

极市导读
本文参考了两篇综述与大量的论文,总结了从盲图超分辨率到真实世界图像超分辨率的相关背景以及方法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
底层视觉的发展是否能够让我们真正地看清这个世界呢?
本文参考了两篇综述与大量的论文,总结了从盲图超分辨率到真实世界图像超分辨率的相关背景以及方法。全文共1.8w字,写作时间三个月。
在单图超分中,非盲超分已经发展得较为成熟了,而盲超分和真实超分仍然有很多问题尚未解决。在我看来,盲超分只是真实超分的一个过渡,由于真实世界中退化多而复杂,现有的方法不可能穷尽所有退化,那么必然会带来一系列问题,因此真实超分的路还很长。这篇文章仅仅作为一个详细的解读,总结一下盲超分与真实超分的各种方法,不仅作为我学习超分的记录,也为大家学习这个领域提供一个参考,欢迎大家交流讨论,提出建议。

盲超分 Blind SR
1 背景概述
1.1 SR目标
的degradation过程是从HR图像 经过degradation过程 得到LR图像 ,即
其中 为scale factor。那么 的目标就是求出degradation的逆过程 。
1.2 non-blind SR
non-blind SR的方法,就是显示建模degradation过程,具体而言先加一个固定的高斯模糊核,再用bicubic下采样,公式如下:
这样的方法只能处理特定degradation,如果迁移到其它degradation就会产生Domain Gap
注:高斯模糊核分为isotropic与anisotropic两种,anisotropic可以看成isotropic加一个motion blur

加不同模糊核的图像,图1为原图,图2为加isotropic kernel,图3为加anisotropic kernel
1.3 blind SR
blind SR的方法就是为了处理这样的domain gap。
blind SR的方法可以分为两大类,一类是显式建模,一类是隐式建模。
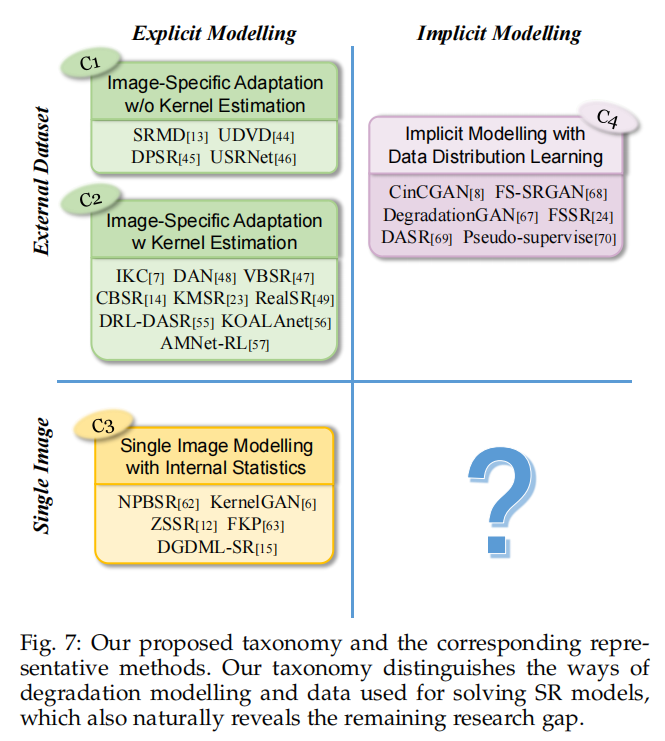
1.3.1 显式建模
显示建模公式如下:
其中模糊核 与噪声 未知,或带有JPEG压缩
一种方法是通过学习带有不同模糊核与噪声的外部数据集从而增加对不同degradation的泛化能力,其中还可以根据是否有Kernel estimation而分成两类;
另一种方法是利用图像内部的patch recurrence,相当于利用了self similarity
1.3.2 隐式建模
隐式建模不用学习显示的参数,而是直接学习HR的分布,用生成模型(一般是GAN)生成HR图像
2 方法概述
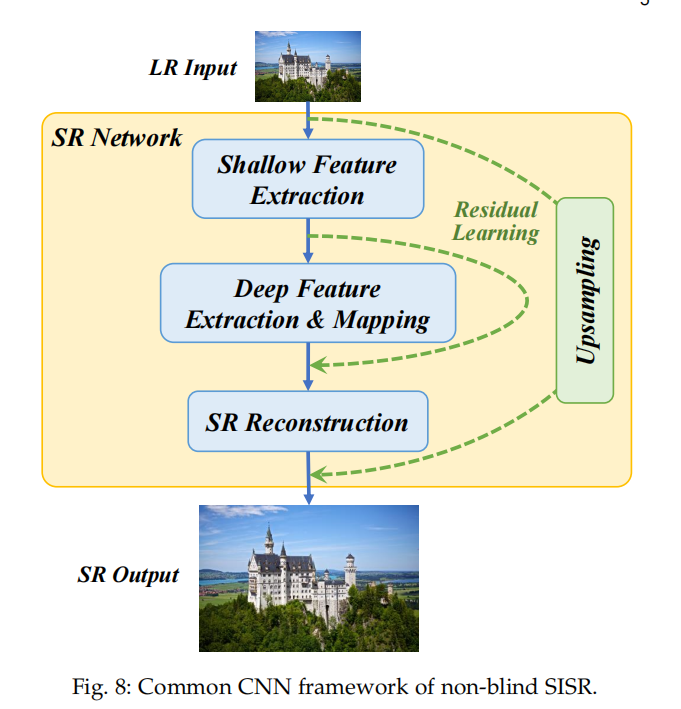
2.1 non-blind SR经典的CNN框架
2.2 显式建模
2.2.1 有外部数据集
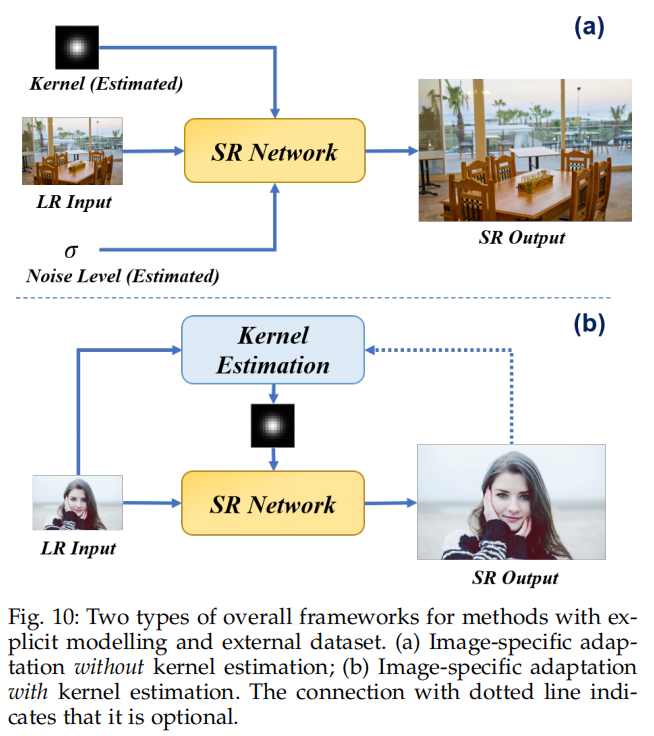
可以分为有Kernel estimation和没有kernel estimation两类
前一类在SR网络之前有kernel estimation,后一类直接将估计好的degradation信息当做输入
2.2.1.1 无kernel estimation
方法一:将degradation map作为输入
用PCA,神经网络等方法将估计核与噪声编码/转为feature map(也就是degradation map),与LR concat之后作为输入送入SR网络,代表方法SRMD,UDVD

方法二:将SR任务转为迭代优化的问题
具体而言,由SR的degradation过程得到优化的目标,将目标解耦为数据项和先验项。
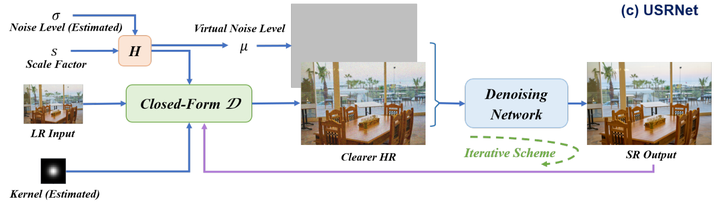
DPSR
例如DPSR中,Degradation为:
即先下采样再加模糊核与噪声
那么相对应的公式为:
其中 为数据项, 为先验项
根据half-quadratic splitting算法可以将原问题分解为两个子问题,一个优化数据项,一个优化先验项。
这里的数据项对应deblurring任务,先验项对应upsampling以及denoising
数据项优化使用Fast Fourier Transform,先验项优化使用一个non-blind SR网络,且noise map作为输入
并且需要迭代优化
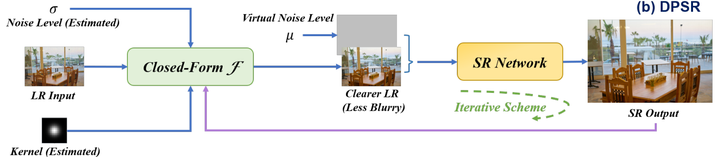
USRNet
详细的解析可以查看我的另一篇文章
https://zhuanlan.zhihu.com/p/649886556
USRNet中,degradation为
即先加模糊核,后下采样与加噪声
因此相应的公式为:
同样分解为两个子问题,数据项对应upsampling与deblurring,先验项对应denoising
同样需要迭代优化
2.2.1.2 有kernel estimation
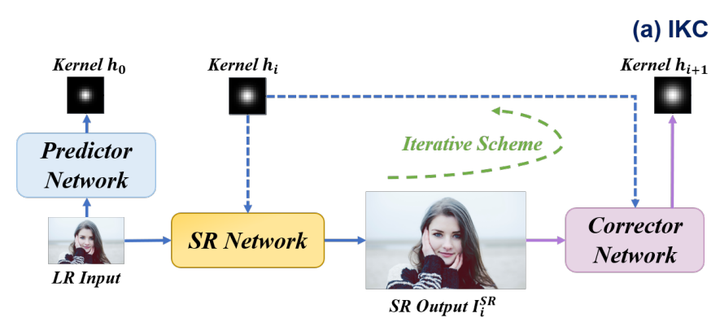
IKC
核心在于利用了迭代中间层的SR结果校正estimated kernel
有kernel estimation的Blind SR就是要得到一个kernel predictor 方法是有监督学习 ( 为 GT kernel)
但是这样的估计可能不准确,作者提出了一个kernel correction的方法
其中 为corrector, 为使用最后一个预测的Kernel得到的 结果,相当于用 结果的 feature去校正预测的blur kernel
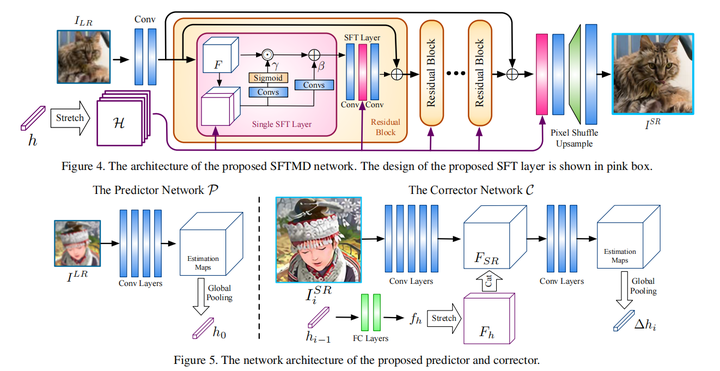
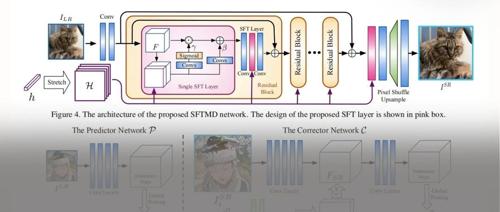
具体网络结构是将predictor得出的estimated kernel,经过变换作为仿射变换(spatial feature transform) 的参数对输入图像的feature map进行仿射变换 (SFT中的结构)
其中 是input得到的feature map, 是estimated kernel maps, 和 是仿射变换scale 和shift参数
而Corrector是将当前步得到的SR结果与上一步的estimated kernel进行融合校正,得到当前步 corrected kernel,输入网络
不断迭代优化得到最终结果
注:predictor只在网络最开始有,而corrector每个迭代步都有
DAN
网络结构如下:
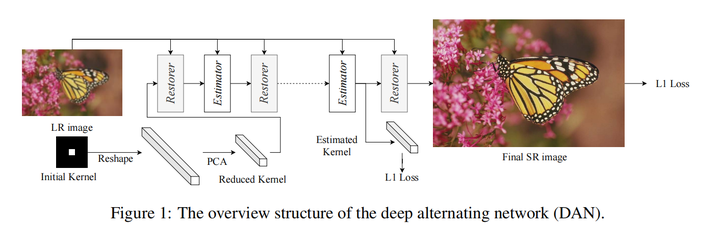
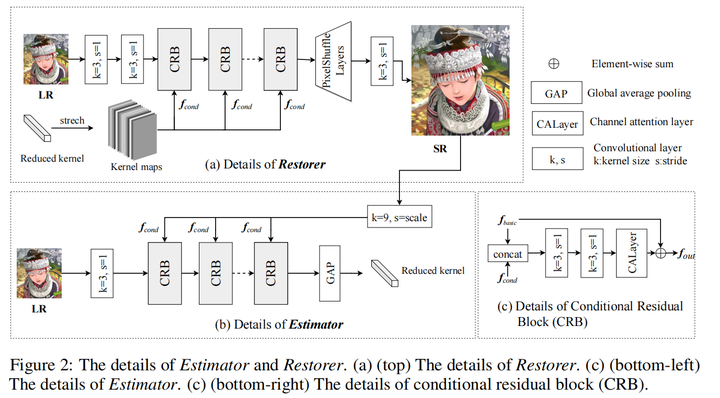
