

极市导读
SpinQuant 结合了可学习的旋转矩阵以实现最佳的网络精度,把 weight,activation 以及 KV cache 量化到 4-bit 的位宽。在 LLaMA-2 7B 模型上 SpinQuant 将与全精度模型在 Zero-Shot 推理任务的精度差距缩小到仅仅 2.9 point,超过了 LLM-QAT 19.1 point,比 SmoothQuant 高了 25 point。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
采用可学习旋转矩阵量化 4-bit LLM。
后训练量化 (Post-Training Quantization) 技术可以应用于 weight,activation 以及 KV cache,其可以用来大大减少大语言模型的显存 (Memory),时延 (Latency) 和功耗 (Energy),但是当存在有异常值 (Outlier) 时就会伴随较大的量化误差。
一种去除异常值的方案是:对 activation 和 weight 参数矩阵做旋转矩阵 (Rotation)。这个操作有助于量化。
这个工作:确定了一组可以使用的 Rotation 矩阵的参数,使得全精度的 Transformer 架构输出不变,但量化精度得到提升。此外,作者发现一些 Rotation 矩阵比另一些其他的旋转矩阵的量化效果要好,比如下游任务里面 Zero-Shot 推理性能相差 13 points。
借着这个发现,本文提出了新方法 SpinQuant。SpinQuant 结合了可学习的旋转矩阵以实现最佳的网络精度,把 weight,activation 以及 KV cache 量化到 4-bit 的位宽。在 LLaMA-2 7B 模型上 SpinQuant 将与全精度模型在 Zero-Shot 推理任务的精度差距缩小到仅仅 2.9 point,超过了 LLM-QAT 19.1 point,比 SmoothQuant 高了 25 point。此外,SpinQuant 还优于同期的 QuaRot,其应用随机旋转来去除异常值。对于难以量化的 LLaMA-3 8B 模型,与 QuaRot 相比,SpinQuant 将与全精度模型的差距缩小 45.1%。
本文目录
1 SpinQuant:采用可学习旋转矩阵的 LLM 量化
(来自 Meta)
1 SpinQuant 论文解读
1.1 SpinQuant 研究背景
1.2 量化大模型的异常值问题
1.3 Rotation 矩阵的参数化
1.4 Cayley 优化旋转矩阵
1.5 实验设置
1.6 主要实验结果
1.7 学习到的 Rotation 矩阵与随机 Hadamard 矩阵对比
1.8 与 QuaRot 的对比
1.9 Rotation 矩阵功能的分析
1.10 速度测试
1 SpinQuant:采用可学习旋转矩阵的 LLM 量化
论文名称:SpinQuant: LLM Quantization with Learned Rotations
论文地址:
http://arxiv.org/pdf/2405.16406
代码链接:
http://github.com/facebookresearch/SpinQuant
1.1 SpinQuant 研究背景
