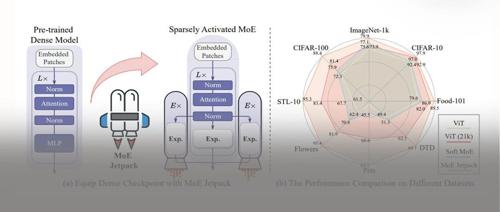
NeurIPS 2024|收敛速度最高8倍,准确率提升超30%!华科发布MoE Jetpack框架 2024年12月15日20时2024年11月21日23时 作者 新智元 华中科技大学提出MoE Jetpack框架,利用密集模型预训练权重微调为混合专家模型,显著提升精度和收敛速度。
收敛速度最高8倍,准确率提升超30%!华科发布MoE Jetpack框架 NeurIPS 2024 2024年11月20日21时 作者 每时AI 华中科技大学提出MoE Jetpack框架,利用密集激活模型权重微调出混合专家(MoE)模型,大幅提升了精度和收敛速度,解决MoE预训练需求高问题。