与IKC的不同:
1. 将corrector(estimator)与SR网络(restorer)放在一起,变成一个端到端的网络,而不是像IKC一样分成两个网络训练
2. corrector输入是LR和中间层SR结果,而不是IKC中的kernel与中间层SR结果
3. 对于kernel中degradation信息加入网络的方法,IKC采用将kernel作为input feature map仿射变换的指导;DAN采用的是CA,其实本质上都有点类似加权。
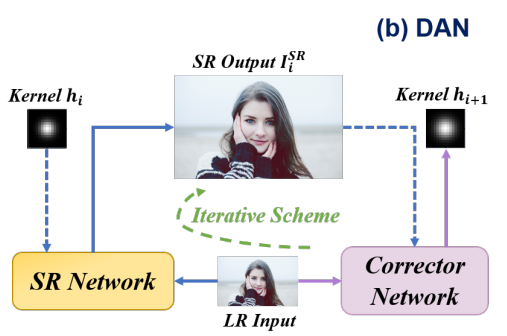
VBSR

与IKC和DAN最大的不同在于kernel discriminator模块预测的是一个kernel error map而不是corrected kernel
Iterative方法的合理性:
从域适应(domain adaptation)的角度,这种方法利用迭代中间SR结果逐步从LR域到HR域,更好地解决了domain gap
Iterative方法的缺点:
inference时间长,并且迭代次数需要人为选择
Non-iterative方法
DASR
核心思想在于利用contrastive learning学习一个Degradation representation
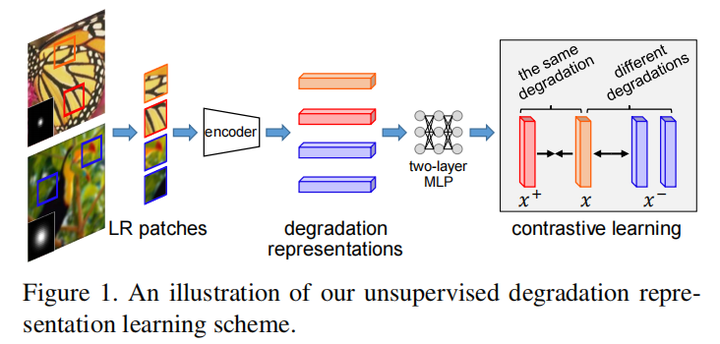
对比学习的方法是,在LR上选一个patch作为query,将相同LR的其它patch作为正样本,其它LR上patch作为负样本,经过MLP后,利用MoCo中提出的InfoNCE loss使得query与正样本距离减少,与负样本距离增加,得到最终的degradation representation
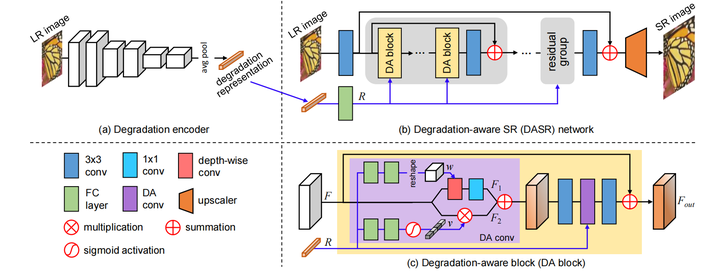
具体的网络,follow了RCAN中的residual group的结构,对于每个res block(这里的DA block)中的DA conv,学习到的degradation representation一个分支生成Depth-wise kernel;另一分支生成modulation coefficients(类似进行了一个channel attention),去调整input channel权重(其实我感觉两个分支都是类似于channel attention)
其余方法(后续会逐步补充更新具体论文方法):
KMSR(ICCV 2019)
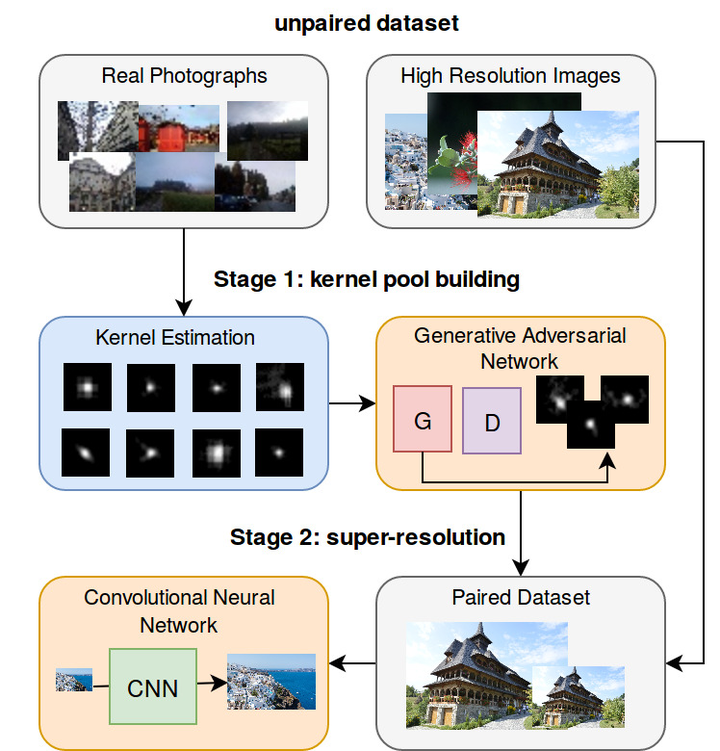
文章主要贡献在于数据生成
使用真实图像估计模糊核,接着用GAN根据估计的真实模糊核扩充模糊核,然后使用模糊核根据HR生成LR数据集
估计方法是暗通道先验,可参考论文Blind Image Deblurring Using Dark Channel Prior(CVPR 16)
https//openaccess.thecvf.com/content_cvpr_2016/papers/Pan_Blind_Image_Deblurring_CVPR_2016_paper.pdf
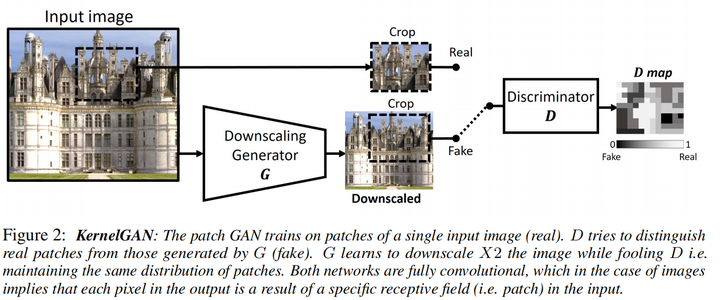
KernelGAN(NIPS 2019)
https//arxiv.org/pdf/1909.06581.pdf
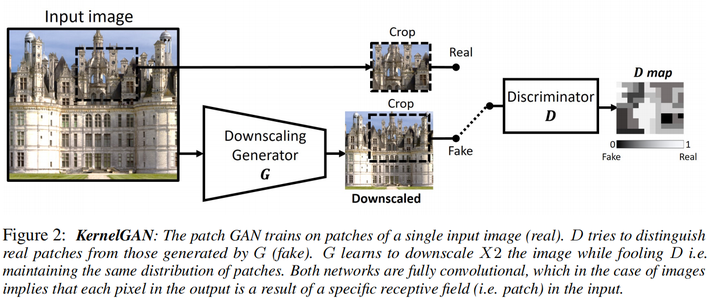
GAN可以被用来作为distribution matching的工具,这篇文章要匹配的分布是真实图像加模糊核降采样后的分布与原图分布,且不是用整张图,而是patch
输入测试集LR图像,生成器预测降采样的LR,使得判别器无法分辨生成图像与原图的patch distribution,这样生成器就学习到了一个能够保存原图patch distribution的降采样操作与相应的模糊核
注意KernelGAN是一个image-specific GAN(或者称为internal GAN),只需要单张测试图像即可
RealSR( CVPR Workshop 2020 )
https//openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ji_Real-World_Super-Resolution_via_Kernel_Estimation_and_Noise_Injection_CVPRW_2020_paper.pdf
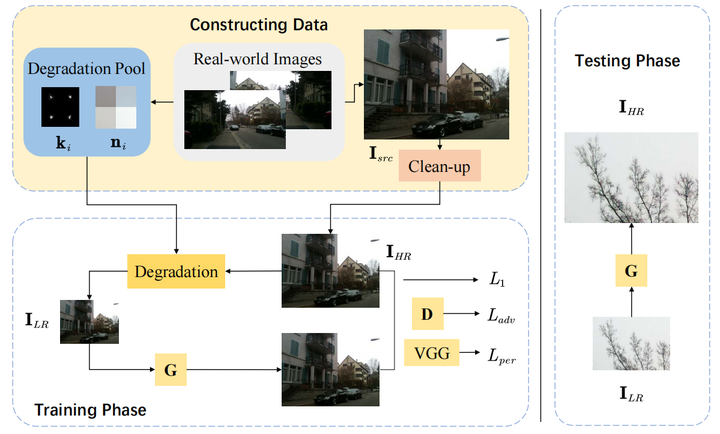
与KMSR类似,主要贡献在于真实模糊核的生成部分。
首先根据真实图像生成Degradation pool,根据公式:
与KMSR类似,主要贡献在于真实模糊核的生成部分。
首先根据真实图像生成Degradation pool,根据公式:
是用kernel k下采样的LR图像, 是用目标kernel下采样的LR图像,第一项的目的是最小化 ,第二、三项是对 的限制,最后一项是让判别器判别的生成 图为真的概率尽可能接近1
Clean up
将真实图像bicubic下采样得到HR图像,这样可以去除噪声,得到干净的HR图像
Degradation with Blur Kernels
在Degradation pool中随机选择kernel生成LR图像
Noise Injection
降采样的过程中高频信息损失,noise distribution也会发生变化。因此在真实图像中采集noise patch,由于有rich content的图像Noise一般更多,而且很难将noise和有用信息分离,因此选择 patch的时候选择图像内容不丰富的patch,判断方法是方差,即选择方差在一定范围内的图像,满足
SR Model
使用的超分模型是ESRGAN(ECCV 2018)的模型,生成器是RCAN
损失函数
RealSRGAN(CVPR Workshop 2020)
https//openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ren_Real-World_Super-Resolution_Using_Generative_Adversarial_Networks_CVPRW_2020_paper.pdf
思路:先合成数据集,然后训练多个GAN,最后设计一个集成方法将多个GAN的结果集成
1.数据集合成
两种数据集,一种是LR未知的;另一种是知道LR是由相机拍摄的
LR未知(Synthetic dataset generation for robust real-world SR )
根据公式:
下采样方法: nearest neighbor, bilinear, bicubic, Lanczos四种方法随机
模糊核:各项同性的高斯模糊核,方差在0.2-3之间随机
噪声: 高斯-泊松噪声,公式如下:
LR已知(Synthetic dataset generation for mobile real-world SR )
直接使用DSLR Photo Enhancement Dataset (DPED) ,将DSLR的图像上采样作为HR,Mobile 图像作为LR
2.训练GAN
两种GAN,一种是ESRGAN中的Relativistic GAN,另一种就是SRGAN中普通GAN
第一种GAN
使用ESRGAN的架构,生成器是RCAN
损失函数:
是 与 的feature map在过预训练VGG 19后的距离,即
这里的对抗损失是ESRGAN提出的基于relativistic GAN discriminator的对抗损失
relativistic discriminator与standard discriminator的区别如下图:

即standard discriminator是判断生成器生成图像是real还是fake;而relativistic discriminator判断的是生成器生成图像是比fake更真还是比real更假,有一个相对的比较
第二种GAN
区别在于对抗损失是基于standard GAN的
3.融合GAN
作者发现relativistic GAN生成的图像在高频区域的感知质量很好;standard GAN在一些暗光平滑区域伪影更少,因此作者提出了一个思路,在暗光区域将二者融合,在其它区域使用relativistic GAN,公式如下:
是relativistic GAN生成的HR图像YCbCrt域光强Y的中位数
D这一类方法也可以归类为数据生成的方法

Correction Filter for Single Image Super-Resolution: Robustifying Off-the-Shelf Deep Super-Resolvers(CVPR 2020)
ICCV 2023有一篇在这个工作基础上继续做的文章,可以参考我的解读
https://zhuanlan.zhihu.com/p/660917542
KOALAnet(CVPR 2021)
待补充
AMNet(CVPR 2021)
改进了AdaIN并提出了另一个感知指标NIQE
局限性
需要kernel estimation的方法的局限性:不能应用在训练集没有覆盖到的kernel类型上
2.2.2 没有外部数据集
方法是 Single Image Modelling with Internal Statistics
具体而言,一张图像的patch会在相同或不同尺度重复出现(patch recurrence),可以理解为图像的自相似性
KernelGAN
之前已经阐述过,kernelGAN是要把patch recurrence问题解释为data distribution learning的问题,即LR降采样的图像和原先的LR具有相似的patch distribution,匹配这样的patch distribution就可以学习到kernel。
由于只使用LR图像,因此可以看成一个self-supervised的方法
基于Flow的方法
FKP(CVPR 2021)
待补充
https//browse.arxiv.org/pdf/2103.15977.pdf
ZSSR(CVPR 2018)
https//browse.arxiv.org/pdf/1712.06087.pdf
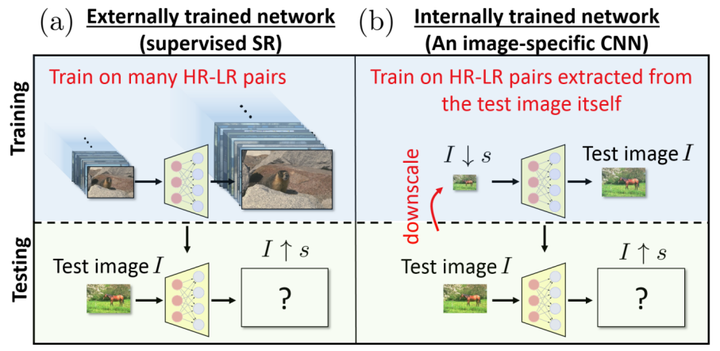
思路很简单,就是将test image作为HR,test image下采样后作为LR,进行self-supervised learning
优化的方法是在LR上加noise
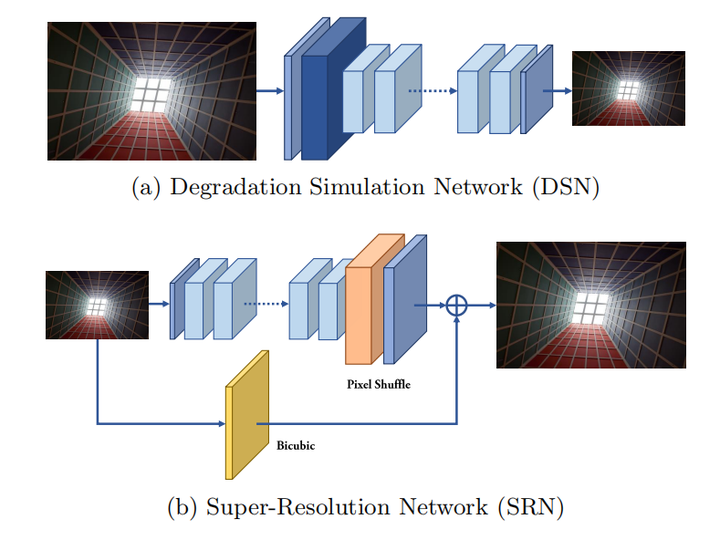
DGDML-SR(ECCV 2020)
depth-guided self-similarity prior:相似的patch,离镜头近的更清晰,离镜头远的更模糊

Depth Guided Training Data Generation
离镜头远的patch作为 ,近的作为
patch䇤选:选择对比度高的能保留更多信息的patch,具体而言,将图像转换为YCbCrt或,根据对比度公式:
,设定阈值,去掉对比度低的patch
depth计算:根据计算好的depth map,计算全局平均深度
设定平均深度低于全局平均深度的patch为 ,反之为
Bi-cycle training
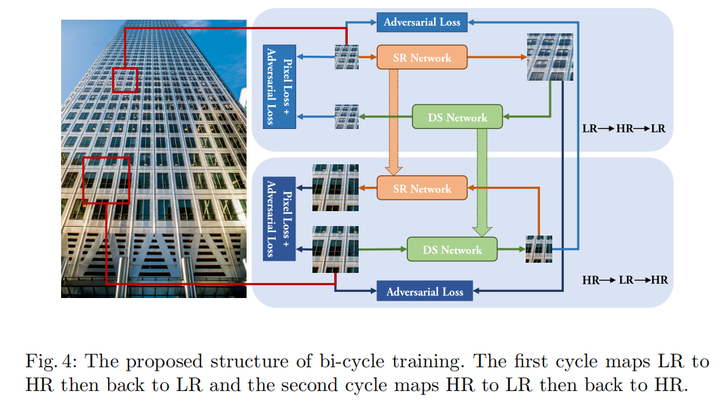
没有直接使用LR,HR对去作监督训练,原因是没有对齐
使用类似CycleGAN的训练策略,一共四个网络,Degradation Simulation Network(DSN)用于将HR变为LR,学习degradation;Super-resolution Network(SRN)就是普通的超分网络;两个discriminator用于distribution matching
整个训练流程如图,一方面,real LR经过SRN变为fake HR,和real HR计算adversial loss,接着经过DSN又变回LR,和原先的real LR计算pixel loss和adversial loss;另一方面,real HR经过DSN变为fake LR,和real LR计算adversial loss,接着经过SRN又变回HR,和原先的real HR计算pixel loss和adversial loss
局限性
上述利用内部数据的self-supervised方法的局限性是不是所有图像都是具有跨尺度的recurring information的
2.3 隐式建模
主要是GAN的方法
CinCGAN(CVPR Workshop 2018)
https//browse.arxiv.org/pdf/1809.00437v1.pdf
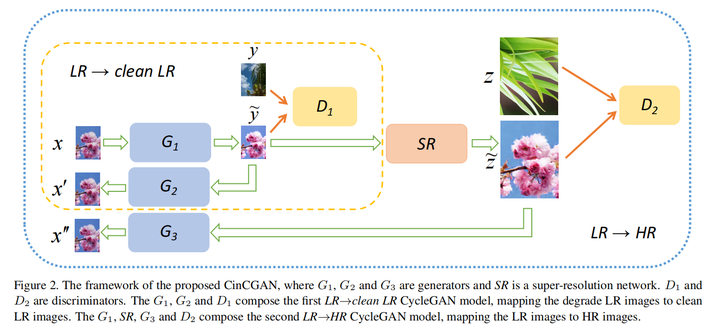
主要思路是先将LR变成clean LR(或者称为bicubic LR),和clean sample输入Discriminator,同时利用逆变换回到LR,和原来LR比较;第二部是将clean LR经过SR网络(这里用的是EDSR)变成HR,和HR sample输入Discriminator,同时利用逆变换回到LR,和原来LR比较,损失函数具体见论文。
