
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2025我们继续出发。
一个词形容近期的国内大模型圈:“神仙打架”。
深度求索(DeepSeek)和月之暗面(Kimi)几乎是前后脚先后发布了自家新一代的推理模型:DeepSeek-R1和k1.5。


太像了,实在是太像了。
都是推理模型,都在对标OpenAI的o1,基准测试结果都很亮眼,更有趣的是,都公开了对应模型的技术文档。
先来搂一眼这两个模型的基准测试。
DeepSeek-R1和k1.5这一次都很给国产模型长志气,敢于直接和满血版的o1硬刚。
DeepSeek-R1在“AIME 2024”、“MATH-500”、“SWE-bench Verified”三项基准测试中获得了高于o1的成绩。

无独有偶,k1.5同样在“AIME 2024”和“MATH-500”打败了o1,在“Codeforces”测试中和o1打平。
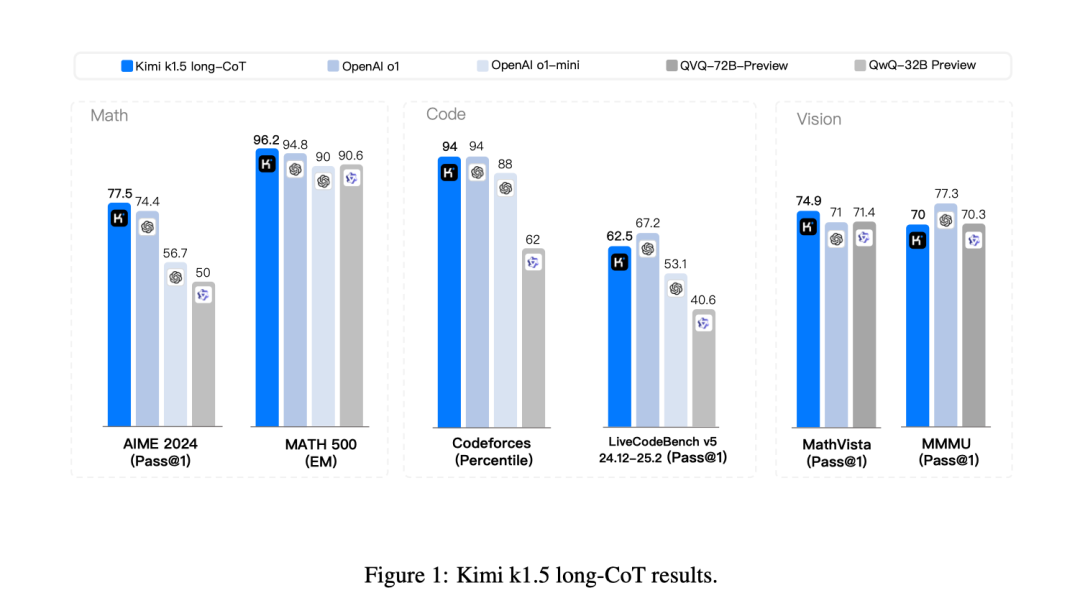
如果把上面两张图里重叠的信息汇总一下,就会得到下面这个表格。
| 基准测试 | DeepSeek-R1 (%) | Kimi k1.5 (%) | OpenAI o1 (%) |
|---|---|---|---|
| AIME 2024 (Pass@1) | 79.8 | 77.5 | 79.2 |
| Codeforces (Percentile) | 96.3 | 94 | 96.6 |
| MATH-500 (Pass@1) | 97.3 | 96.2 | 96.4 |
除去微小的差异,这三个模型从基准测试上来看,性能几乎一致。
深入查看这两个模型的技术报告,我发现了一些更有趣的结论。
首先,强化学习(RL)很重要。 DeepSeek-R1和Kimik1.5不约而同地将 强化学习(RL) 视为提升LLM推理能力的核心技术,并都在探索如何超越传统的“预训练+监督微调(SFT)”的技术范式。这其实很好理解,因为高质量训练数据不够了!OpenAI也遇到了类似的问题,所以它在推理模型押重注,all in o3。
从让模型拟合人类标注的数据,到利用RL让模型进行自主学习和演化,这种转变代表了一种更高级的训练理念,即赋予模型更强的自主性和探索能力,使其能够像人类一样通过与环境的交互来不断学习进步。
其次,长上下文 (Long Context) 很重要。 Kimi在k1.5技术文档里明确指出“长上下文扩展”是其核心技术之一,并将RL的上下文窗口扩展到了128k,这使得k1.5能够处理更长的文本输入,捕捉更远距离的依赖关系,从而更好地理解复杂的语境。DeepSeek-R1同样在技术文档中反复强调模型能够生成长Chain-of-Thought (CoT),并且在长上下文依赖的任务,比如FRAMES,表现出色。
毕竟,只有能够处理足够长的上下文信息,模型才能进行更深入、更复杂的推理。
接着,模型蒸馏技术很重要。 DeepSeek-R1和k1.5都将经过RL训练的推理模型作为“老师”,将其知识蒸馏到较小的“学生”模型上。DeepSeek-R1蒸馏出了一系列对标o1-mini的小参数模型,从1.5B到70B不等。k1.5文档虽然没有明确说到“蒸馏”技术,但其实“Long2Short技术”本质上就是一种模型蒸馏的思想:将Long-CoT模型(可以视为大模型)的知识、能力迁移到Short-CoT模型(可以视为小模型)上,利用大模型的知识来提升小模型的性能。 尤其是“Long2Short技术”中的最短拒绝采样和DPO技术。
这种做法的效果无疑是明显的,证明了蒸馏技术可以将大模型的推理能力有效地迁移到小模型,在保证性能的同时降低计算成本和提高推理速度。
最后,基于规则的奖励机制(rule-based reward)很重要。 相比于基于模型的奖励,基于规则的奖励机制更为直接和高效。基于模型的奖励存在被“攻击”的风险,本身就是一个难题,因此直接制定规则来评判模型输出的质量,成了更可靠的选择。
比如,一道数学题,可以直接判断答案是否正确;一道代码题,可以直接运行代码,检查测试用例是否通过。
当然,DeepSeek-R1和k1.5也有不同。
DeepSeek-R1直接就向所有用户开放了网页端和API的使用权限,并且模型本身是开源的。k1.5则需要等待灰度推送。
别的不说,就冲这一点,就值得给DeepSeek一个大大的赞!
最后,附上之前的DeepSeek-R1-Lite一直答不出来的问题测试。思考11秒搞定,轻松且随意!

