跳至内容
OpenAI 的最初愿景,最终被一家国内创业公司实现了?
昨晚,大模型领域再次「热闹起来」,月之暗面发布在数学、代码、多模态推理能力层面全面对标 OpenAI 的满血版 o1 的多模态思考模型 K1.5。而最近大热的 DeepSeek 正式推出了 DeepSeek-R1,同样在数学、代码和自然语言推理等任务上比肩 OpenAI o1 正式版。
去年 12 月开源的大模型 DeepSeek-V3 刚刚掀起了一阵热潮,实现了诸多的不可能。这次开源的 R1 大模型则在一开始就让一众 AI 研究者感到「震惊」,人们纷纷在猜测这是如何做到的。
AutoAWQ 作者 Casper Hansen 表示,DeepSeek-R1 使用一种多阶段循环的训练方式:基础→ RL →微调→ RL →微调→ RL。
UC Berkeley 教授 Alex Dimakis 则认为 DeepSeek 现在已经处于领先位置,美国公司可能需要迎头赶上了。
目前,DeepSeek 在网页端、App 端和 API 端全面上线了 R1,下图为网页端对话界面,选择 DeepSeek-R1 就能直接体验。
体验地址:https://www.deepseek.com/
此次,DeepSeek 发布了两个参数为 660B 的 DeepSeek-R1-Zero 和 DeepSeek-R1,并选择开源了模型权重,同时允许用户使用 R1 来训练其他模型。
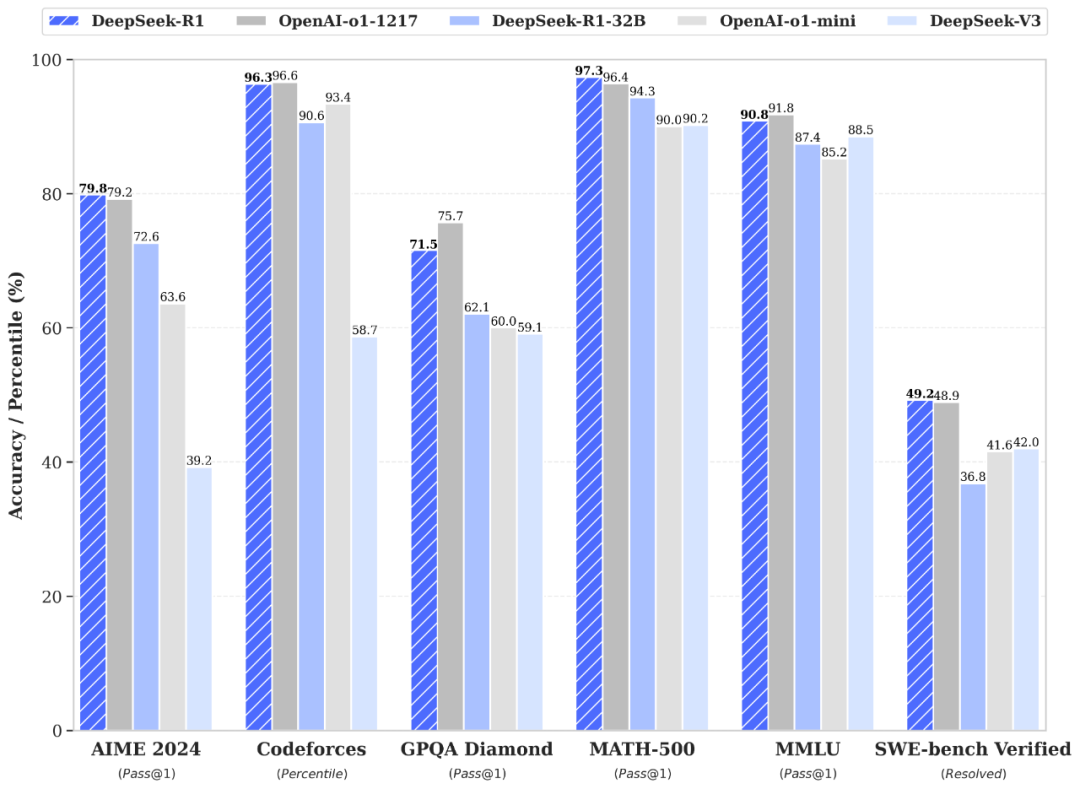
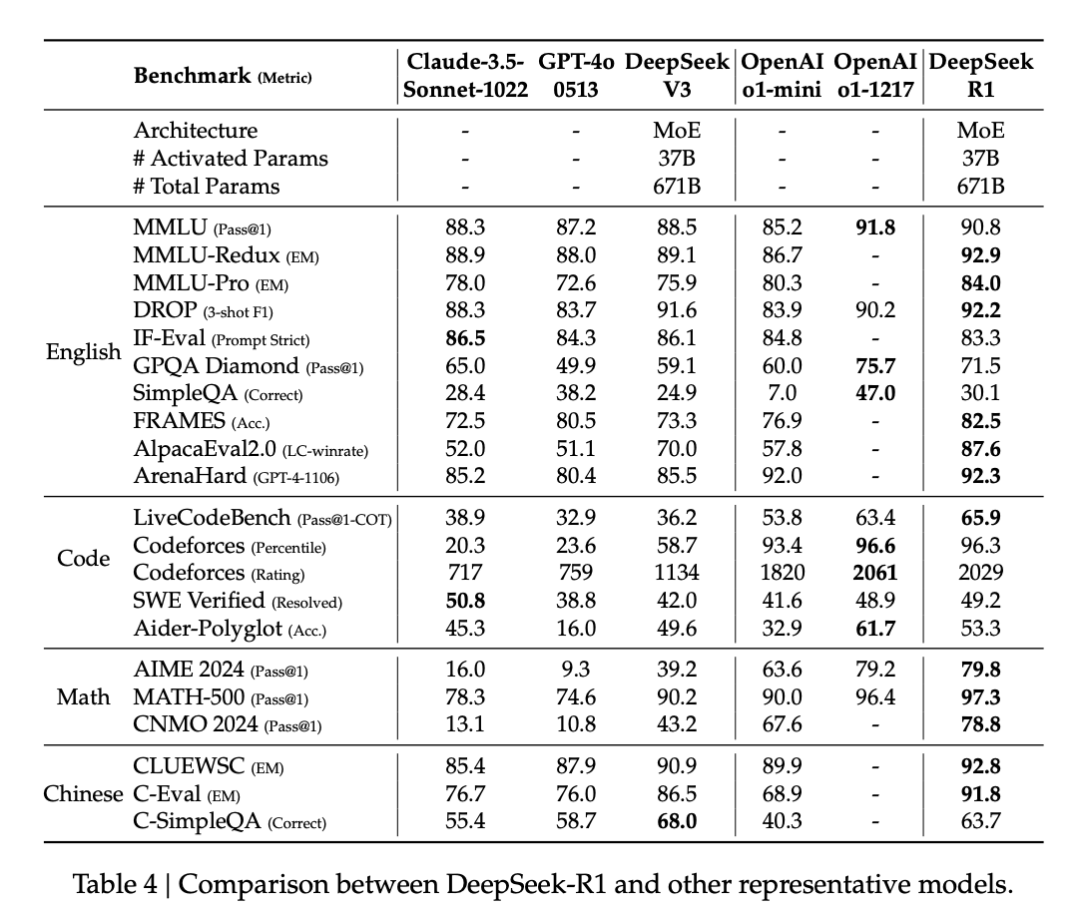
在技术层面,R1 在后训练阶段大规模使用了强化学习(RL)技术,在仅用非常少标注数据的情况下,极大提升了模型推理能力。下图为 R1 与 o1-1217、o1-mini、自家 DeepSeek-V3 在多个数据集上的性能比较,可以看到,R1 与 o1-1217 不相上下、互有胜负。