实质上是将整个SR分解为denoising和SR两部分。这样的训练过程不需要HR图像,所以可以算是unsupervised方法,缺点是无监督方法的domain adaptation很难,因为一个简单的discriminator无法很有效地进行domain separation
degradation GAN(ECCV 2018)
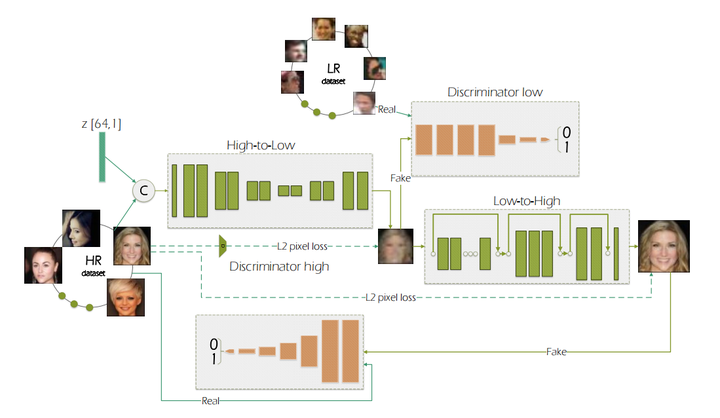
流程很容易理解,real LR经过SR网络变成fake HR,和real HR计算pixel loss,和其它HR计算adversial loss;real HR经过一个类似degradation网络变成fake LR,和real HR下采样后的结果计算计算pixel loss,和其它LR计算adversial loss
与CinCGAN的最大区别
CinCGAN是无监督方法,只是使用了sample作为domain adapatation的一个参考,不能算是ground truth;degradation GAN是有监督方法,有明确的HR
与DGDML-SR的异同
相同点:都有LR到HR和HR到LR的步骤;adversial loss的计算相同,都是LR变成HR,HR变成LR之后与原先的real HR/LR计算
不同点:
DGDML-SR是自监督的,而degradation GAN是有监督的;
DGDML-SR在real LR变成fake HR,real HR变成fake LR之后分别还有一个逆过程,这样组成了两个小循环;
pixel loss的计算不同,DGDML-SR是LR变成HR再变成LR之后(HR类似)与自身的计算,而degradation GAN是与adversial loss类似的计算方法
FSSR(ICCV Workshop 2019)
2019 AIM Challenge on Real World SR Winner
https//arxiv.org/pdf/1911.07850.pdf
合成数据最简单的方法是bicubic下采样,但这样得到的LR图像会损失高频信息(也可以理解为域发生变化),因此需要用一个GAN从LR生成一个既不改变LR低频信息(如颜色、内容等),又保留HR高频信息的图像,即从频域的角度进行domain adaptation。直接加损失函数需要在低频和高频信息上做一个trade-off,这样不利于恢复,因此需要进行频域分离
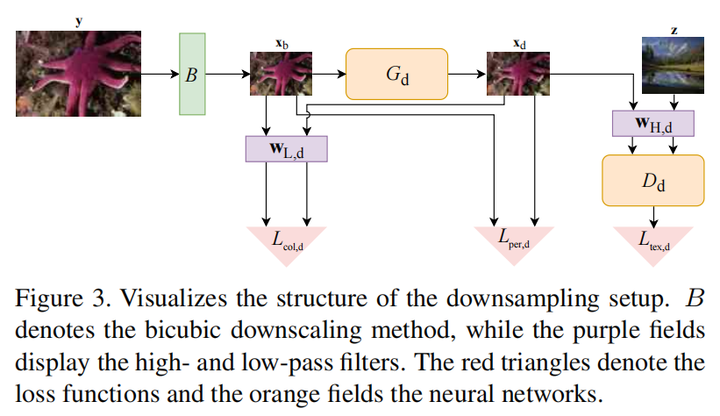
那么进一步, 和 是低频和高频的滤波器,生成的具有正确域的 图像和原 图像经过低频滤波之后计算颜色损失,这样保证LR低频信息仍然保留;两个图像也要计算感知损失,直接使用LPIPS。
同时,生成的LR和HR域的sample z要过discriminator之后计算adversial loss,这样可以更好地保留HR的高频信息,公式如下 (分别是generator和discriminator的损失):
这个方法可以直接应用到ESRGAN上,如下:
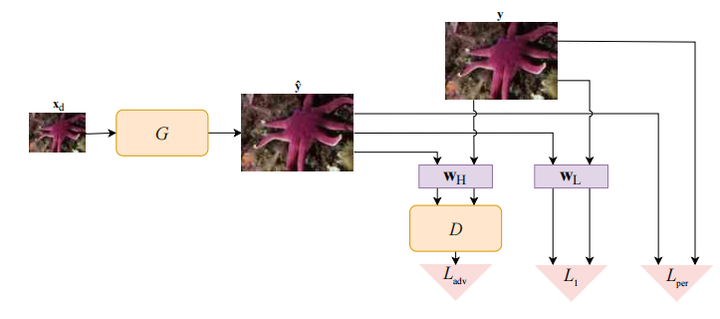
不过这里直接将生成器生成的HR与real HR进行高频、低频的比较,可以理解为生成的HR需要保留目标HR的高频与低频信息,从而更好地完成domain adaptation
FS-SRGAN(CVPR Workshop 2020)
待补充
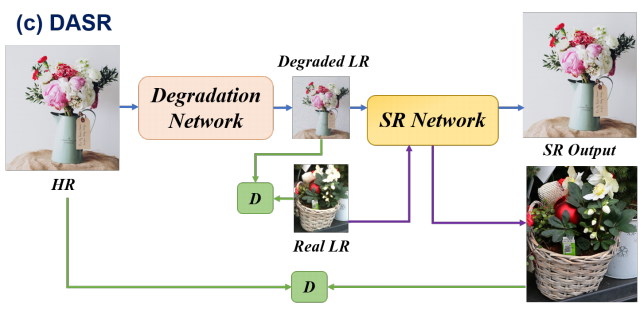
DASR(CVPR 2021)
注:这里的DASR不是上面Non-iterative方法中的DASR,是Unsupervised Real-world Image Super Resolution via Domain-distance Aware Training
https://zhuanlan.zhihu.com/p/662148885
真实超分 Real-World SR
1 背景概述
与Blind SR的区别在于,Real-World SR数据集的模糊核是真实场景中更加复杂多变的,受到一系列因素的影响,比如成像系统(传感器),还有成像环境等等。那么模拟degradation过程从而合成的图像和真实图像的domain gap只会更大。这也是Real-World SR最大的难点与痛点。
2 Real-World SISR(RSISR)数据集
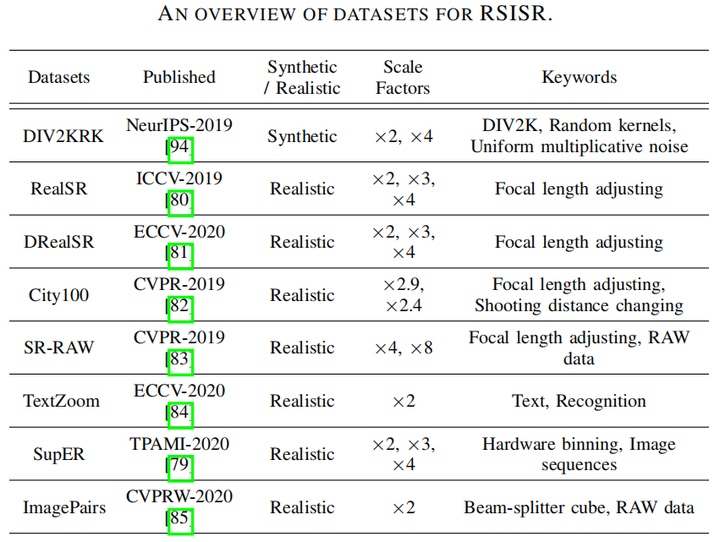
DIV2KRK
由DIV2K验证集的HR加随机高斯模糊核与噪声得到,仍然是合成数据集而非真实数据集,因此该数据集定位是blind SR dataset
RealSR & DRealSR
相同的收集方法,都是用不同焦距的DSLR拍摄真实图像,最长焦的作为HR,其余作为相应倍率的LR,并采用一些后处理方法解决变焦带来的镜头畸变与曝光
City100
同时采用变焦和改变拍摄距离的方法获取图像,并且使用DSLR和Smartphone进行拍摄
SR-Raw
变焦拍摄,且有Raw域与RGB两种成对图像
其余数据集感兴趣可阅读相关资料。
3 评价指标
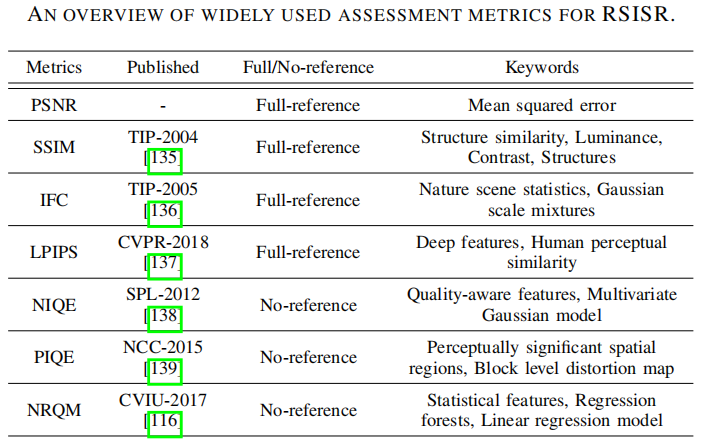
这里不详细介绍。
4 方法概述
大致的方法可以分为三种:degradation modeling-based methods, image pairs-based methods, domain translation-based methods和 self-learning-based methods,如图所示
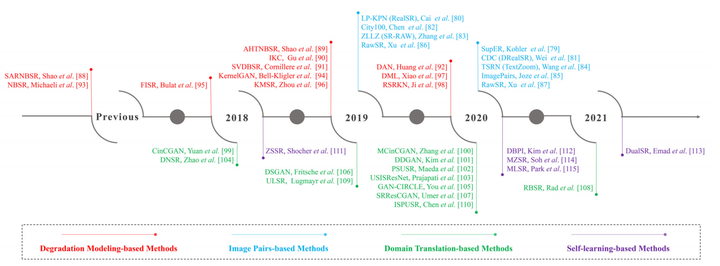
RSISR的历程与分类
注:之前在Blind SR中详细解释过的方法,这里不过多阐述。
4.1 degradation modeling-based methods
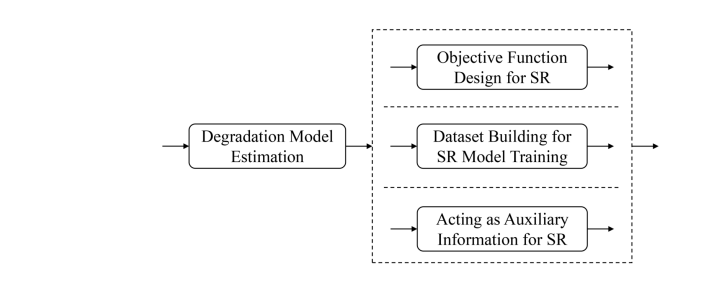
其实和之前Blind SR里有外部数据集中的有/无degradation estimation是类似的
较为早期的方法建立目标函数进行优化( numerical optimization-based approaches);
之后的iterative的方法用网络同时迭代优化blur kernel和SR image,例如之前提到的IKC,DAN;
后续USRNet将优化Blur kernel和SR image的网络合起来变成一个end-to-end的网络;
有一些隐式建模的方法不需要外部数据集,
KernelGAN 学习了patch的内部分布,且只用测试集LR训练;
DegradationGAN通过非配对人脸数据进行学习,生成成对数据用于训练SR网络;
KMSR 使用真实图像估计模糊核,接着用GAN根据估计的真实模糊核扩充模糊核,然后使用模糊核根据HR生成LR数据集
