

邮箱|zhouyixiao@pingwest.com
年关将至,大模型行业又热闹了起来。一天之内,两个“对标”o1的国产大模型相继发布,分别是DeepSeek的DeepSeek R1,以及Kimi的k1.5。
先是DeepSeek发布了性能比肩OpenAI o1正式版的R1,同时还公布了详尽的技术报告,并继续开源模型权重,这再次让海外技术社区感叹,“DeepSeek才配叫做OpenAI”。
几乎同一时间,Kimi发布了全新的强化学习模型k1.5,OpenAI之后首个多模态类o1模型。
去年11月,Kimi 推出了 k0-math 数学模型,12月发布了k1视觉思考模型,这次是k系列模型的第三次升级,延续了快速持续改进的节奏。

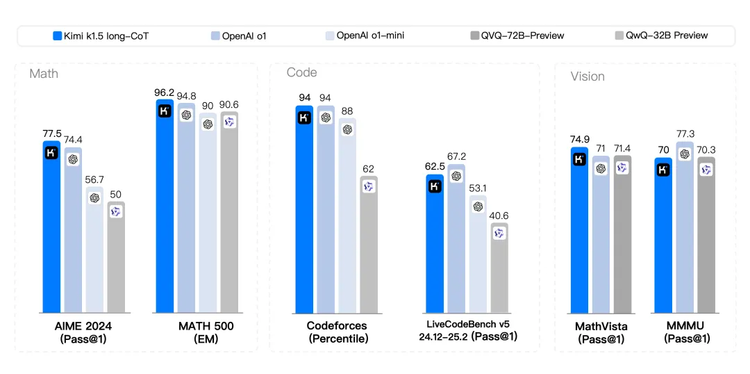
具体来看,在涵盖了数学、代码和视觉的基准测试上,k1.5的long-CoT模式(长推理)表现与OpenAI o1非常接近,在某些测试中甚至略有超越。
藏在技术报告中的“黑科技”

-
强化学习 (RL) 是关键:与大多数模型仅从静态数据中学习不同,Kimi k1.5 使用RL通过试错学习,并在奖励的指导下进行。
-
长上下文扩展:一个主要组成部分是处理非常长的文本序列的能力,最多可达128,000个 token。这是通过在训练期间使用部分展开(partial rollouts)来实现的。这意味着系统重复使用先前尝试的部分内容,而不是从头开始重新生成整个新的训练序列,从而提高训练效率。这种长上下文允许模型更详细地“思考”复杂问题,类似于规划、反思和纠正其推理过程。上下文窗口的长度通常被认为是使用RL和LLM时持续改进的关键维度。
-
改进的策略优化:RL过程使用在线镜像下降(online mirror descent)的变体进行微调。这种方法有助于模型在其解决问题的过程中做出更好的决策。这种优化通过更好的采样策略、长度惩罚和优化的数据配方得到增强。
-
简洁的框架:长上下文和改进的策略优化的结合,为使用LLM学习建立了一个简单而有效的框架。该系统不需要诸如蒙特卡洛树搜索、价值函数或过程奖励模型等复杂技术。
-
多模态:该模型使用文本和图像数据进行联合训练,使其能够利用这两种类型的信息进行推理。
-
Long-CoT到Short-CoT的迁移:该模型可以利用其长上下文推理能力来改进短推理模型。这可以通过使用长CoT激活的长度惩罚和模型合并等技术来实现。
RL数据收集
Kimi k1.5 的 RL数据收集特点在于其高质量和多样性,以及为了训练效率所做的优化。为了确保训练的有效性,数据需要涵盖广泛的学科(如 STEM、代码和一般推理),并具有均衡的难度分布。为了避免模型作弊和过拟合,会排除容易被猜测答案的问题,并使用模型自身来评估问题难度。为了提升效率,还会利用课程学习和优先采样等策略,以及局部展开的技术来处理长序列。针对代码问题,还会自动生成测试用例,针对数学问题会使用链式思考的奖励模型以提高评分准确性,并且视觉强化学习数据也分为现实世界、合成和文本渲染三种类型。
Long2short
Kimi k1.5模型使用了多种long2short(长转短)方法,通过从long-CoT模型转移知识来提升短思考short-CoT模型的性能。虽然长思考模型能够达到很好的性能,但在测试时会消耗更多的tokens。几个关键的long2short学习方法包括:
-
模型合并(Model Merging):这种方法通过对长思考模型和较短模型的权重取平均值来组合它们,在不需要额外训练的情况下得到一个新模型。
-
最短答案筛选(Shortest Rejection Sampling):这种方法对同一个问题进行多次采样,选择最短的正确回答用于监督式微调。
-
DPO (直接偏好优化) (Direct Preference Optimization):让CoT模型生成多个回答样本,选择最短的正确解决方案作为正样本,而将较长的回答作为负样本。这些正负样本对构成了用于DPO训练的成对偏好数据。
-
Long2short RL:在标准强化学习训练阶段后,选择在性能和token效率之间取得最佳平衡的模型作为基础模型。然后进行单独的长转短强化学习训练阶段,应用长度惩罚并减少最大展开长度,以进一步惩罚超过期望长度的回答。