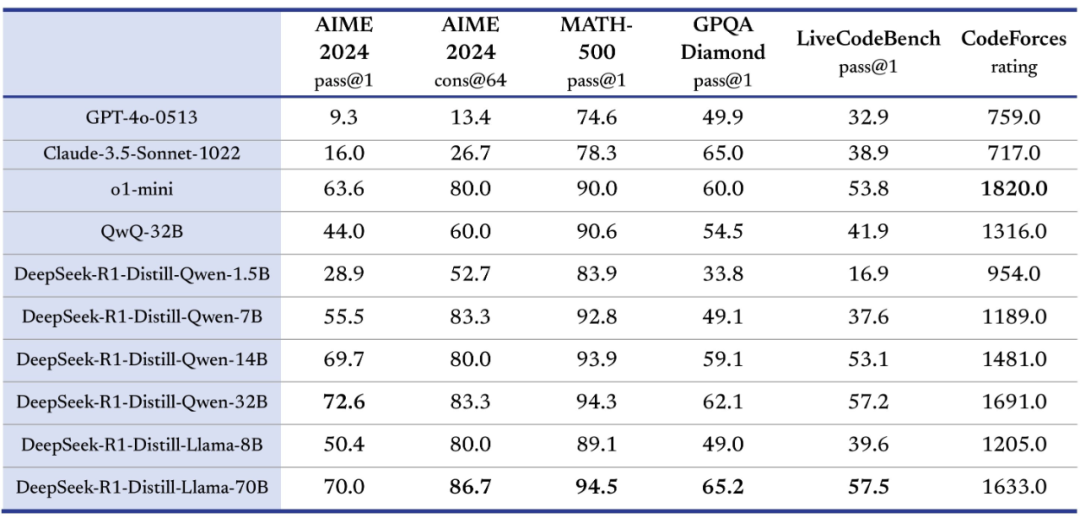
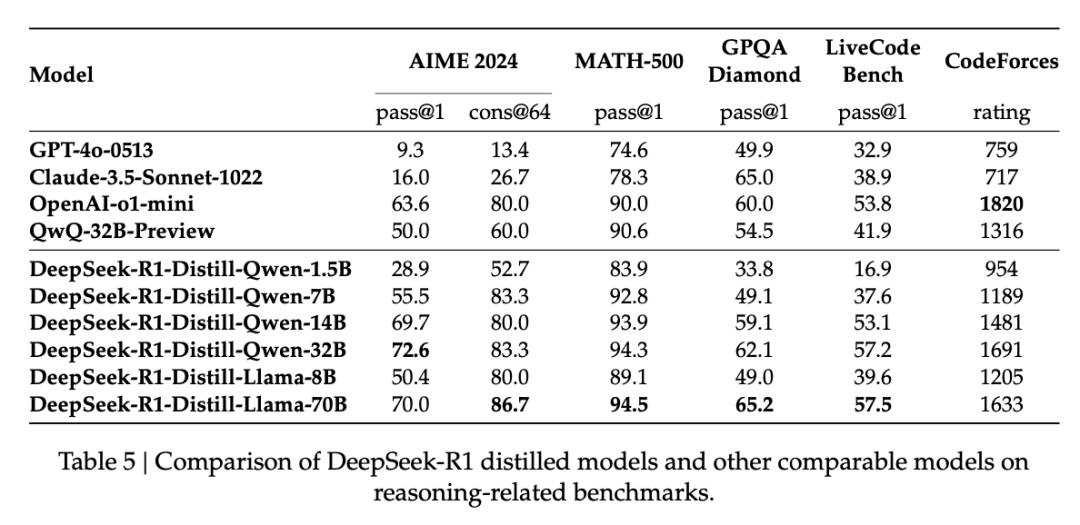
另外,DeepSeek-R1 蒸馏出了六个小模型,参数从小到大分别为 1.5B、7B、8B、14B、32B 以及 70B。这六个模型同样完全开源,旨在回馈开源社区,推动「Open AI」的边界。
模型下载地址:https://huggingface.co/deepseek-ai?continueFlag=f18057c998f54575cb0608a591c993fb
性能方面,蒸馏后的 R1 32B 和 70B 版本远远超过了 GPT-4o、Claude 3.5 Sonnet 和 QwQ-32B,并逼近 o1-mini。
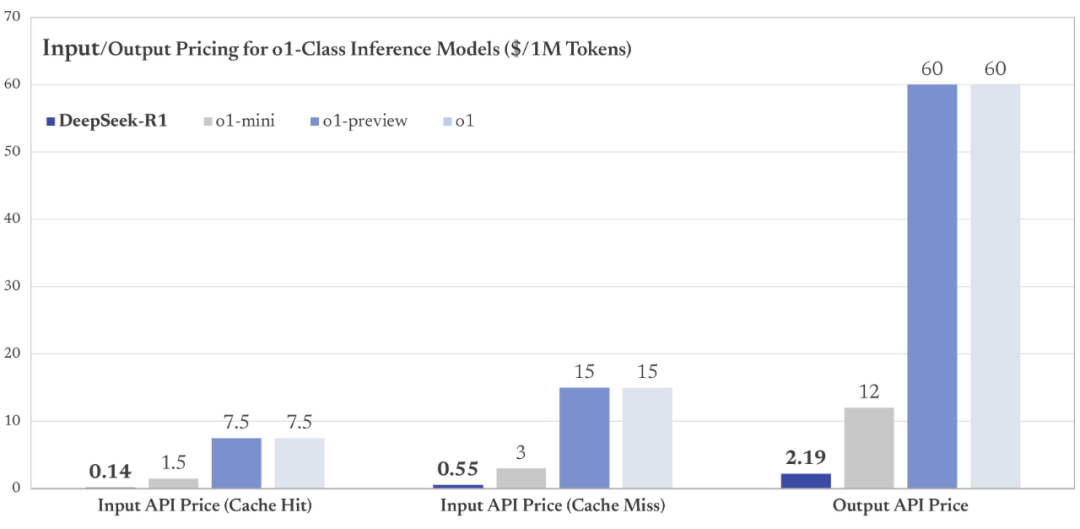
至于很多开发者关心的 DeepSeek-R1 API 价格,可以说是一如既往地给力。
DeepSeek-R1 API 服务的定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元。
显然,与 o1 的 API 定价比起来(每百万输入 tokens 15 美元、每百万输出 tokens 60 美元),DeepSeek 具有极高的性价比。
DeepSeek 秉持了开源到底的决心,将 R1 模型的训练技术全部开放,放出了背后的研究论文。
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
