TNNLS 2025 通用的视觉Backbone!TransXNet: 全局动态性+局部动态性=性能强大,代码已开源!
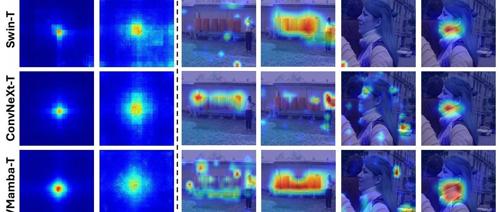
香港大学俞益洲团队提出TransXNet,结合D-Mixer和Multiscale Feed-forward Network架构,在图像分类、目标检测、语义分割任务上均取得显著性能提升。
香港大学俞益洲团队提出TransXNet,结合D-Mixer和Multiscale Feed-forward Network架构,在图像分类、目标检测、语义分割任务上均取得显著性能提升。

V²Flow团队发布的新开源框架V²Flow解决了视觉Token与大语言模型词表的不一致问题,实现了高保真自回归图像生成。该技术通过视觉词汇重采样器将视觉内容嵌入到LLM的词汇空间中,并使用掩码自回归流匹配解码器进行视觉重建,显著提高了压缩效率和生成质量。
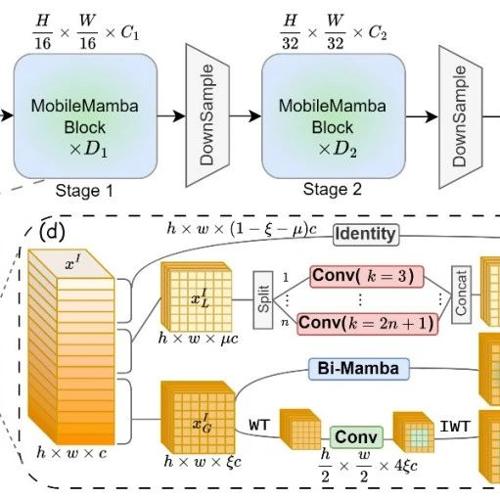
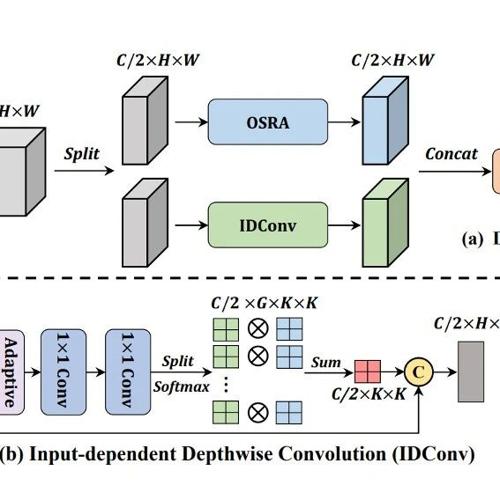
该框架通过三阶段网络设计、高效多感受野特征交互模块以及训练测试策略,实现了在分类任务及高分辨率下游任务上的高性能与低效率平衡。
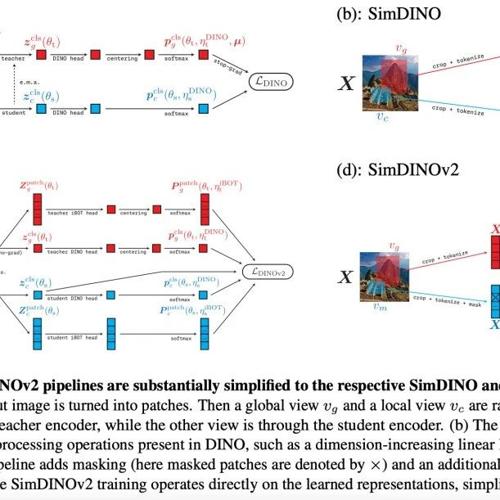
本文介绍了一种简化DINO和DINOv2训练流程的方法,通过编码率正则化提升模型性能。该方法提出SimDINO和SimDINOv2模型,减少了复杂的调整步骤和超参数设置,实验结果表明新模型在多种下游任务中性能优于原版模型,并且对不同设计选择表现出更强的鲁棒性。
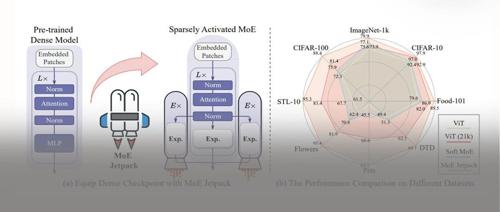
华中科技大学提出MoE Jetpack框架,利用密集模型预训练权重微调为混合专家模型,显著提升精度和收敛速度。