RealSR具体解析见Blind SR部分。
4.2 Image Pairs-based Methods
这一块主要方法是收集成对真实图像数据,具体的物理收集方法不详细展开。
那么获得成对真实数据之后,使用普通的非盲超分网络直接训练仍然是存在问题的。因为真实场景不同位置的退化可能是不同的,对所有图像的所有像素使用同一种超分方法是有问题的。
LP-KPN(ICCV 2019)
https//arxiv.org/pdf/1904.00523.pdf
该论文主要贡献在于提出了Real-World SR数据集RealSR。
其网络部分主要Motivation在于:
-
同一个图像不同区域,blur kernel不同 -
不同焦距会导致不同景深(Depth of Field, DoF)。这里论文没有详细解释,我理解的景深与degradation或者blur kernel的关系是,景深不同其实会导致不同图像相同区域的blur kernel强度不同,景深越小,则blur kernel强度越大。
基于上面的两点,作者对于每个pixel都预测了一个kernel。
另外一个创新点在于作者采用了多尺度金字塔结构,这样可以显著降低计算量。
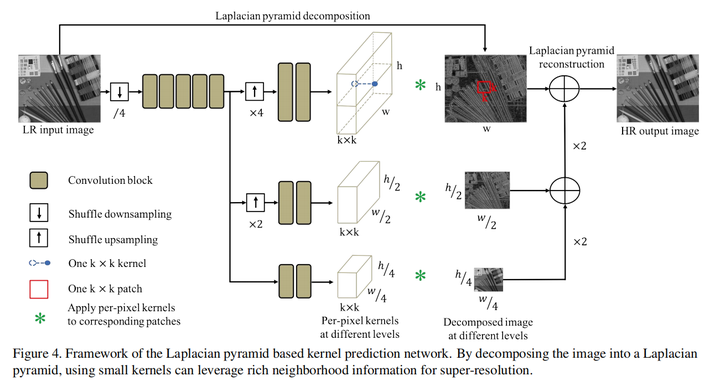
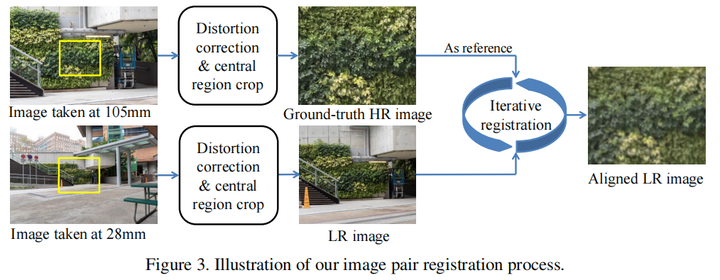
另外一个问题是数据集的misalignment问题,即使在收集数据集的时候已经采用了registration的方法,仍然会有该问题出现。
Zoom to Learn, Learn to Zoom(CVPR 2019)
https//openaccess.thecvf.com/content_CVPR_2019/papers/Zhang_Zoom_to_Learn_Learn_to_Zoom_CVPR_2019_paper.pdf
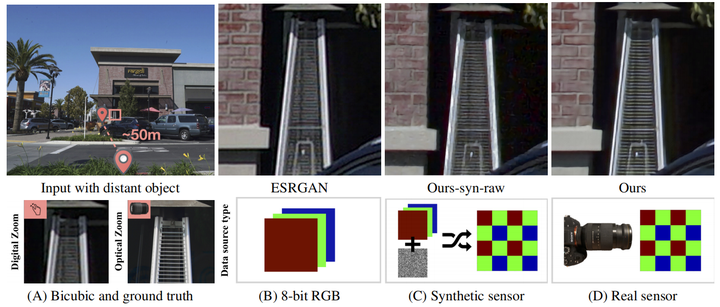
理解这篇论文需要的先验知识是Zoom的具体含义与方法:
Zoom指变焦,在手机上对拍摄后的图像变焦的意义是,在不改变拍摄位置的情况下,调增拍摄的视角和画面的大小。论文里主要探讨的变焦有光学变焦(optical zoom)和数码变焦(digital zoom)。
光学变焦是改变变焦镜片的位置从而实现的,这种方法肯定是最好的,但是相应的需要多块镜片,成本较高;而数码变焦则是采用算法,例如超分实现的,成本较低但会引入模糊等。
论文的一个贡献是,提出数码变焦在高bit位的真实传感器raw图上比8bit的RGB图和合成传感器raw图好,因此提出了一个Raw超分数据集SR-Raw,收集方法是使用不同焦距并处理了misalignment情况。

可能造成的不对齐的情况有:不同视角带来的明显的不对齐、景深不同带来的不对齐、分辨率不同导致sharp edges和blur edges的不对齐。
另一个重要贡献是提出了一个损失函数contextual bilateral loss (CoBi) ,专门用于处理轻微不对齐图像。
首先,对于不对齐的图像, loss都存在问题,而考虑contextual loss(CX),公式如下:
这个损失的含义就是:对于每个特征点P,找到与其最接近 (最相似) 的特征点Q,计算这个损失。
然而论文认为,类似于bilateral filters的思想,不仅要考虑特征点之间的相似度,还有考虑其距离,因此提出了 contextual bilateral loss (CoBi),公式如下:
其中, and
是spatial awareness,可以理解为对不对齐程度灵活加权。增大则意味着更加考虑不对齐情况,反之则少考虑不对齐情况。
最后采用了RGB域加上VGG特征作为特征空间计算损失
可视化结果可以发现加上CoBi后效果较为明显。

CDC(ECCV 2020)
https//arxiv.org/pdf/2008.01928.pdf
贡献1:提出了一个大规模的真实超分数据集Diverse Real-world image Super-Resolution dataset(DRealSR)
该数据集不进行详细阐述。
贡献2:提出了一个Component Divide-and-Conquer model(CDC)和Gradient-Weighted loss(GW)
Motivatition
根据梯度变化,图像内容可以被分解为三种:平坦区域、边缘、角点。
在 任务中,不同区域处理目标不同,具体而言,平坦区域需要保持平滑,边缘要锐化,角点的纹理细节要增强。并且这三种区域的处理难度不同,平坦区域较为简单,而边缘与纹理较为困难,但普通的 loss对这些区域同等关注,因此作者认为需要对困难的部分关注更多,也就是加权。
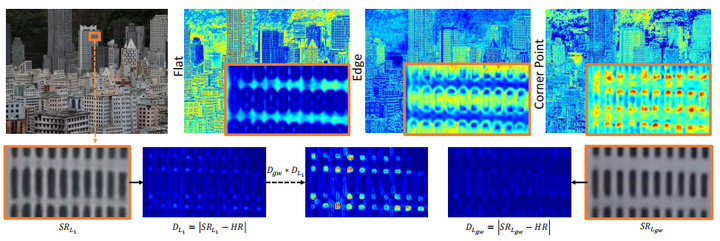
这张图片的第二行的 和 分别是 loss 的结果,蓝色的是loss map,可以发现 lossi练的loss map,平坦区域、边缘、角点三个部分的loss逐渐增大,而 lossi川练的结果则在一定程度上减少了这种情况。第一行是CDC学到的三个不同区域的注意力掩码,可以很好地表示三个区域的置信度。
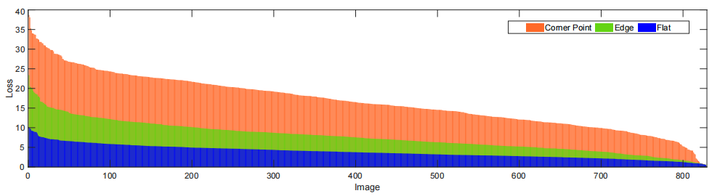
这张图是EDSR在 loss 下三种不同成分的损失,根据损失可以很清楚地比较不同区域的重建难度。
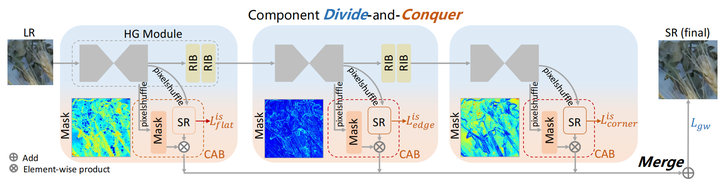
Component Divide-and-Conquer(CDC)
算法分为了三块:
Divide:按照之前的分析,分别学习三个部分。但不直接从LR图像中检测三个部分,而是学习component attentive masks,因为LR图像做角点检测有问题。
Conquer:三个Component-Attentive Blocks产生不同区域的掩码和中间SR结果。
Merge:用三个mask加权聚合三个中间SR结果,并加上GW loss从而对不同部分学习困难程度进行加权

mask和中间SR结果都由pixelshuffle得到,然后二者相乘,组成了CAB模块, 是从 HR中提取的component guidance mask,用与计算中间损失
损失函数
使用了CDC模型之后,损失函数如下:
其中左边一项代表重建损失,这里是GW损失:
其中,
是 和HR在水平和垂直方向的梯度差异, 用于加权, 就是普通的 损失;也就是梯度差异越大的地方,点乘结果的值就越大,在loss中的贡献就越多,符合困难的角点应该更加关注,而相对简单的平坦区域和边缘关注应较少一点这样的思路,从而使得模型适应不同区域重建难度。
右边一项是三个中间 结果的损失