以往的研究主要依赖大量的监督数据来提升模型性能。DeepSeek 的开发团队则开辟了一种全新的思路:即使不用监督微调(SFT)作为冷启动,通过大规模强化学习也能显著提升模型的推理能力。如果再加上少量的冷启动数据,效果会更好。
为了做到这一点,他们开发了 DeepSeek-R1-Zero。具体来说,DeepSeek-R1-Zero 主要有以下三点独特的设计:
首先是采用了群组相对策略优化(GRPO)来降低训练成本。GRPO 不需要使用与策略模型同样大小的评估模型,而是直接从群组分数中估算基线。
对于每个输入问题 q,GRPO 算法会从旧策略中采样一组输出 {o1, o2, …, oG},形成评估群组,然后通过最大化目标函数来优化策略模型:
其中,优势值 A_i 通过标准化每个输出的奖励来计算:
其次是奖励设计。如何设计奖励,决定着 RL 优化的方向。DeepSeek 给出的解法是采用准确度和格式两种互补的奖励机制。
准确度奖励用于评估回答的正确性。在数学题中,模型需要用特定格式给出答案以便验证;在编程题中,则通过编译器运行测试用例获取反馈。
第二种是格式奖励,模型需要将思考过程放在 ‘<think>’ 和 ‘</think>’ 这两个特定的标签之间,提升输出的规范性。
该团队没有使用常用的神经网络奖励模型,是因为在大规模强化学习过程中,模型可能会出现「作弊」问题。同时也避免了重新训练奖励模型需要额外资源,简化了训练流程。
第三点是训练模版,在 GRPO 和奖励设计的基础上,开发团队设计了如表 1 所示的简单模板来引导基础模型。这个模板要求 DeepSeek-R1-Zero 先给出推理过程,再提供最终答案。这种设计仅规范了基本结构,不对内容施加任何限制或偏见,比如不强制要求使用反思性推理或特定解题方法。这种最小干预的设计能够清晰地观察模型在 RL 的进步过程。
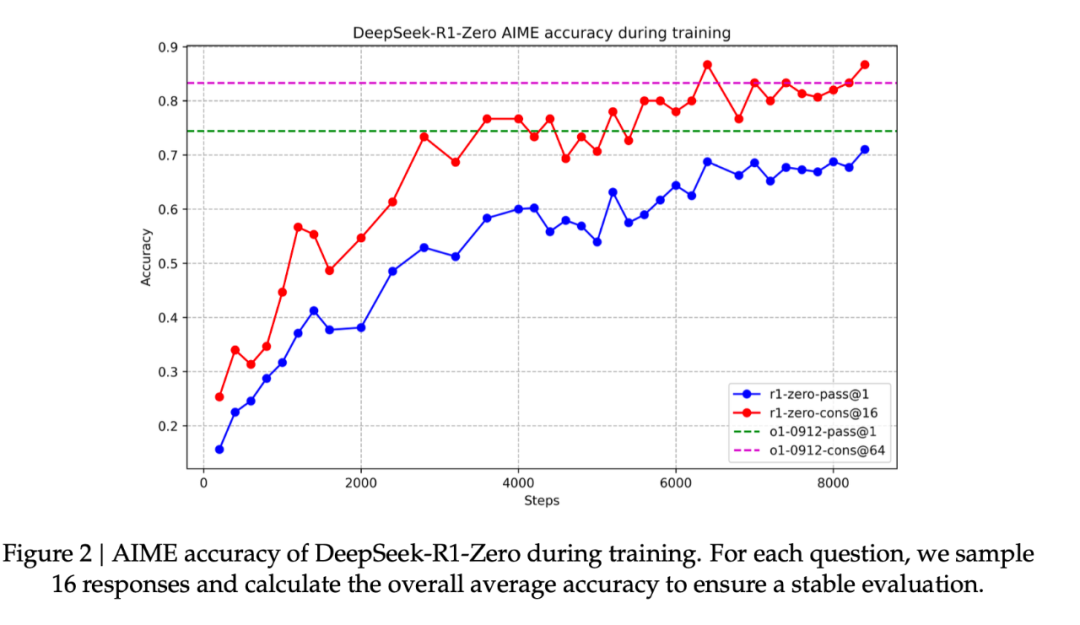