大语言模型 (LLM) 在许多学科中表现出令人印象深刻的性能。SoTA 开源模型 (如 LLaMA、Mistral 等) 和一些专用的 LLM (比如 GPT、Gemini 等) 已经被广泛用于通用聊天助手、医疗诊断、电脑游戏内容生成器、编码副驾驶等。
为了服务于如此高的需求,推理成本成为一个实际的问题。很多有效的技术,比如后训练量化 (Post-Training Quantization) 作为一种有效的技术,将 weight (或 activation) 量化为低精度,从而减少显存使用,并可显著改善时延。这不仅对服务器端推理很重要,而且对小型 LLM 的在端侧部署的场景也很重要。
应用量化时,异常值 (Outlier) 对于量化来讲是一个挑战,因为它们拉伸了量化范围,使得对于绝大多数模型的数值,只有很少的有效比特位来处理。之前也有一些工作去缓解这个问题,比如 SmoothQuant[1],AWQ[2]通过权衡 weight 和 activation 之间的量化难度,或者 Atom[3]使用混合精度来处理异常值。
SpinQuant 专注于一个新的角度:将权重矩阵与旋转矩阵相乘以减少异常值并提高可量化性。受 SliceGPT[4]的启发,SpinQuant 利用旋转不变的性质从恒等映射对中构造旋转矩阵,然后集成到附近的权重,同时不影响整体网络输出。通过应用这些随机旋转矩阵,可以生成一个无异常值的 weight 和 activation 的分布,便于量化。
除了使用上述随机 Rotation 之外,本文发现量化网络的性能在不同的 Rotation 矩阵之下会有很大的差异。比如,Zero-Shot 下游推理任务的平均精度会随着旋转矩阵的不同而变化多达 13 points。因此,本文提出了 SpinQuant,它集成并优化 Rotation 矩阵,以最小化量化模型带来的损失。本文固定权重参数,使用 Cayley SGD[5]来做优化,其是一种优化正交矩阵的很成熟的技术。这种优化不会改变全精度网络输出,而是细化中间的 activation 和 weight,使它们更加量化友好。
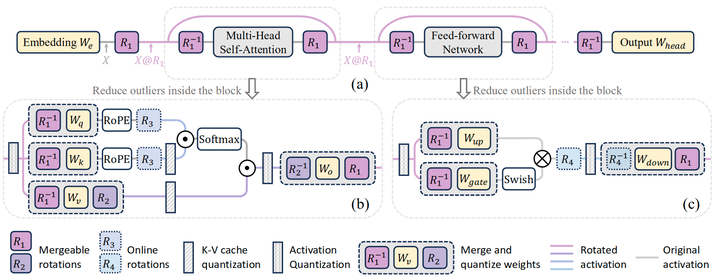
在 SpinQuant 中,作者引入了两种针对不同复杂度级别量身定制的旋转策略:SpinQuant(no had)和 SpinQuant(had)。这里,had 指 Hadamard 旋转矩阵。在 SpinQuant(no had)中,如图 1(b)所示,作者实现了 Shortcut Rotation 矩阵( )和 对 Rotation 矩阵( ),可以直接吸收到各自的权重矩阵中。在推理过程中,原始权重简单地替换为旋转的量化权重,使得无需修改前向过程。相反,在 SpinQuant(had)中,专为 KV cache 或 activation 的低比特量化的场景 (比如 4-bit),进一步结合在线 Hadamard 旋转矩阵 来解决 MLP 和 KV cache 内的 activation 异常值。
1.2 量化大模型的异常值问题
量化降低了神经网络中 weight 和 activation 的精度,以节省显存和降低延迟。量化过程可以表述为:
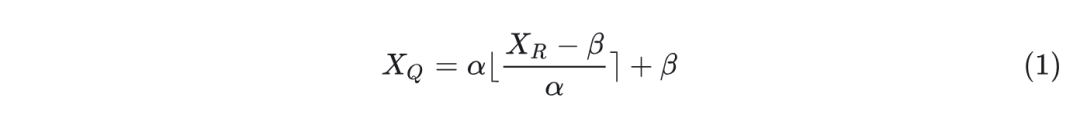