是从 HR中提取的component guidance mask
总结:这篇文章总体的思路其实比较清晰,创新点也足够,在当时是一篇较好的文章。
Towards Real Scene Super-Resolution with Raw Images(CVPR 2019)
https//openaccess.thecvf.com/content_CVPR_2019/papers/Xu_Towards_Real_Scene_Super-Resolution_With_Raw_Images_CVPR_2019_paper.pdf)
这是一篇raw域超分的文章。
Motivation
首先,文章指出现有的方法在合成真实训练数据方面存在不足。
-
LR是通过固定的downsampling kernel(e.g. bicubic)和同态Gaussian noise生成的,但这种方法无法模拟实际摄影中变化的kernel和异态Gaussian noise。在实际摄影中,模糊核可能会因为变焦、对焦和相机抖动而变化,而图像噪声通常遵循其方差与像素强度相关的异态高斯分布,与同态Gaussian noise有显著区别。 -
blur kernel和noise应该应用于线性raw数据,而不是预处理后的非线性彩色图像。
为解决这些问题,文章提出了一种在线性空间中合成训练数据的方法,通过模拟camera的成像过程,并应用不同的kernel和异态Gaussian noise来近似真实场景。
其次,大多数SR算法只使用彩色图像作为输入,没有充分利用raw图信息。raw图有如下优势:
-
raw图通常是12或14位的,比ISP处理后的8位彩色图包含更多信息; -
ISP包含非线性操作,如tone mapping,使得degradation在处理后的RGB空间中变为非线性,增加了图像恢复的难度; -
ISP中的去马赛克与SR很相似,用RGB图像解决SR问题比用Raw图同时解决这两个问题的统一模型效果更差。
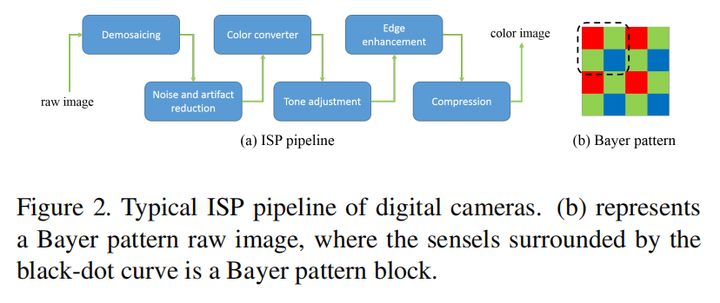
合成图像的具体公式为:
其中 是经过模拟linear color measurements得到的图像,由于拍摄图像会有离焦效应和相机抖动,因此加一个disk kernel ,还有motion blur ,接着下采样,并经过Bayer sampling,最后加噪声
Network
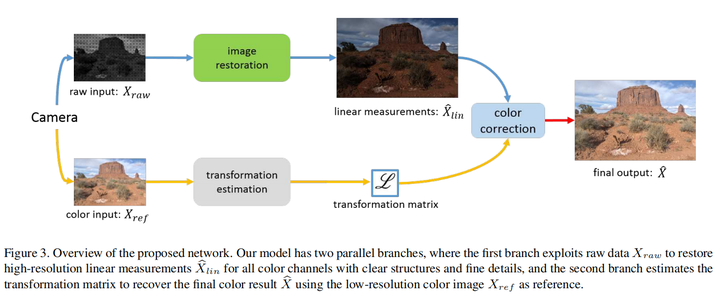
网络结构大致思路其实很好理解,两条分支,上一条用与从raw图中提取结构纹理等信息,下面一条用于从RGB参考图中提取color tranformation用于color correction。
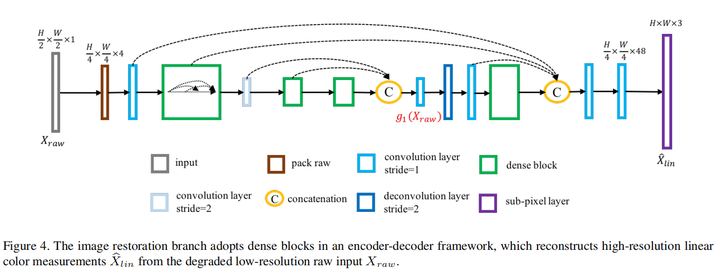
restoration分支的具体结构如下:
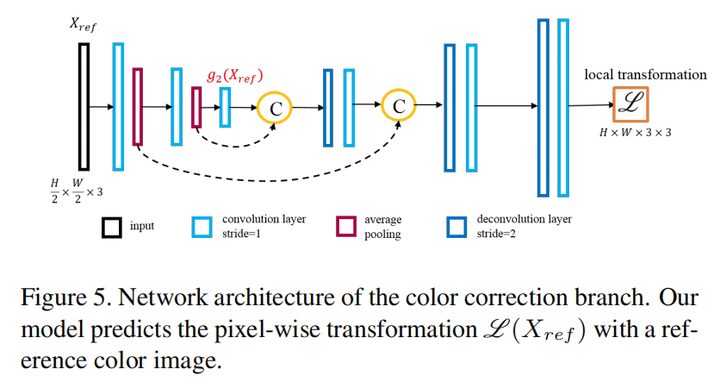
color correction分支的具体结构如下:
4.3 Domain Translation-based Methods
这一块的出发点是,实际情况很难有成对的LR-HR数据集,通常只有LR图像用于训练;或者有一些HR数据集用于参考,但是不与LR图像一一配对。没有一一配对带来最大的影响就是Pixel loss无法计算。
那么domain translation是一个比较好的解决方案。具体而言,真实LR图像(real LR)、合成LR图像(synthetic LR) 、HR图像处于不同的域。domain translation的目标就是学习一个真实LR域到HR域的迁移方法。
最intuitive的方法是:直接用一个生成器将LR生成为HR,用Discriminator将生成的HR域迁移到真实HR。这种方法的最大缺点就是没有paired data带来的,即没有pixel loss,这种约束的缺失会在很大程度上影响模型性能;并且直接学习难度较大。
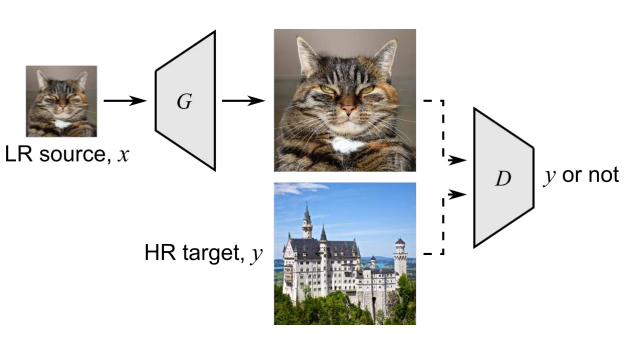
那么对于这种直接方法,有很多改进,总体有两种迁移方法,one-stage和two-stage,最大的区别在于是否利用合成LR作为中转。
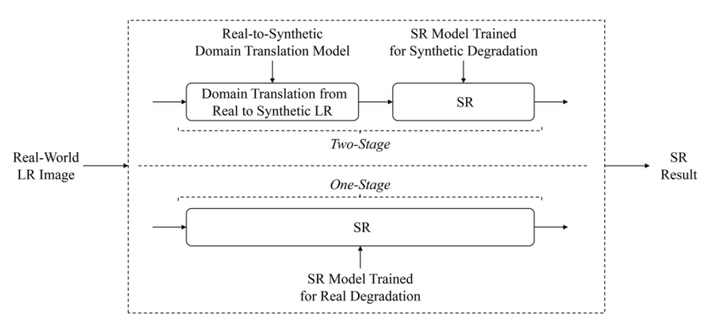
4.3.1 one-stage
one-stage就是直接学习真实LR到HR的映射,不使用合成LR作为中转。
USISResNet(CVPR Workshop 2020)
https//openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Prajapati_Unsupervised_Single_Image_Super-Resolution_Network_USISResNet_for_Real-World_Data_Using_CVPRW_2020_paper.pdf
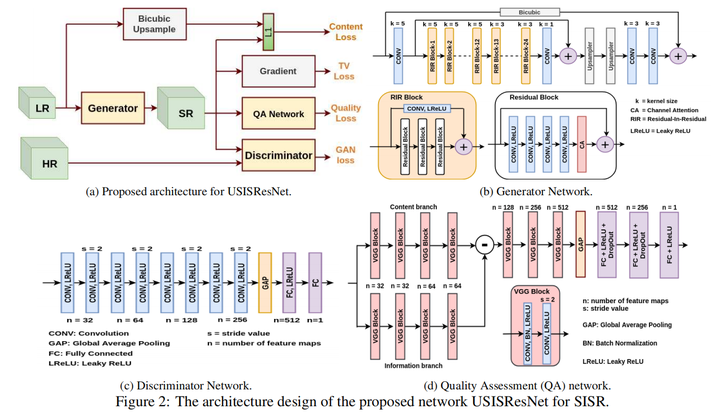
在上文intuitive方法的基础上(经过discriminator的GAN loss),首先LR经过bicubic upsample和SR进行content loss,保证内容的一致性,这点blind SR中论文DASR中也有
Quality Loss
引入了一个基于Mean Opinion Score(MOS)的损失,用于降噪并提高感知质量。具体而言,用一个图像质量评估数据集KADID-10K的噪声数据(带有不同的MOS值)训练了一个网络Quality Assessment (QA) network,输入是SR图像。网络主要由content和information两个分支构成,每个分支由VGG block构成。具体来说,信息分支捕获原始图像中的高频细节(包括噪声),而内容分支捕获的是图像的基本内容和结构信息。信息分支减去内容分支后,网络可以得到一个表示噪声和细节的特征图。最后输出的是这个特征图的MOS,输出值越高,意味着图像质量越好,那么损失也就越小。损失为:
注:Mean Opinion Score (MOS) 主要用于衡量用户对于图像的主观满意度。MOS 值通常通过让一群测试者对特定图像进行评分来获得,然后计算这些评分的平均值。MOS 的评分范围一般是从1到5,从非常差到非常好。
Total variation (TV) loss
主要用于去除噪声伪影,让图像更加平滑。具体定义是所有相邻像素的差值的和,实质上是图像在水平和垂直方向上的梯度,梯度大代表局部像素值变化大,也就是可能存在噪声伪影。具体公式如下:
4.3.2 Two-stage