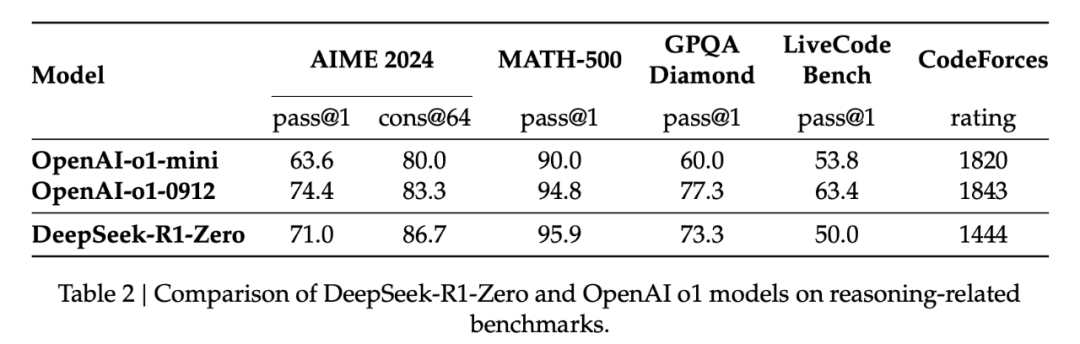
DeepSeek-R1-Zero 的提升也非常显著。如图 2 所示,做 2024 年的 AIME 数学奥赛试卷,DeepSeek-R1-Zero 的平均 pass@1 分数从最初的 15.6% 显著提升到了 71.0%,达到了与 OpenAI-o1-0912 相当的水平。在多数投票机制中,DeepSeek-R1-Zero 在 AIME 中的成功率进一步提升到了 86.7%,甚至超过了 OpenAI-o1-0912 的表现。
DeepSeek-R1-Zero 与 OpenAI 的 o1-0912 在多个推理相关基准测试上的得分对比。
在训练过程中,DeepSeek-R1-Zero 展现出了显著的自我进化能力。它学会了生成数百到数千个推理 token,能够更深入地探索和完善思维过程。
随着训练的深入,模型也发展出了一些高级行为,比如反思能力和探索不同解题方法的能力。这些都不是预先设定的,而是模型在强化学习环境中自然产生的。
特别值得一提的是,开发团队观察到了一个有趣的「Aha Moment」。在训练的中期阶段,DeepSeek-R1-Zero 学会了通过重新评估初始方法来更合理地分配思考时间。这可能就是强化学习的魅力:只要提供正确的奖励机制,模型就能自主发展出高级的解题策略。
不过 DeepSeek-R1-Zero 仍然存在一些局限性,如回答的可读性差、语言混杂等问题。
与 DeepSeek-R1-Zero 不同,为了防止基础模型在 RL 训练早期出现不稳定的冷启动阶段,开发团队针对 R1 构建并收集了少量的长 CoT 数据,以作为初始 RL actor 对模型进行微调。为了收集此类数据,开发团队探索了几种方法:以长 CoT 的少样本提示为例、直接提示模型通过反思和验证生成详细答案、以可读格式收集 DeepSeek-R1-Zero 输出、以及通过人工注释者的后处理来细化结果。
