
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本周,在阿里云通义千问 Qwen 团队提交的一篇论文中,研究人员发现了目前最热门的 MoE(混合专家模型)训练中存在的一个普遍关键问题,并提出一种全新的方法——通过轻量的通信将局部均衡放松为全局均衡,使得 MoE 模型的性能和专家特异性都得到了显著的提升。
混合专家模型(MoEs)通过路由机制动态并稀疏地激活模型参数,使得能高效地增大模型参数规模。基于 TopK 机制的稀疏激活会在训练中会遇到专家激活不均衡的问题:少数被频繁选择的专家会被优化得更多,进一步使得这些专家被更频繁地选择,最终导致只选择少数专家,造成剩余专家的冗余。因此,MoE 在训练中需要引入额外辅助的负载均衡损失(load balance loss,LBL)来鼓励专家的选择趋于均衡。
目前主流 MoE 训练框架中实现的 LBL 的优化目标是局部(micro-batch)的负载均衡,这使得模型需要将一个micro-batch的输入都均匀分配给不同的专家。然而,一个micro-batch的输入往往只来自个别领域,局部负载均衡会让模型将每个领域的输入都均匀分配。这种均匀分配会阻碍某些专家更多处理特定领域的数据,也即阻碍专家出现领域层次的分化特征。我们发现,将局部的负载均衡放松到全局的负载均衡,能显著增强专家的特异化并提高模型性能。
背景
混合专家(Mixture-of-Experts,MoE)是一种高效的在训练时扩展模型参数规模的技术。通常,一个MoE层由一个路由器(通常是一个线性层)和一组专家组成(对于Transformer的模型,每个专家是一个前馈神经网络)。给定一个输入,只有部分专家会被激活,然后它们的输出会根据路由器分配的权重进行聚合。具体来说:
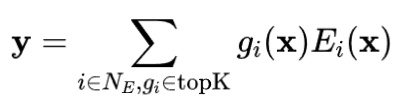
负载均衡损失
负载均衡损失是训练 MoE 网络中的一种重要正则化技术,其核心思想是鼓励所有专家的均衡激活。它可以通过以下公式计算:
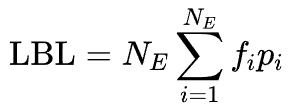
其中, 是专家 的激活频率, 是分配给专家 的平均路由分数。
然而,大多数现有的MoE训练框架(例如Megatron-core)实现的是局部(micro-batch)层次的均衡,这意味着在每个 micro-batch 内计算 LBL ,然后在全局(global-batch)层次上进行平均,即:
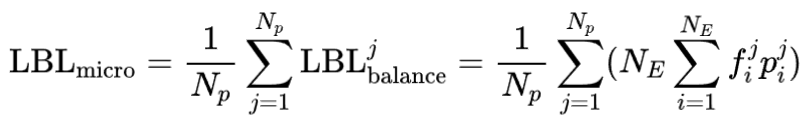
其中 为 micro-batch 数, 是在第 个 micro-batch 上计算的负载均衡损失, 为在第 个 micro-batch 上统计出的激活频率和路由分数。
我们关注的关键点是,如果一个 micro-batch 中的数据不够多样化,这种实现方式可能会阻碍专家的特异化。例如,假设一个 micro-batch 中只包含代码数据,上述负载均衡损失仍然会推动路由器将这些代码输入均匀分配给所有专家。而理想状况下,处理代码数据的专家网络应该对代码数据有更高的激活频率。在训练基于 MoE 的大型语言模型时,这种情况更常见:一个较小的 micro-batch (通常为 1)中的数据通常来自同一领域。这在一定程度上解释了为什么当前大多数基于 MoE 的大语言模型中都没有观察到明显的领域层次的专家特异化。