附录
附上文章中相关基准测试的简要介绍。
-
AIME 2024 (Pass@1)
AIME(American Invitational Mathematics Examination),美国数学竞赛,题目以复杂的数学推理为主,考察解题能力和逻辑思维。Pass@1表示模型首次尝试解答的成功率。 -
Codeforces (Percentile)
全球性的编程竞赛平台,提供算法和数据结构相关的编程挑战。基准测试结果中的百分位数表示模型在所有参赛者中的排名位置,例如96.3%表示模型超过了96.3%的参赛者。 -
GPQA Diamond (Pass@1)
GPQA(Graduate-Level Google-Proof Q&A Benchmark)的Diamond子集包含生物、物理和化学领域最具挑战性的问题。这些问题设计得非常复杂,测试AI模型的高级推理能力和科学知识。 -
MATH-500 (Pass@1)
MATH-500,一个包含500道数学题目的基准测试,涵盖代数、微积分和概率等多个主题,评估模型在数学计算和推理方面的能力。 -
MMLU (Pass@1)
MMLU(Massive Multitask Language Understanding),一项多任务语言理解基准测试,涵盖57个学科,包括STEM、人文和社会科学,测试模型在零样本或少样本情况下的知识广度和推理能力。 -
SWE-bench Verified (Resolved)
SWE-bench Verified,评估AI模型解决实际软件工程问题的能力。问题来自GitHub开源项目,要求模型生成代码修复补丁并通过单元测试。Resolved指标表示模型成功解决问题的比例。
(文:AI信息Gap)
小EKB又来装逼了!他的AI信息Gap公众号简直就是个宝藏,AI知识、工具测评样样都有。他不仅分析得深刻,还能预测未来AI会越来越强,甚至比外挂还要强…