其中,在对称量化中 。在非对称量化中 。这里 是量化张量, 是实值 FP16 张量,是比特数。对于 LLM,异常值的存在拉伸了 weight 和 activation 的范围,并增加了正常值的重建误差,如图 2 和 3 所示。
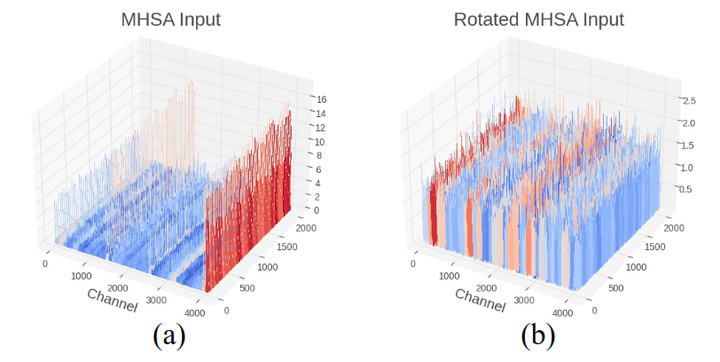
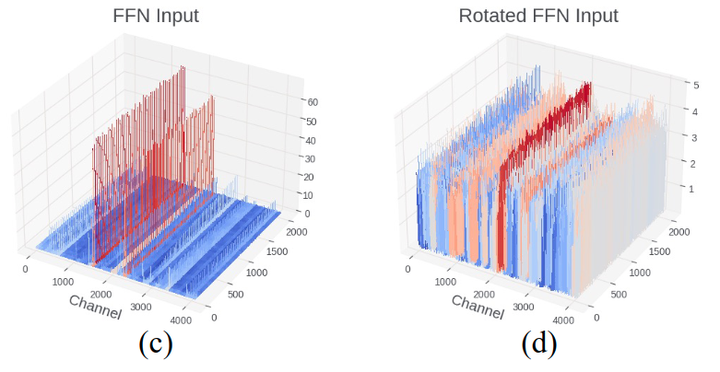
图4 说明了 Rotation 前后 activation 的峰度(Kurtosis) 的测量。 量化了实值随机变量概率分布的"尾部"。较大的 表示更多的异常值,而 表示类似高斯分布。在图 4 中,transformer中的 activation 分布包含许多异常值,其中 超过 200 。然而,将这些 activation 与随机旋转矩阵相乘后,所有层的 变为大约 3 ,表明更高斯形的分布更容易量化。图5证实了这一点,其中 activation 的量化误差在 Rotation 之后出现显著下降。
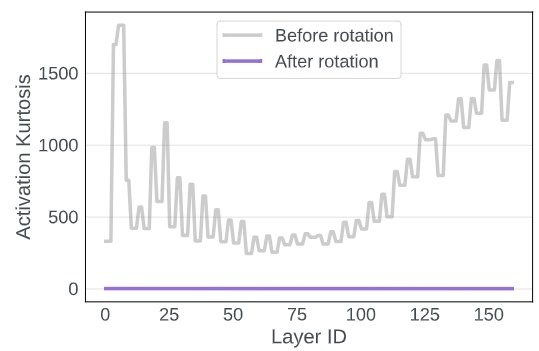

随机旋转会产生较大方差
有趣的是,虽然随机旋转可以带来更好的量化,但并非所有随机旋转都可以得出相同的量化结果。为了证明这一点,作者进行了 100 次随机试验,测试了 LLaMA-2 7B 的 Zero-Shot 的平均精度,量化为 4-bit weight 和 4-bit activation。如图 6 所示,性能的方差很大,最好的随机旋转矩阵与最差的相比差距 13 points。随机 Hadamard 矩阵优于随机 Rotation 矩阵,这与[6]中的发现一致,Hadamard 矩阵在权重最大值上产生更严格的界限。然而,即使是随机的 Hadamard 旋转矩阵在最终性能上表现出不可忽略的方差,高达 6 个点。
鉴于多种 Rotation 方案带来的巨大差异,一个自然的问题出现了:是否有可能优化旋转使其最有利于量化结果?本文提出一个可行的框架,以及面向量化的 Rotation 学习来回答这个问题,该框架在 7 个模型和 4 个低比特量化设置中始终实现高精度。

1.3 Rotation 矩阵的参数化
SpinQuant 是一个集成和优化 Rotation 矩阵的框架,目的是改善量化带来的精度损失。作者首先定义了流行的 LLM 体系结构的 Rotation 的参数化,其中包括 2 个可合并的旋转矩阵( ),它们产生旋转不变的全精度网络,以及两个在线 Hadamard 旋转矩阵 进一步减少极端 activation 和 KV-cache 量化的异常值。然后展示了如何在具有目标损失的 Stiefel 流形上优化这些旋转矩阵。
旋转残差中的 activation
如图 1(a)所示,作者通过将嵌入输出 与随机旋转矩阵 相乘来旋转残差路径中的 activation。这种旋转消除了异常值,并简化了 input activation 的量化。为了保持数值不变性,作者再给注意力和 FFN 之前乘以 。这样一来,当量化不存在时,无论是否应用旋转,全精度网络的输出都保持不变。因为在像 LLaMA 这样的 pre-Norm LLM 中,可以通过在 RMSNorm 之后将 scale 参数 合并到权重矩阵中,将 Transformer 网络转换为旋转不变网络。Rotation 矩阵可以合并到相应的权重矩阵中,如图 1(b),(c)所示。吸收后,网络中没有引入新的参数。现在,就可以自由地修改 ,而不影响浮点网络的精度了。