two-stage方法的提出,一方面是由于直接学习真实LR到真实HR过于困难;另一方面是为了解决one-stage无法使用pixel loss的情况,因此two-stage方法添加了一个中转(大多是合成LR)。
与背景概述中所说的类似,普通的SISR方法用的合成数据和真实数据之间有较大的domain gap,那么减小这个domain gap,也就是让合成数据更加接近真实数据的分布,则是two-stage方法的目标。Two-stage指的两部分别是domain translation和SR。domain translation是让合成LR更接近真实LR的域(分布),而SR则是对合成的LR进行上采样。
大致的方法可以分为两种:
-
第一种是从LR图像出发:从Real LR生成synthetic clean LR,即学习了一个逆退化的correction网络,并加入discriminator,将这个合成clean LR的域迁移到真实clean LR sample的域; -
第二种是从HR图像出发:从HR生成synthetic LR,及经过一个退化,并加入discriminator,将合成LR的域迁移到真实LR sample的域
注意:这里用sample的原因是没有对齐的synthetic clean LR-Real clean LR对或是synthetic LR-Real LR对
CinCGAN
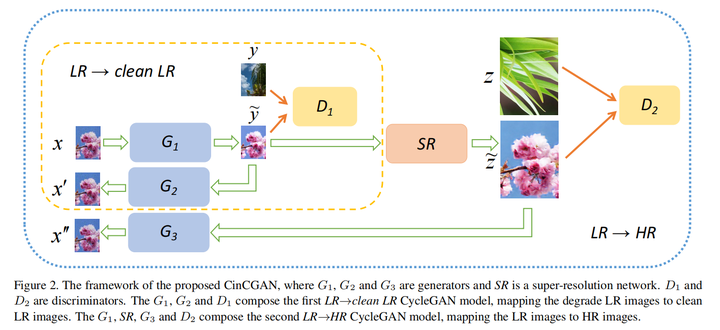
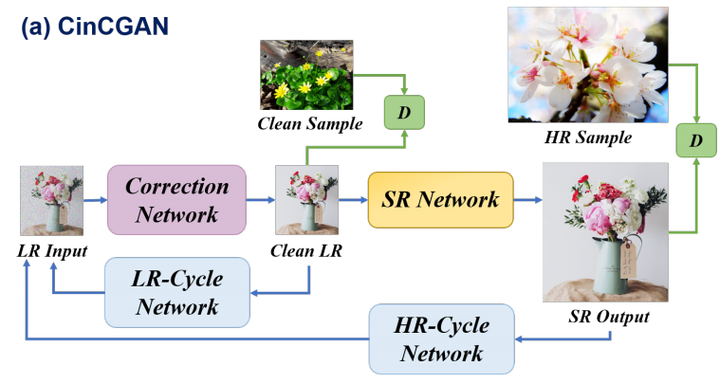
这篇文章在blind SR中已经详细解读过,这篇文章就是上述的第一种方法。
MCinCGAN(TIP 2020)
https//ieeexplore.ieee.org/document/8825849
CinCGAN的后续工作。
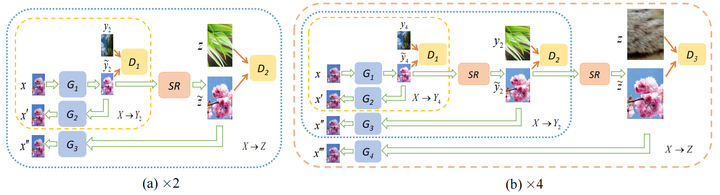
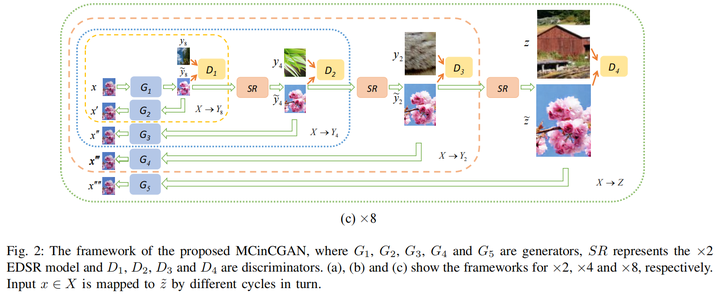
主要引入了a progressive multi-cycle framework,在×2倍率和CinCGAN一致,在×4和×8上面分别多加了一次和两次循环与SR中间结果。另外提出了一个减少颜色波动的loss,具体可见论文。
DDGAN(CVPR Workshop 2020)
https//openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Kim_Unsupervised_Real-World_Super_Resolution_With_Cycle_Generative_Adversarial_Network_and_CVPRW_2020_paper.pdf
待更新
Pseudo-Supervision(CVPR 2020)
https//openaccess.thecvf.com/content_CVPR_2020/papers/Maeda_Unpaired_Image_Super-Resolution_Using_Pseudo-Supervision_CVPR_2020_paper.pdf
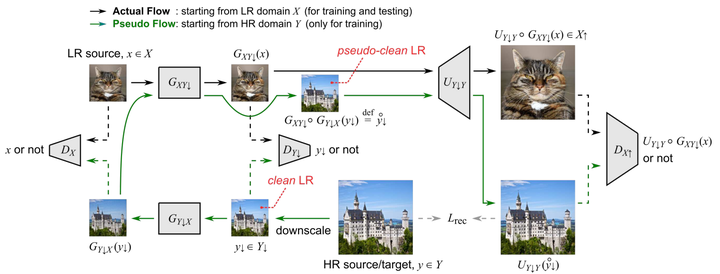
这篇文章和CinCGAN有很多相似之处,都是先进行correction将Real LR生成synthetic clean LR,然后再SR得到HR。不同点有如下(只考虑training的时候):
-
CinCGAN有clean LR sample,而这篇只有HR,其clean LR是由HR下采样(没有退化)得到的 -
同样参考CycleGAN的思路,但CinCGAN是将合成的clean LR逆映射回去;而这篇是将HR得到的clean LR逆变换回去和真实LR进行域迁移。并且得到的逆LR再输入correction网络得到一个pseudo clean-LR。 -
CinCGAN生成的HR与真实HR输入discriminator进行域迁移,而这里篇生成的HR不与真实HR进行域迁移,而是与pseudo clean-LR经过SR网络得到的结果进行域迁移 -
CinCGAN由于真实HR和合成HR不是对齐的,因此不能进行pixel loss,只能用一个逆变换网络将和合成HR还原回LR进行pixel loss;而这篇由于存在一个pseudo clean-LR经过SR网络得到的pseudo HR,与真实HR是对齐的,因此可以计算重建损失
RBSR(WACV 2021)
https//openaccess.thecvf.com/content/WACV2021/papers/Rad_Benefiting_From_Bicubically_Down-Sampled_Images_for_Learning_Real-World_Image_Super-Resolution_WACV_2021_paper.pdf
看到这篇文章突然发现它与ICCV 2023的DARSR的思路有相似性,可见这个思路在现在还在发挥其作用。感兴趣DARSR文章的可以看一下我的解读:
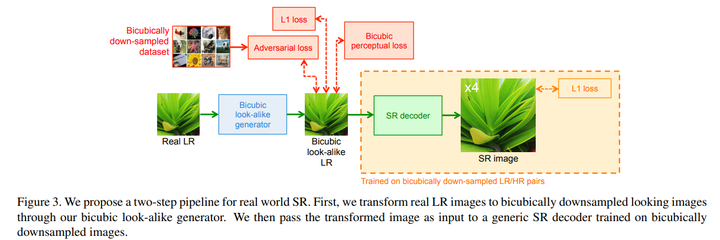
主要思路就是把随机退化的真实LR通过网络迁移到bicubic downsampling得到的LR,方法是与一个bicubically down-sampled dataset中的图像进行domain translation,这样real-SR就转为了一个non-blind SR,可以直接用一个用bicubically downsampled LR-HR图像对训练的网络进行SR。大致思路就是DARSR的思路。
其它几篇方法都有类似的地方,感兴趣可以自行研读:
ULSR(ICCV Workshop 2019)
https//arxiv.org/pdf/1909.09629.pdf
ISPUSR(CVPR Workshop 2020)
https//openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Chen_Unsupervised_Image_Super-Resolution_With_an_Indirect_Supervised_Path_CVPRW_2020_paper.pdf
4.4 Self-Learning-based Method
与blind SR中显示建模中的没有外部数据集方法类似,使用外部数据集的方法大多尝试用数据集中的degradation尽可能覆盖大部分真实场景的degradation,因此性能依赖于training与testing数据的匹配度,那么肯定会存在一个gap,导致testing性能下降,因此self-learning-based method就是解决这样的问题。