这一缺点促使我们将当前局部均衡的方法想办法扩展到全局(global-batch)均衡。
从局部均衡到全局均衡
得得益于 LBL 计算的格式,我们可以通过通信不同节点的 来将局部 转化为全局的 :1)在所有 micro-batch 之间同步专家选择频率 ;2)在每个GPU上计算负载均衡损失;3)在所有 micro-batch 之间聚合损失。具体来说:
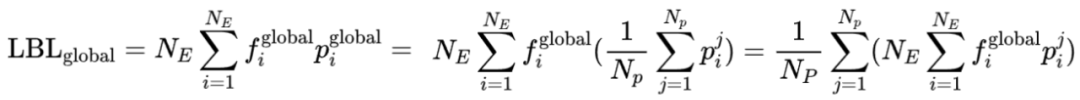
其中 是对全局统计的激活频率和门控分数,第一个等式为 的计算方式,第二个等式为全局路由分数可以由局部路由分数平均而来,第三个等式表示用全局激活频率参与局部计算后再平均聚合等价于全局均衡损失。因为 只是一个专家数大小的向量,即使是在全局通信的情况下也不会带来明显的开销。此外由于 LBL 的计算与模型其它部分的计算相对独立,还可以用计算掩盖等策略进一步消除同步 的通信开销。
此外,对于需要梯度积累的情景,我们还提出了缓存机制来累积各个积累步统计的专家激活频率,使得计算节点较少、只进行一次通信达到的均衡范围有限的情况下,也能逐渐近似全局统计的激活频率。
扩大均衡的范围带来稳定的提升
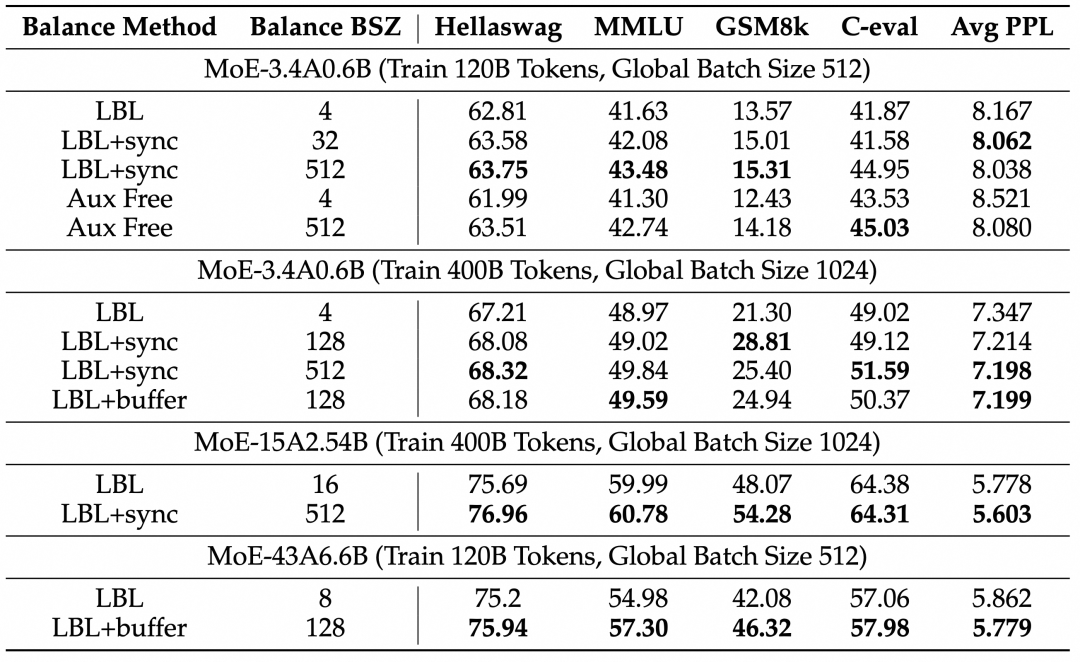
我们在三种参数规模(3.4B 激活 0.6B, 15B 激活 2.54B,43B 激活 6.6B)下分别训练了 120B 和 400B tokens,对比了不同的均衡范围(Balance BSZ)对模型性能的影响。所有模型都使用了细粒度专家、共享专家及 dropless 策略(专家不会抛弃超过容量的tokens)。可以看到,将均衡范围从一般框架实现的 4,8 或者 16 增大到 128 以上后模型在 Benchmark 指标和 PPL 都有明显提升。
我们在 3.4B 激活 0.6B 的模型训练 400B tokens 到设置上进一步对比了模型效果随着均衡范围的变化,可以看到 balance BSZ 从 2 到 128 模型的 PPL 在快速降低,在 128 后逐渐饱和。目前主流 MoE 框架中即使是进行了机内通信,对于较大的模型 balance BSZ 也一般在 8 到 16 的,这进一步体现了我们通信方法的意义。
分析实验
假设验证
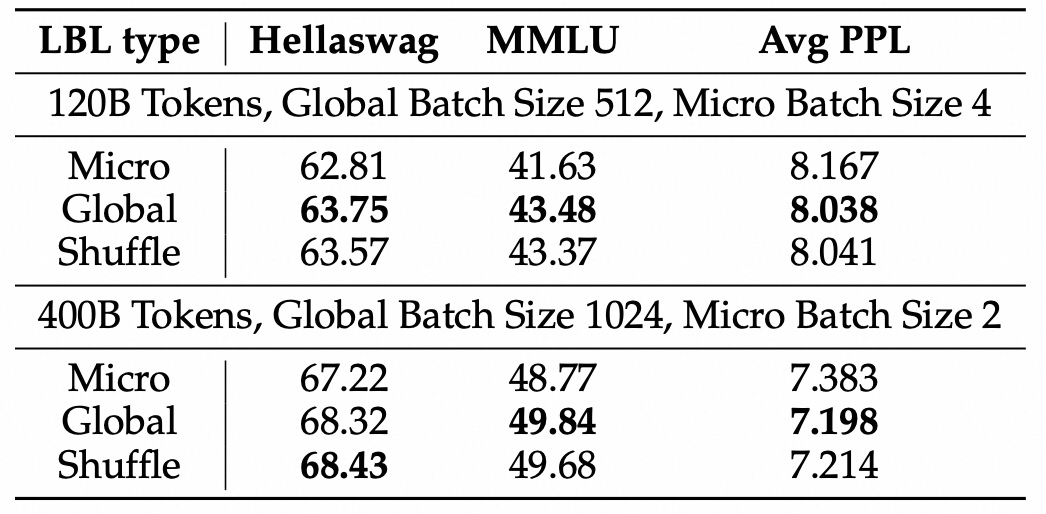
前文提到,这篇工作的出发点是在一个 micro-batch 中,数据的来源较为单一的,进而导致 MoE 模型需要将类似来源的数据均匀分配到所有expert上,我们改进了这一点进而得到了提升。
然而,我们也可以假设 global batch 是因为使用了更多的 token 来统计 expert 激活频率进而减少了方差,使得负载均衡损失更加稳定,进而提升训练洗哦啊过。位了更加严谨地对比这两种假设,我们引入了一种对比的实验设置:Shffuled batch balance, 即我们从global batch中随机抽取一个子集(这个子集的大小等于micro batch的大小)统计专家激活频率,进而计算负载均衡损失。Shuffled batch balance 和 micro-batch balance拥有相同的token数目,和 global-batch balance拥有相同的token分布。
