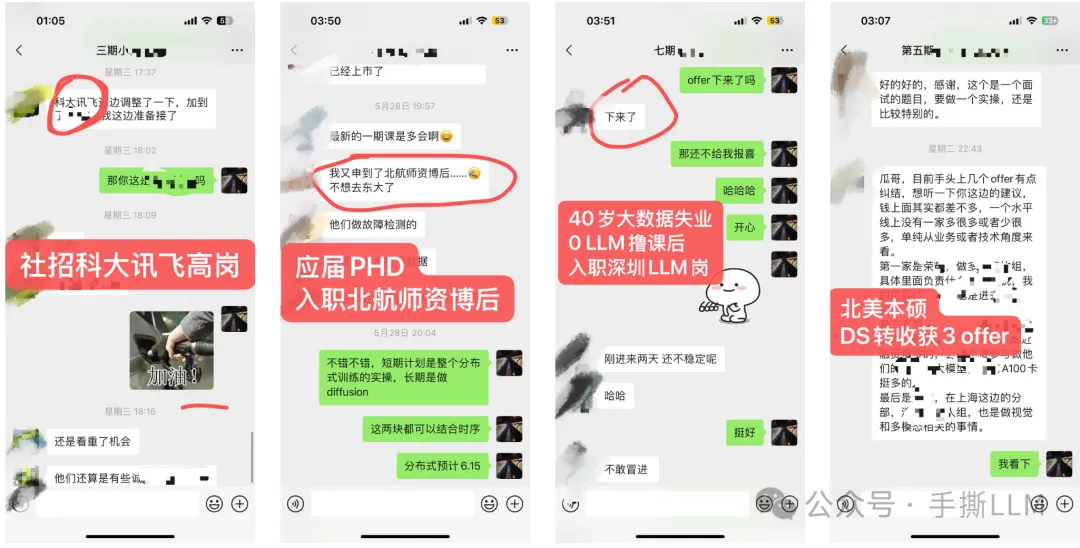
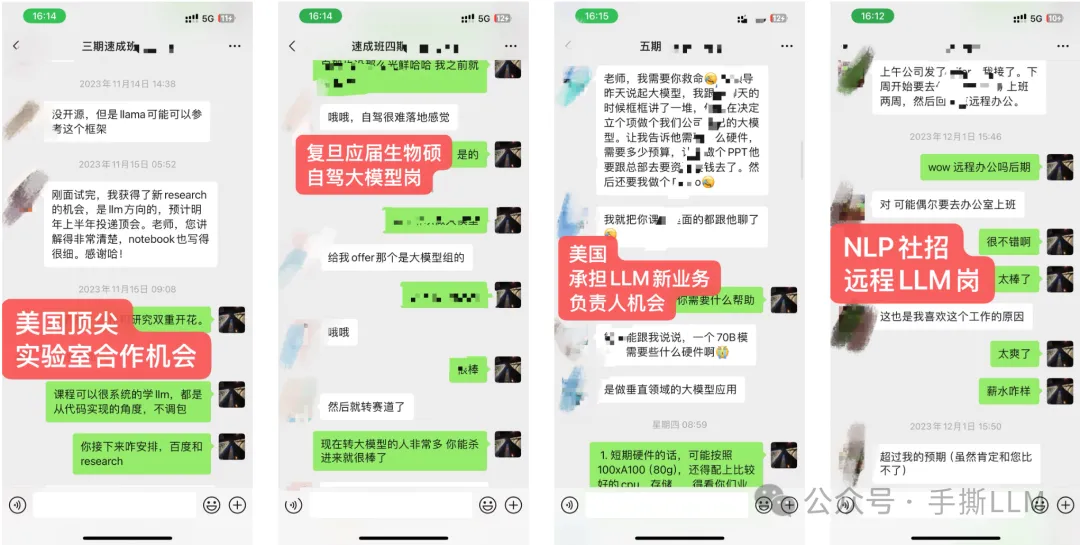
(注:不提供算力,本课程所提供项目可在多卡环境一键运行,能低成本run出大模型项目)
我是小冬瓜AIGC,原创超长文知识分享
原创课程已帮助多名同学上岸LLM赛道
知乎/小红书 :小冬瓜AIGC
我是
小冬瓜AIGC,原创超长文知识分享原创课程已帮助多名同学上岸
LLM赛道
知乎/小红书:小冬瓜AIGC
微信咨询xiaodongguaAIGC
(文:PaperAgent)
课程效果立竿见影!北美MIT、清北学员让我膜拜吧