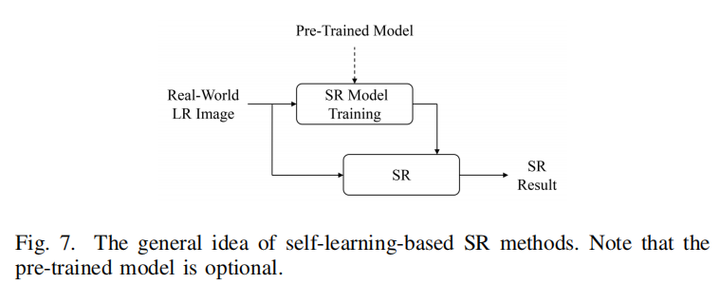
基本方法也就是使用inference的LR图像直接进行自监督学习。
典型文章ZSSR、kernelGAN,见2.2.2节的解读。
DualSR(WACV 2021)
https//openaccess.thecvf.com/content/WACV2021/papers/Emad_DualSR_Zero-Shot_Dual_Learning_for_Real-World_Super-Resolution_WACV_2021_paper.pdf
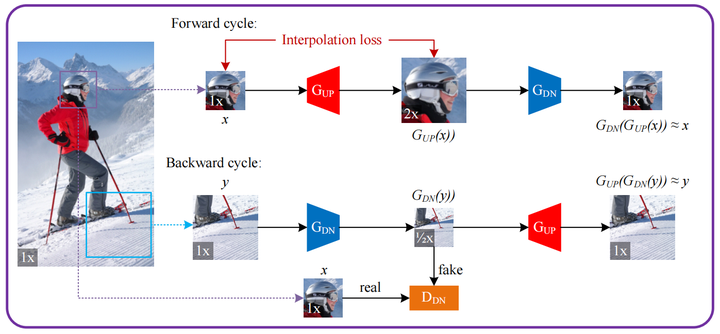
大致思路其实很好理解,就是两个分支Foward cycle和Backward cycle,分别用一张图像上的一个Real LR图和一个Real HR图,训练一个upsampler一个downsampler,Forward cycle从LR出发,先上采样后下采样;Backward则与之相反。LR和Backward cycle分支生成的中间synthetic LR过discriminator。(但奇怪的是HR没有相应地这么做)
提出了一个Interpolation loss:
由于没有直接的监督,在sharp edges附近会有ringing effect(由于高频信息的过度或不均衡处理,可能导致边缘附近出现不自然的波纹);并且低频部分会出现伪影。
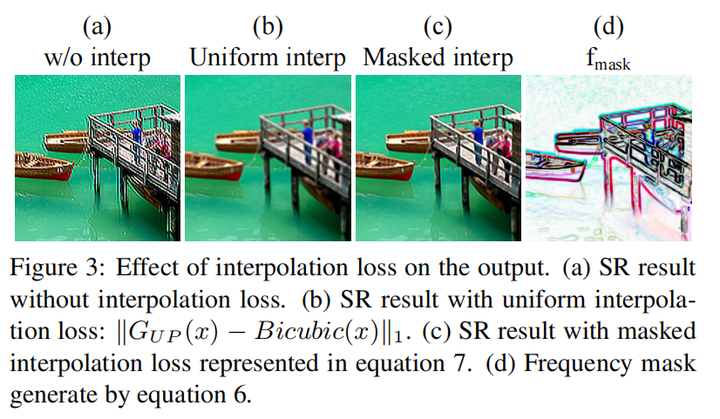
这个loss的motivation是bicubic interpolation可以很好地在上采样的过程中保持低频部分,但是高频部分会有损失,导致图像出现blurring,因此对所有像素加一个Uniform interpolation cost(interpolation cost相当于计算差值前后图像变化)会导致blurring,如图b,那么一个自然的想法就是我只要对低频部分加Interpolation cost就行了。
那么作者就生成了一个mask,公式如下:
对bicubic upsampling的图像经过sobel算子(一个边缘检测的算子,可以看成检测高频信息的作用),那么高频的部分值较高,低频的部分值较低,用1减去,得到的mask,在低频部分值更高,高频部分值较低。
那么最后的损失就是:
这样加权可以更加关注低频部分。
这篇文章在我看来和ICCV 2019 FSSR(在blind SR中有详细解读)思路有异曲同工之处,同是二者都是希望上下采样之后保持bicubic upsampling/downsampling的低频信息,不同点在于FSSR是用滤波的方法将低频高频分开,对低频加颜色损失,对高频经过dicriminator计算GAN loss;而这篇文章是用一个mask相当于加了一个attention,这种方法我认为更加简单高效。总之,在SR中频域方面的处理是一个很重要的问题。
上述的集中方法都有两个共同的问题:第一点是这些方法只考虑了Internal information而完全忽略了external information;另一点是这些方法基本是online training的方法,导致inference时间很长,从实际工业角度出发,这些方法的时延是很难被接受的。因此下面的方法就引入了meta learning对这个问题进行了解决。
MZSR(CVPR 2020)
https//openaccess.thecvf.com/content_CVPR_2020/papers/Soh_Meta-Transfer_Learning_for_Zero-Shot_Super-Resolution_CVPR_2020_paper.pdf
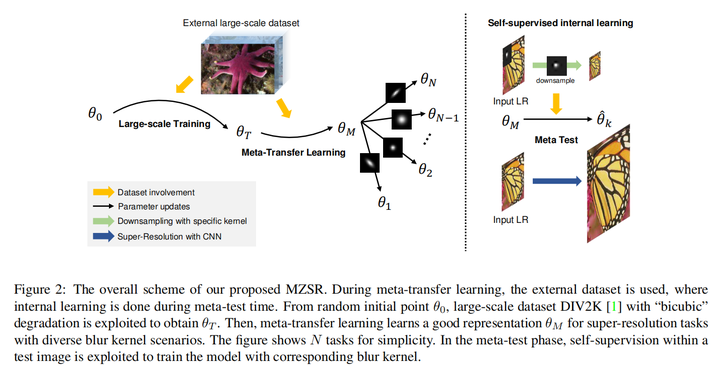
概括而言,在Large-scale Training阶段用DIV2K对模型进行预训练,得到一个初始化的参数;在Meta-Transfer Learning阶段,要让模型找到一个sensitive and transferable的参数空间的点,使得有一点微笑的梯度变化就会带来很大的性能提升。最后在Meta test阶段,就是和之前的算法一样,用internal information进行学习。
由于我对meta-learning了解甚少,具体每部分的解释请参考论文。
另有一篇也是Meta-learning做SR的文章:
MLSR(ECCV 2020)
https//arxiv.org/pdf/2001.02905.pdf
这里暂不做解读,感兴趣可自行阅读论文
后记
那么至此,本文的主体部分就全部结束了,由于本文基本未收录2022年及之后的论文,因此该领域其实还有很多发展、很多方法,同时也有很多未解决的问题,比如在工业生产中,很多真实超分的方法应用起来效果很差,存在涂抹感、油画感等等,这些问题目前都是真实超分领域尚未开垦的荒原。真实超分未来的道路究竟会通向何方?我们是否能够真正地“看清”这个世界,这是在底层视觉,特别是超分领域的大家共同思考的问题。希望未来也会有更多该领域有趣的、有价值的、能够解决实际问题的工作出现。
对于工业界与学术界的gap,具体可参考VALSE 2023的这个workshop中的第一位讲者张磊教授的汇报
https//bilibili.com/video/BV1j94y1y76C/%3Fvd_source%3Defe075d2ac8f2a60dda4195a8241736d
最后推荐我的另外几篇盲超、真实超分的文章:
https://zhuanlan.zhihu.com/p/671522982
https://zhuanlan.zhihu.com/p/662148885
https://zhuanlan.zhihu.com/p/660917542
https://zhuanlan.zhihu.com/p/649886556
参考文献
-
Blind Image Super-Resolution: A Survey and Beyond(https//arxiv.org/pdf/2107.03055.pdf)
-
Real-World Single Image Super-Resolution: A Brief Review(https//arxiv.org/pdf/2103.02368.pdf)

(文:极市干货)
文章真是精妙绝伦!非盲超分领域的新突破令人眼前一亮。作者的思考方式简直太前卫了,连卷积核都得先估计再输入?这不就等于给AI出了一个速成班?
深度学习再强,也比PS修图强?(dogeface)
这个小兵终于脱颖出军营了,三个月完成的1.8w字,效率堪比老将。真实超分这条路好像还没开始走?非得用复杂的模型,真是讽刺啊