


刚看完DeepSeek R1技术报告论文《DeepSeek-R1:强化学习驱动的大语言模型推理能力提升》,这篇论文最令人震惊的点在于:
DeepSeek-R1-Zero 作为一个完全没有使用任何监督微调(SFT)数据,仅通过纯粹的强化学习(RL)训练的模型,展现出了惊人的推理能力,推理基准测试上可以媲美乃至超越 OpenAI 的 o1 系列模型(如 o1-0912),完全开源,报告毫无保留的奉上了R1的训练秘密,值得注意的是,这是第一个开放研究验证了 LLM 的推理能力可以完全通过 RL 来激励,而不需要 SFT。这一突破为该领域的未来发展铺平了道路
具体来说,以下几点尤其令人震惊:
纯 RL 的成功: 以往的模型在提升推理能力时,通常依赖于 SFT 作为预训练步骤。DeepSeek-R1-Zero 打破了这一常规,证明了仅通过设计合适的奖励机制和训练模板,就可以让模型在没有 SFT 的情况下(冷启动),通过自我博弈和进化,自发地学习到复杂的推理策略,这让我想起了AlphaZero–从零开始掌握围棋、将棋和国际象棋,而无需先模仿人类大师的棋步,这是整个技术报告最重要的启示
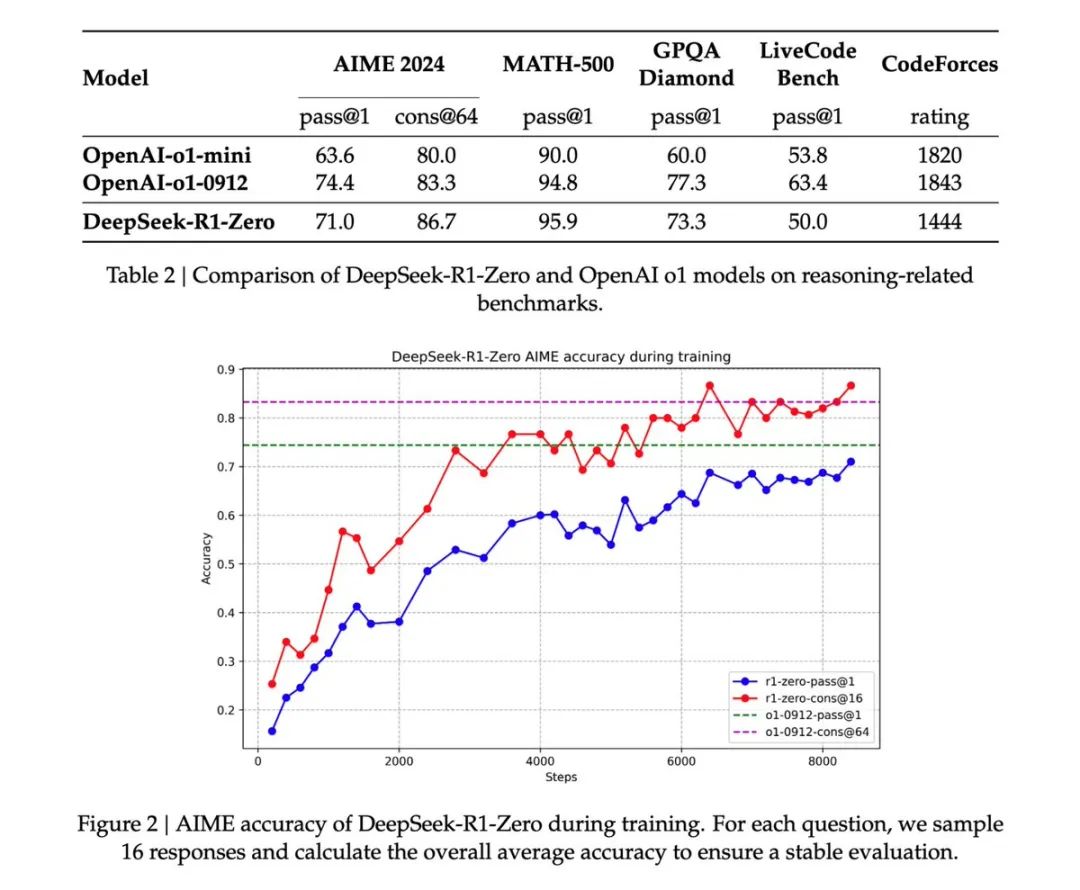
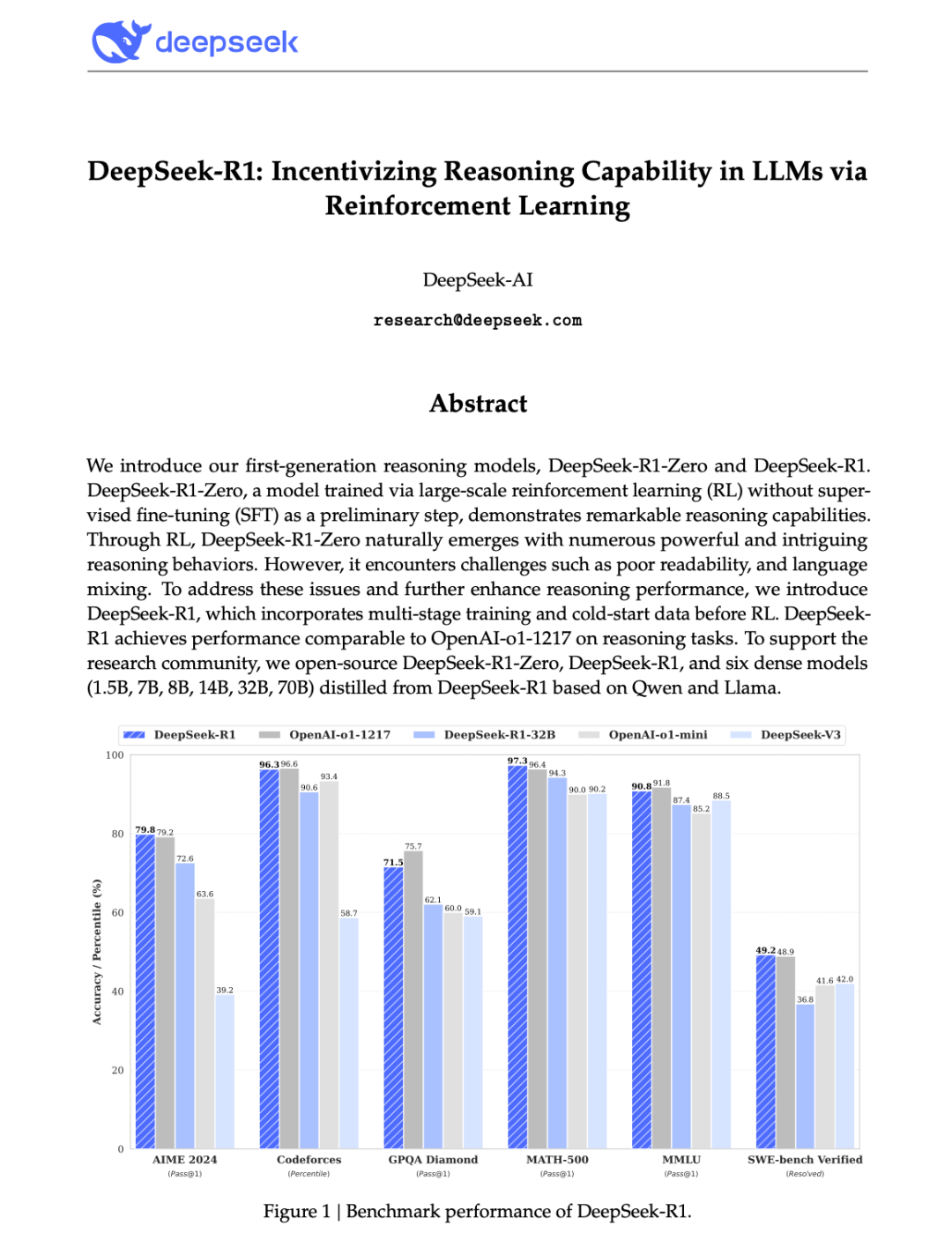