DeepSeek 收集了数千个冷启动数据,以微调 DeepSeek-V3-Base 作为 RL 的起点。与 DeepSeek-R1-Zero 相比,冷启动数据的优势包括:
-
可读性:DeepSeek-R1-Zero 的一个主要限制是其内容通常不适合阅读。响应可能混合多种语言或缺乏 markdown 格式来为用户突出显示答案。相比之下,在为 R1 创建冷启动数据时,开发团队设计了一个可读模式,在每个响应末尾包含一个摘要,并过滤掉不友好的响应。
-
潜力:通过精心设计具有人类先验知识的冷启动数据模式,开发团队观察到相较于 DeepSeek-R1-Zero 更好的性能。开发团队相信迭代训练是推理模型的更好方法。
在利用冷启动数据上对 DeepSeek-V3-Base 进行微调后,开发团队采用与 DeepSeek-R1-Zero 相同的大规模强化学习训练流程。此阶段侧重于增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等推理密集型任务中。
为了缓解语言混合的问题,开发团队在 RL 训练中引入了语言一致性奖励,其计算方式为 CoT 中目标语言单词的比例。虽然消融实验表明这种对齐会导致模型性能略有下降,但这种奖励符合人类偏好,更具可读性。
最后,开发团队将推理任务的准确率和语言一致性的奖励直接相加,形成最终奖励。然后对微调后的模型进行强化学习 (RL) 训练,直到它在推理任务上实现收敛。
当面向推理导向的强化学习收敛时,开发团队利用生成的检查点为后续轮次收集 SFT(监督微调)数据。此阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务中的能力。