我们发现,shuffled batch balance 和 global batch balance 的表现几乎一致,都显著好于 micro batch balance。说明,引入 global-batch 获得提升的首要原因是在一个更加通用、多样的 token 集合上计算损失。进而验证了我们的出发点和假设。
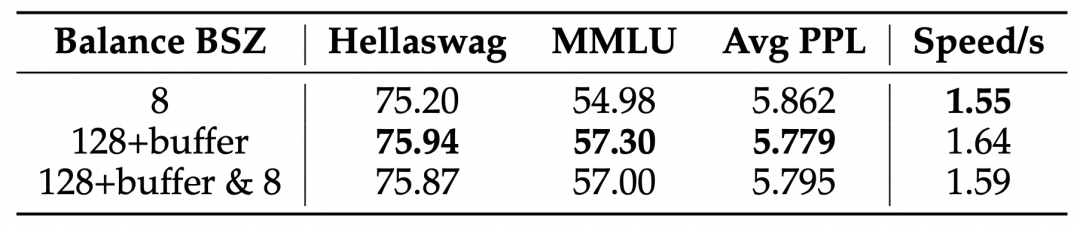
只使用全局均衡会导致局部均衡状况有所降低,这会一定程度影响 MoE 的计算效率。我们进一步实验了在主要使用全局均衡的情况下,在训练过程中添加局部均衡(默认实现的 LBL,损失权重为全局 LBL 的 1%)限制对于模型性能和效率的影响。可以看到,添加局部均衡能提升模型的速度(每个更新步耗时从 1.64秒提升到1.59秒),同时模型的效果也几乎不受影响。
同期相关工作以及讨论
已有工作 GRIN 也提出了 Global Load Balance Loss Adaptations,然而更多将这一均衡方法作为训练框架只使用张量并行、不使用专家并行的优势。GRIN 中并没有从 specialization 或是对模型 performance 影响等方面讨论使用 Global Load Balance 的动机,也没有展示单一使用 Global Load Balance 的影响。
Wang et al. 提出在基于MoE的大语言模型训练中,负载均衡损失和语言模型损失如同杠杆一样需要权衡,因为两者的优化目标并不一致。因此,他们提出了一种基于专家选择频率更新的偏差项(bais term),在不改变路由分数的情况下平衡专家选择,从而去掉了用来辅助训练的负载均衡损失(auxiliary-loss free)。基于专家选择频率更新的偏置项,以在不改变路由评分的情况下平衡专家选择。但是,他们没有比较该方法在专家选择频率是根据 micro-batch 计算和根据 global-batch 计算时的性能差异。
这项工作也被应用到 deepseek-v3 的训练中。deepseek-v3 的技术报告(同期工作)中强调了这项技术的专家选择频率是基于 global-batch 进行计算,并在小规模上讨论了基于global batch 使用 LBL 的结果,也发现这两种方法结果相似。
而我们的工作不仅在大规模上系统验证了这种方法的有效性,还详细析了均衡范围对性能的影响,并消融证明了 global-batch 是通过纳入更多样化的领域信息从而显著提性能。
结论
我们回顾了目前 MoE 训练框架中均衡损失,发现目前的实现方式会将所有来自相同领域的局部输入都均匀分配,限制了专家的分化。通过轻量的通信将局部均衡放松为全局均衡,MoE 模型的性能和专家特异性都得到了显著的提升。我们认为这一进展解决了现有MoE训练中的一个关键问题,为MoE模型的优化提供了新的视角,并有助于构建更加可解释的模型。尽管我们的实验主要集中在基于语言的任务上,我们希望我们的工作能够为在不同领域训练更大规模、更有效的 MoE 模型提供帮助。
©
(文:机器之心)




这研究真香!局部均衡太土了,全局均衡才应该是追求的目标啊。