惊人的性能提升: DeepSeek-R1-Zero 在 AIME 2024 基准测试上,pass@1 分数从 15.6% 提升到了 71.0%,通过多数投票更是达到了 86.7%,与 OpenAI-01-0912 的表现相当甚至更好。这种巨大的性能飞跃仅仅是通过 RL 实现的,这非常令人震撼。
“顿悟”现象(Aha Moment): 论文中描述了 DeepSeek-R1-Zero 在训练过程中出现的“顿悟”现象,模型会自发地重新评估之前的步骤,并进行反思,类似于人类的“灵光一现”。这种自发涌现的复杂行为,展示了纯 RL 训练的巨大潜力,也为理解 AI 的学习机制提供了新的视角

无监督学习的潜力: DeepSeek-R1-Zero 的成功,证明了无监督或弱监督学习方法在提升模型推理能力方面的巨大潜力。这对于那些难以获取大量高质量标注数据的领域来说,具有重要的意义
除了之前提到的 DeepSeek-R1-Zero 仅通过纯强化学习 (RL) 展现出惊人推理能力之外,我还注意到以下几个同样令人印象深刻的点:
1. 蒸馏技术有效提升小型模型能力:
-
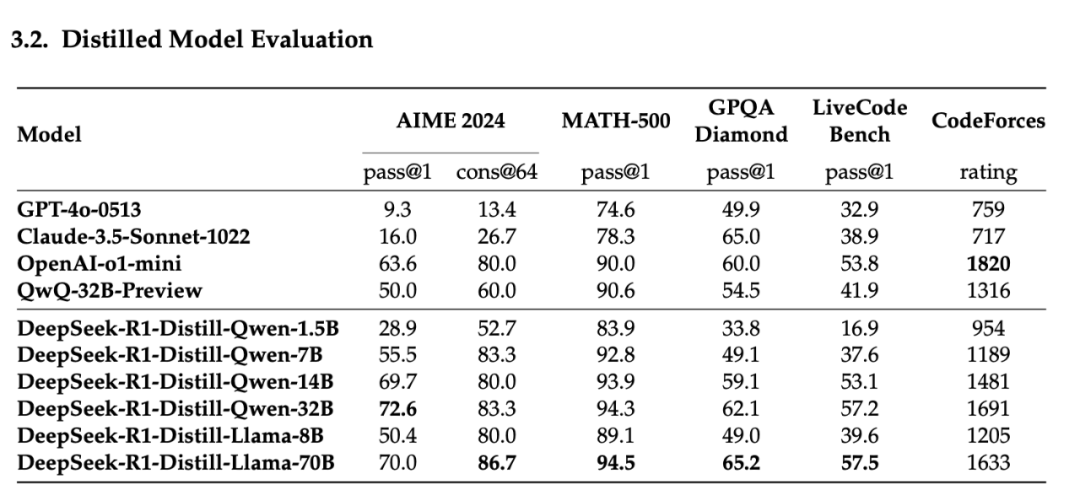
• 蒸馏效果显著: 论文展示了将 DeepSeek-R1 的推理能力蒸馏到较小的模型(如 Qwen 和 Llama 系列)上的显著效果。例如,DeepSeek-R1-Distill-Qwen-7B 在多个基准测试上超过了非推理模型 GPT-40-0513,而 14B 模型则全面超越了 QwQ-32B-Preview。
