
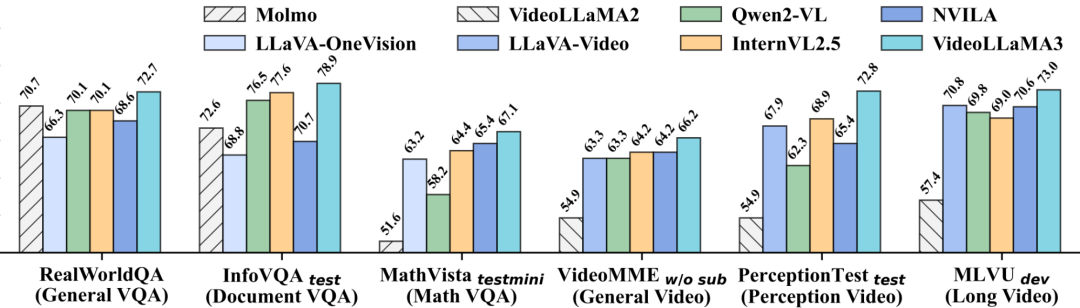
阿里巴巴达摩院发布了专注于图像和视频理解的多模态基础模型:VideoLLaMA3,一个智能看视频助手,可以看懂视频内容、理解图片、能对话。基于最新的Qwen2.5架构,支持多帧视频理解。

参考文献:
[1] https://github.com/DAMO-NLP-SG/VideoLLaMA3
(文:NLP工程化)

阿里巴巴达摩院发布了专注于图像和视频理解的多模态基础模型:VideoLLaMA3,一个智能看视频助手,可以看懂视频内容、理解图片、能对话。基于最新的Qwen2.5架构,支持多帧视频理解。
参考文献:
[1] https://github.com/DAMO-NLP-SG/VideoLLaMA3
(文:NLP工程化)