开发团队通过从上述强化学习训练的检查点执行拒绝采样来整理推理提示并生成推理轨迹。此阶段通过合并其他数据扩展数据集,其中一些数据使用生成奖励模型,将基本事实和模型预测输入 DeepSeek-V3 进行判断。
此外,开发团队过滤掉了混合语言、长段落和代码块的思路链。对于每个提示,他们会抽取多个答案,并仅保留正确的答案。最终,开发团队收集了约 60 万个推理相关的训练样本。
为了进一步使模型与人类偏好保持一致,这里还要实施第二阶段强化学习,旨在提高模型的有用性和无害性,同时完善其推理能力。
具体来说,研究人员使用奖励信号和各种提示分布的组合来训练模型。对于推理数据,遵循 DeepSeek-R1-Zero 中概述的方法,该方法利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程;对于一般数据,则采用奖励模型来捕捉复杂而微妙的场景中的人类偏好。
最终,奖励信号和多样化数据分布的整合使我们能够训练出一个在推理方面表现出色的模型,同时优先考虑有用性和无害性。
为了使更高效的小模型具备 DeekSeek-R1 那样的推理能力,开发团队还直接使用 DeepSeek-R1 整理的 80 万个样本对 Qwen 和 Llama 等开源模型进行了微调。研究结果表明,这种简单的蒸馏方法显著增强了小模型的推理能力。
得益于以上多项技术的创新,开发团队的大量基准测试表明,DeepSeek-R1 实现了比肩业内 SOTA 推理大模型的硬实力,具体可以参考以下结果:
(文:机器之心)






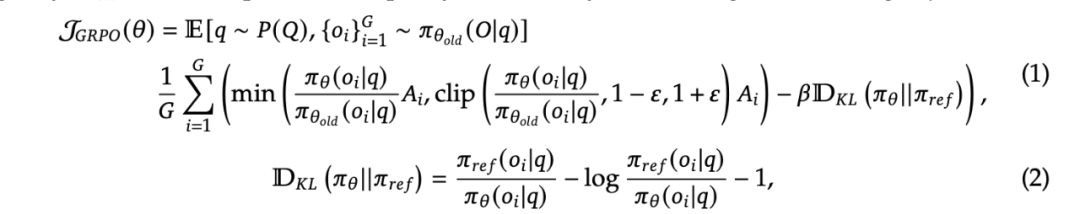
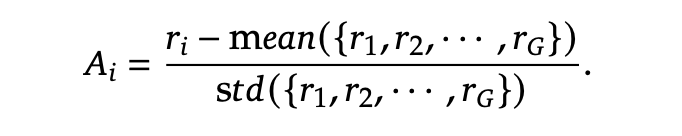

哇塞,这不就实现了AI的全能力嘛!开源第一线,看来是未来的新标杆了!