旋转 attention 中的 activation
如图 1(b)所示,在 attention 中,作者提出 head-wise 地将 value 的投影矩阵 乘以 , output 的投影矩阵 乘以 。 的形状为 ,不同层之间可以独立选择。数值不变性如图 7 所示,这两个 Rotation 矩阵可以在全精度网络中被抵消,因为 和 之间没有运算符。同时,它可以在不在网络中引入任何新参数的情况下,改进 value 和到 out projection 的 input activation 的量化。

作者将仅使用 和 的量化方法表示为 SpinQuant (no had),与以前的量化方法相比,该方法可以轻松实现显著的精度提升,并在 Zero-Shot 常识推理平均精度上,将 W4A8 量化 LLM 与其全精度模型之间的差距缩小 0.1 – 2.5 分。
额外的不可吸收的 Rotation 矩阵
为了进一步增强低比特(例如 4-bit)activation 量化的异常值的抑制,作者在 FFN 块内加入了 Hadamard 矩阵乘法(图 1(c)中的 ),减少了输入到 Down Projection 层的异常值。Hadamard旋转可以通过快速 hadamard 变换计算,并为推理延迟引入很低的开销。类似地,当需要低比特 KV cache 量化时,可以插入图1(b)中的 Hadamard 矩阵( )。使用 的量化方法表示为 SpinQuant(had)。
1.4 Cayley 优化旋转矩阵
已经确定图 1 中 4 个旋转矩阵 的加入可以提高量化性能,同时保持全精度网络中的数值不变。由于 是在线旋转操作,意味着它们不能被吸收到权重矩阵中,因此作者将它们保留为 Hadamard 矩阵。这是因为在线 Hadamard 变换可以在没有显著开销的情况下高效实现。然后,作者将优化目标定义为识别最小化量化网络最终损失的最优旋转矩阵 :
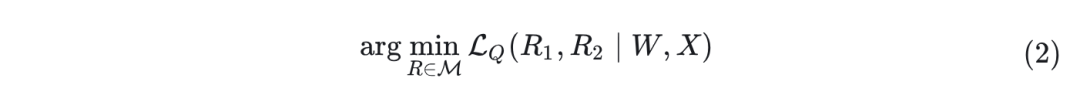
这里, 表示 Stiefel 流形,即所有正交矩阵的集合。 表示校准集上的任务损失,例如交叉熵。它是 的函数,给定固定的预训练权重 和输入张量 以及网络中的量化函数 。为了优化 Stiefel 流形上的旋转矩阵,作者采用了 Cayley SGD 方法,一种 Stiefel 流形上的高效优化算法。更具体地说,在每次迭代中,旋转矩阵 的更新如下:

其中, 是斜对称矩阵 的 Cayley 变换(即 )。 由损失函数的梯度 的一个投影计算得到:
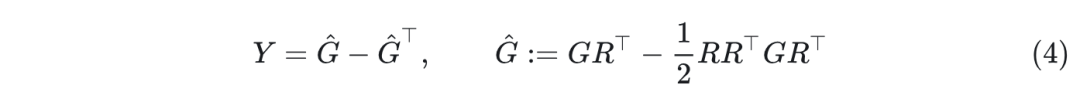
结果表明,如果 是正交的, 总是正交的,然后 就保证是正交的( 。式 3 需要一个矩阵逆,新的旋转矩阵 可以通过有效的不动点迭代 来计算。总体而言,与朴素的 SGD 算法相比,该方法每次迭代的计算时间仅为 倍,保持了正交性的性质。
作者应用 Cayley SGD 方法来求解式 2 的 ,而网络中权重参数保持冻结。仅占权重约 ,并被限制为正交的。因此,浮点网络保持不变,旋转只影响量化性能。
