
字节开源高精度文档解析大模型Dolphin:轻量高效,性能超GPT4.1、Mistral-OCR!

字节跳动开源文档解析模型Dolphin,相比同类大模型提升2倍解析效率。其采用两阶段解析方法,先解析结构后内容,性能超越GPT-4.1等通用多模态和垂类OCR模型。
字节跳动开源文档解析模型Dolphin,相比同类大模型提升2倍解析效率。其采用两阶段解析方法,先解析结构后内容,性能超越GPT-4.1等通用多模态和垂类OCR模型。

刚看完《DeepSeek-R1:强化学习驱动的大语言模型推理能力提升》论文。该研究证明了仅通过纯强化学习训练的模型,也能媲美甚至超越使用监督微调的数据训练的模型。这一突破展示了无监督学习的巨大潜力,并分享了小型模型通过蒸馏技术获得强大推理能力的方法。

Hugging Face团队利用Llama 1B模型在数学测试中超过8倍大模型的性能,并改进了搜索策略以提升模型表现。研究涉及多种方法,最终发现DVTS方法能显著提高简单/中等难度问题的性能。
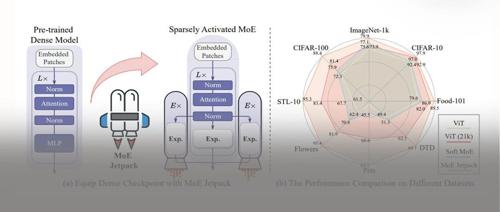
华中科技大学提出MoE Jetpack框架,利用密集模型预训练权重微调为混合专家模型,显著提升精度和收敛速度。