-
• 小型模型的巨大潜力: 这说明通过合理的蒸馏策略,小型模型也能获得强大的推理能力,为资源受限场景下的应用提供了可能
2. 对比实验揭示了蒸馏的优势:
-
• 同等规模下,蒸馏优于纯 RL: 论文通过对比实验,发现将 DeepSeek-R1 蒸馏到 Qwen-32B 上的效果,远好于直接在 Qwen-32B-Base 上进行大规模 RL 训练。这表明对于较小的模型,直接学习大型模型的推理模式比自身探索更为有效
-
• 对计算资源的考量: 这也暗示了在提升模型能力时,需要综合考虑计算资源和效率,蒸馏在特定情况下可能是更优的选择
写在最后:
坦诚的失败尝试分析:
分享失败经验的价值: 论文坦诚地分享了在探索过程中尝试 PRM 和 MCTS 两种方法时遇到的挑战和失败。这种开放的态度对于学术研究来说非常宝贵,可以帮助其他人少走弯路
对未来研究的启示: 对失败原因的分析,也为未来的研究提供了启示,例如指出了 PRM 在定义细粒度步骤和判断中间步骤正确性方面的困难,以及 MCTS 在扩展到语言模型时面临的搜索空间爆炸和价值模型训练难题
参考:
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
⭐
(文:AI寒武纪)