通过使用 Cayley 优化在 800 个样本 WikiText2 校准集上更新 100 次迭代,作者获得了一个旋转矩阵,它在 100 个随机种子中优于最佳随机矩阵和随机 Hadamard 矩阵,如图 6 所示。Cayley 优化的旋转在从不同随机种子启动时表现出最小的方差。Rotation 矩阵用随机 Hadamard 矩阵初始化进行优化。
1.5 实验设置
本文对 LLaMA-2 (7B/13B/70B)、LLaMA-3 (1B/3B/8B) 和Mistral 7B 模型进行了实验,对所提出的 SpinQuant 的评估是在 8 个 Zero-Shot 常识推理任务上进行的。这些任务包括 BoolQ、PIQA、SIQA、HellaSwag、Winogrande、ARC-easy 和 ARC-challenge 和 OBQA。此外,还报告了 WikiText2 测试集的困惑度分数。
作者使用 Cayley SGD 来优化旋转矩阵 ,两者都初始化为随机 Hadamard 矩阵,同时保持所有网络权重不变。 是残差旋转,形状为( )。 是每个 attention 中 head-wise 的旋转,形状为( )。学习率从 1.5 开始,线性衰减到 0。作者使用 WikiText-2 中的 800 个样本来迭代优化 100 次。LLaMA-3 1B/3B/8B 只需要~13/18/30分钟,LLaMA-2 7B/13B 只需要 分钟。LLAMA-2 需要 小时,对于 Mistral- ,它需要 16 分钟。
在主要结果中,作者针对 activation 量化,而 weight 保持为 16-bit 的网络优化 Rotation 矩阵。在 Rotation 矩阵学习完之后,将 GPTQ 应用于旋转之后的 weight。校准集方面遵循 GPTQ 的做法使用来自 WikiText-2 的 128 个样本,序列长度为 2048,作为量化的校准集。
1.6 主要实验结果
在图 8 中,作者使用 7 个模型和 4 个最常用的位宽设置来提供在实践中应该选择旋转方案的指导方针。注意SpinQuant(no had)只使用学习到的旋转矩阵 ,在学习旋转矩阵之后,推理时可以将其合并到相应的模型权重中。使用 SpinQuant(no had)只需要用旋转的模型权重替换原始模型权重,无需修改前向传播或任何其他Kernel 支持。SpinQuant(had)包括学习旋转矩阵 和在线 Hadamard 旋转矩阵 可以用快速 Hadamard Kernel 计算,在线 Hadamard 旋转只引入了约 的时延。
如图 8 所示,在 4-bit weight 和 8-bit activation 的情况下,使用 SpinQuant (no had) 可以轻松获得良好的性能。例如,SpinQuant (no had) 将 4-8-8 量化的 Mistral 7B 提高了 10.5 分。在 LLaMA-3-8B 中,与 GPTQ 在 4-8-16 设置下相比,SpinQuant (no had) 实现了超过 4.1 分的改进,并与全精度网络的精度差距只有 1.0 分。在这些 activation 不需要严重量化的场景,SpinQuant (no had) 已经是一个可行的解决方案,添加额外的在线 Hadamard 旋转只产生边际效益。
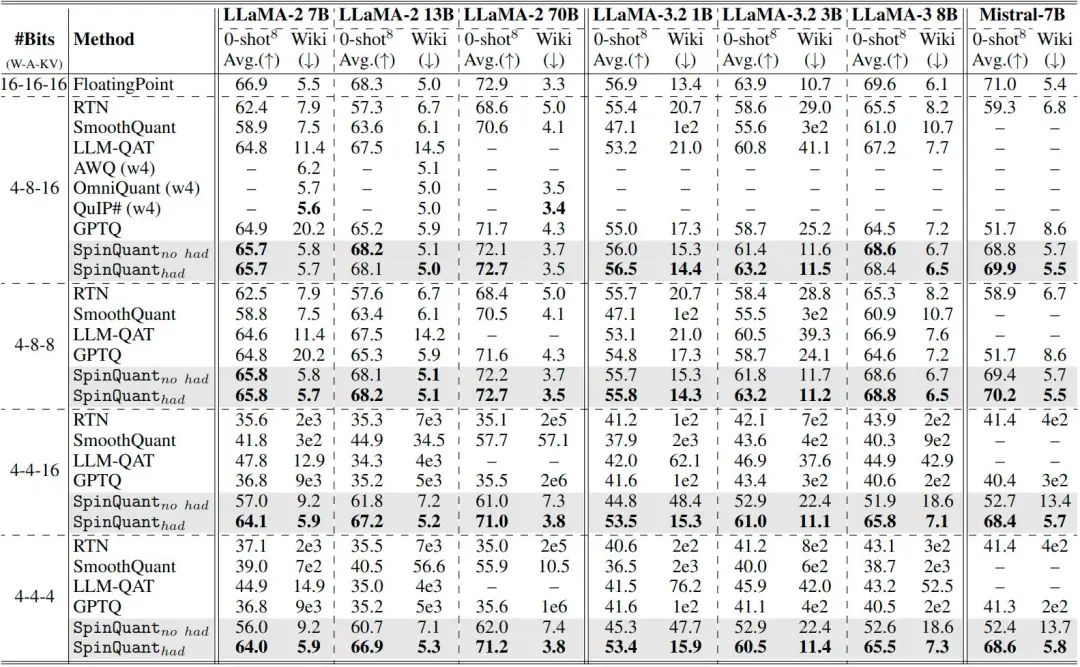