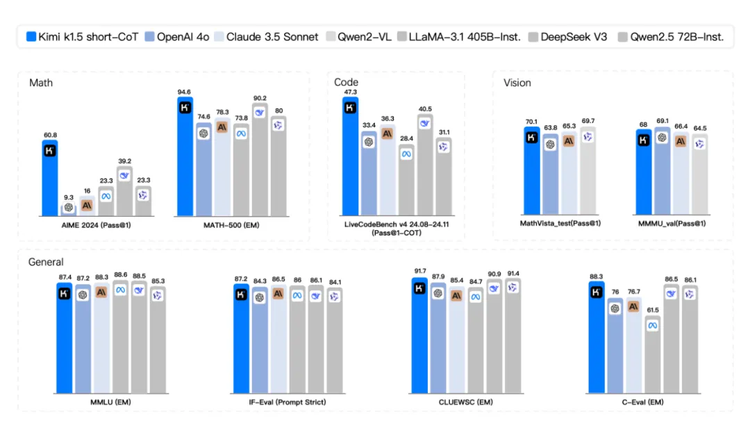
总的来说,long2short方法帮助短CoT模型从长CoT模型的推理策略中学习,用更少的token实现更好的性能。Kimi k1.5的报告显示,这可以带来性能提升,例如在AIME 2024和MATH 500基准测试上的表现。Kimi团队认为这是一个重要的研究方向,可以进一步提高语言模型的效率。
Infra的混合部署框架

系统还采用了部分展开技术来高效处理长上下文RL训练,它通过将长回答分割成多个迭代段并从重放缓冲区重用之前的片段来减少计算开销,同时包含重复检测功能以及早识别和终止重复序列。
在代码执行方面,系统配备了专门的沙箱服务,使用crun代替Docker作为容器运行时并重用cgroups,以提供安全高效的代码执行环境。
此外,系统还包含了由etcd服务管理的全局元数据系统用于广播操作和状态,以及使用Mooncake通过RDMA在对等节点之间传输检查点。这些创新组件共同构建了一个高效的训练系统框架,使Kimi k1.5模型能够有效应对长上下文和多模态数据训练的挑战。

值得注意的是,这份报告中还列出了参与研发和数据标注工作的人员名单,相对于K1.5出色的表现,贡献者名单其实很精炼,这可能印证了Kimi团队的某种人才密度。

RL+LLM,大道至简?
英伟达高级研究科学家Jim Fan第一时间对Kimi和DeepSeek两家公司发布的强化学习(RL)相关论文的评价和对比,他认为两家公司都得出了一些相似的发现,也就是简化强化学习框架,同时提升推理性能和效率。

这或许就是o1已经被“破译”的秘密,没有PRM,没有MCTS,没有复杂的配方,大规模可验证的数据让推理和自我反思在任何RL算法中涌现。
一直以来,中国人工智能企业由于在GPU上的限制,更倾向于在算法和模型设计上追求高效,降低资源消耗,例如通过框架简化、模型蒸馏和数据驱动的方法,这可能正好契合了o1背后的技术的趋势。

最近,除了发布R1,长期专注研究技术的DeepSeek开始招聘C端产品相关人才,并低调上线了C端产品;Kimi也第一次发布模型训练技术报告,在澄清某些传言的同时,释放出招揽技术人才的信号。与此同时,字节、通义、MiniMax、生数、面壁等企业也在纷纷推出新模型产品,大模型行业又热闹起来了,可以预见的是,新的一年,行业竞争也将进一步加剧。


(文:硅星人Pro)