相比之下,当 activation 量化为 4-bit 时,精度显著下降,大多数以前的方法无法产生有意义的结果。SpinQuant no had) 将差距缩小了多达 20 分。在 4-4-4 量化的 LLaMA-2 模型上,SpinQuant (no had) 在 7B 模型结果显著超过 LLM-QAT,在 13B 模型上优于 SmoothQuant 20.2 分,将与相应的全精度模型的差距从 22.0 / 27.8 分降到 10.9 / 7.6 分。尽管如此,与全精度模型之间的差距仍然不可忽略。
在这种情况下,SpinQuant (had) 可以将准确率进一步提高 5 分以上,并将与相应 FP 网络的差距缩小到 2-4 分。在 4-4-4 量化 LLAMA-2 7B/13B/70B 模型中,SpinQuant (had) 与相应的全精度网络仅留下 2.9/1.4/1.7 分的精度差距,显著超过了之前的 SoTA 方法 19.1/16.4/15.3 分。
此外,与最先进的 weight-only 的量化方法 OmniQuant、AWQ 和 QuIP# 相比,SpinQuant 在 4-bit weight 和 8-bit activation 的 Wiki 数据集上实现了相似的困惑度,并且没使用矢量量化技术。这些结果表明 SpinQuant 适用于各种场景并实现最先进的性能。
1.7 学习到的 Rotation 矩阵与随机 Hadamard 矩阵对比
在图 9 中,作者将随机 Hadamard 旋转与 SpinQuant 优化旋转作了对比。使用学习到的旋转,无论是在 设置下还是在 的设置下,持续提升了各种模型和位宽配置的精度。值得注意的是,在 Mistral7B 量化中,SpinQuant (had) 比使用随机 Hadamard 旋转确保改进超过 15.7 分。鉴于优化 Rotation 矩阵的时间成本很低 (较小的模型只有 30 分钟,70B 模型只有多达 3.5 小时),因此作者主张采用优化的旋转来精确量化 LLM。

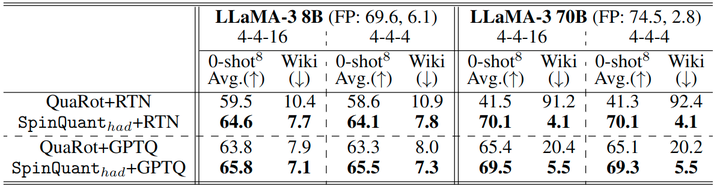
1.8 与 QuaRot 对比
QuaRot[8] 在量化网络中表现出显著的精度差异:在将 70B 模型进行 W4A4 和 W4A4KV4 的 RTN 量化时,经历了 28.1 和 33.2 点的精度下降。这种退化源于使用随机旋转矩阵的固有噪声,引入了高方差和不足的鲁棒性。相比之下,SpinQuant (had) 在各种配置中始终保持高精度,比 QuaRot 实现了 2.0 到 28.6 分的改进,如图 10 所示,同时利用更少的在线 Hadamard 矩阵:SpineQuant (had) 中的每个 Block 有 2 个,QuaRot 中的每个 Block 有 4 个)。
此外,SpinQuant 中的 有效地减少了块内异常值,使 SpinQuant (no had) 在 W4A8 设置中提供最佳性能。SpinQuant (no had) 可以通过简单地用旋转的权重替换模型权重来实现,使其比 QuaRot 更简单、更高效。因为后者需要修改模型架构和特殊的 Kernel 支持。
1.9 Rotation 矩阵功能的分析
对 weight 和 activation 进行旋转背后的基本原理可以通过一个简单的例子来说明。考虑一个表示为 2 D 向量的激活( ),其中一个条目 始终接收比 更高的激活幅值,如图 11(a)所示。将这些组件量化通常会导致以 为主的量化范围,从而影响 的精度。
从信息熵的角度来看,扩展每个轴以充分利用可用的量化范围最大化每个轴的表征能力。因此,矩阵旋转作为一个直观的解决方案出现。在 2D 场景中,将轴旋转 45° 会使值表示范围在轴上相等,如图 11(b) 所示。假设网络是一个黑盒,不知道确切的激活分布,那么通过最大度 (2D 中的 45°) 均匀旋转所有轴可以优化每个轴上的分布均匀度,部分解释了为什么 Hadamard Rotation 往往优于随机 Rotation 矩阵。

更进一步,如果已知激活分布,在量化过程中将网络视为白盒允许发现比 Hadamard 更优化的 Rotation。例如,在图 11(c-d)中描述的 3D 场景中,其中 的大小是 和 的 4 倍,将 沿 旋转 ,将最大值从[2,0.5,0.5]重新分配到 。然而,可能存在更最优的旋转策略,学习旋转可以帮助确定给定分布最有效的旋转。
这就开辟了有趣的研究silu,例如确定给定具有已知异常值轴和幅度的激活分布,最优旋转矩阵的封闭形式解。而且,这种理论上计算的 Rotation 矩阵是否可以产生最优的量化性能,作者认为值得未来研究。
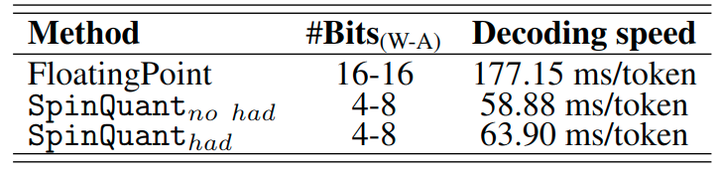
1.10 速度测试
作者在 MacBook M1 Pro CPU (OS 版本 14.5) 上使用 W16A16 和 W4A8 配置对 LLaMA-3 8B 模型进行端到端训练速度测量。图 12 中的结果表明,与 16-bit 模型相比,4-bit 量化产生了 ∼3× 的加速。将 SpinQuant (had) 与 SpinQuant (no had) 比较,在线 Hadamard 引入了 8% 的时延。因此,SpinQuant (no had) 的简洁性与 SpinQuant (had) 在低比特设置之下的高精度是一个权衡。
参考
-
^SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models -
^AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration -
^Atom: Low-bit Quantization for Efficient and Accurate LLM Serving -
^SliceGPT: Compress Large Language Models by Deleting Rows and Columns -
^abcEfficient Riemannian Optimization on the Stiefel Manifold via the Cayley Transform -
^QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks -
^Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks -
^Quarot: Outlier-free 4-bit inference in rotated llms

(文:极市干货)
SpinQuant量化技术碾压所有传统方法,4bit量化后性能依然优越!