

新智元报道
新智元报道
【新智元导读】就在刚刚,网上已经出现了一波复现DeepSeek的狂潮。UC伯克利、港科大、HuggingFace等纷纷成功复现,只用强化学习,没有监督微调,30美元就能见证「啊哈时刻」!全球AI大模型,或许正在进入下一分水岭。
在没有顶级芯片的情况下,以极低成本芯片训出突破性模型的DeepSeek,或将威胁到美国的AI霸权。 大模型比拼的不再是动辄千万亿美元的算力战。 OpenAI、Meta、谷歌这些大公司引以为傲的技术优势和高估值将会瓦解,英伟达的股价将开始动摇。
30美金,就能看到「啊哈」时刻



-
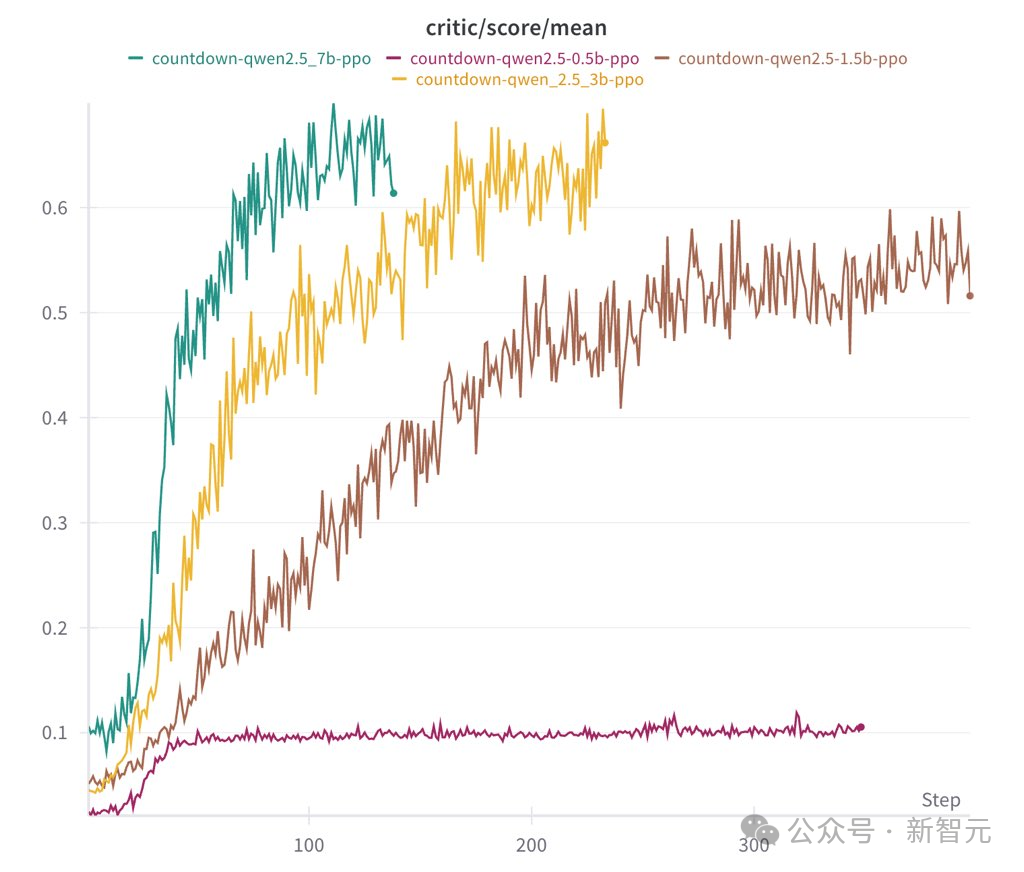
指令模型运行速度快,但最终表现与基础模型相当 -
指令输出的模型更具结构性和可读性
-
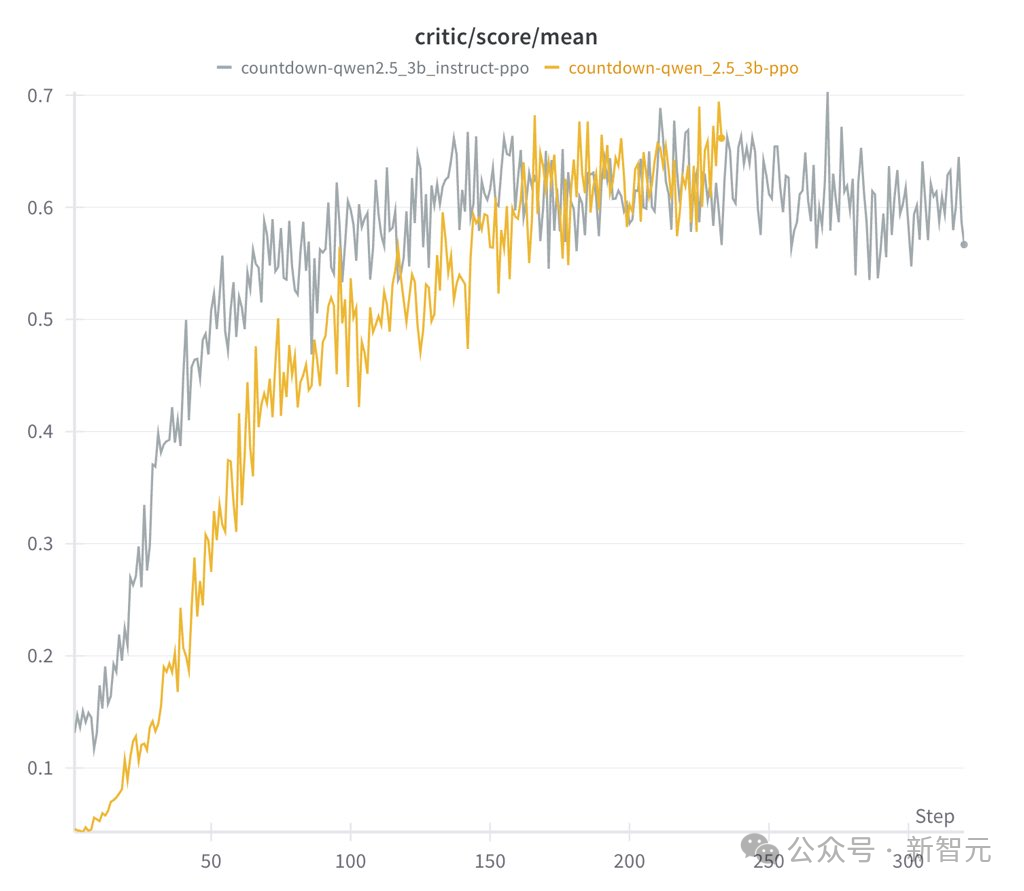
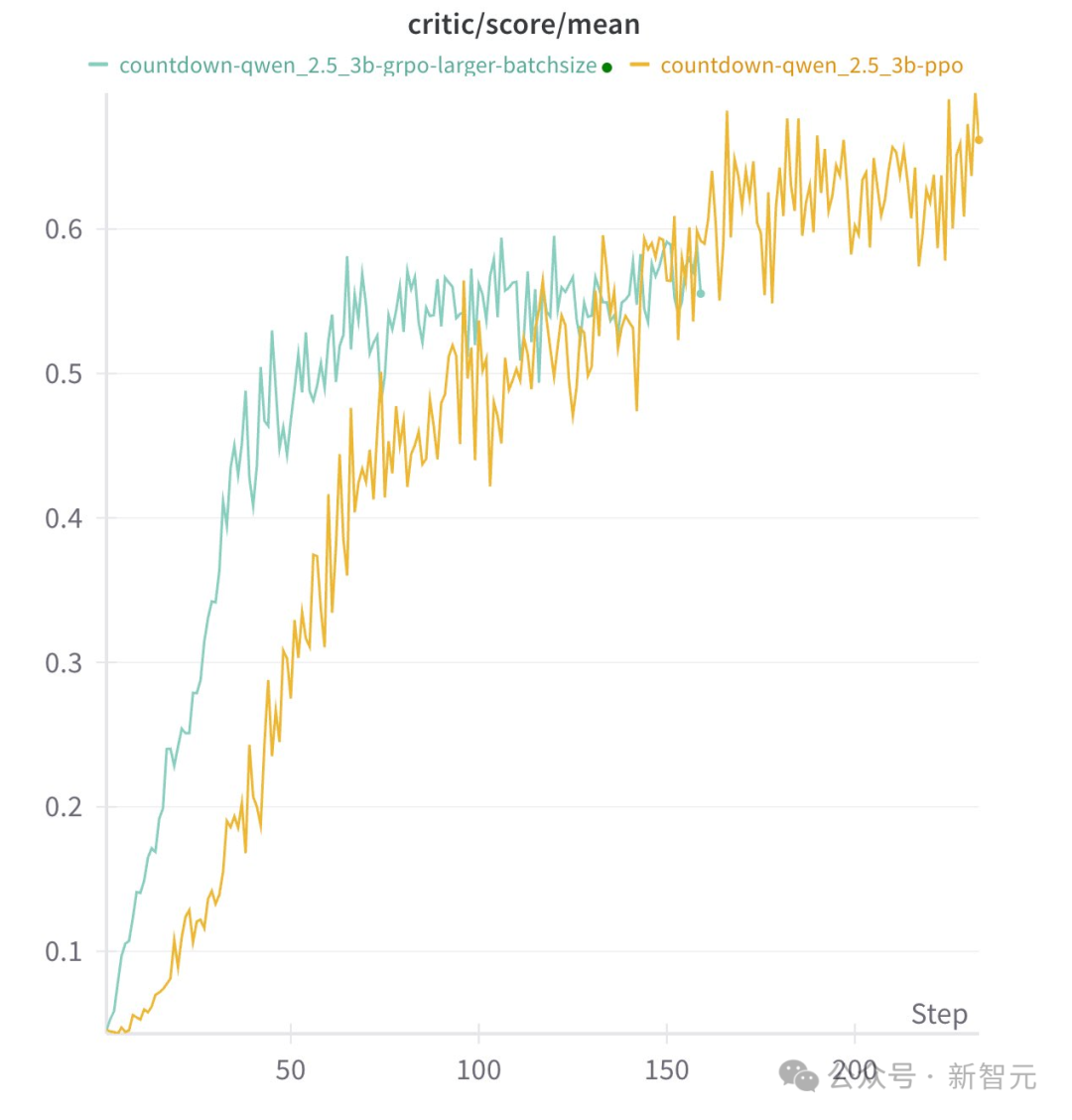
对于Countdow任务,模型学习进行搜索和自我验证 -
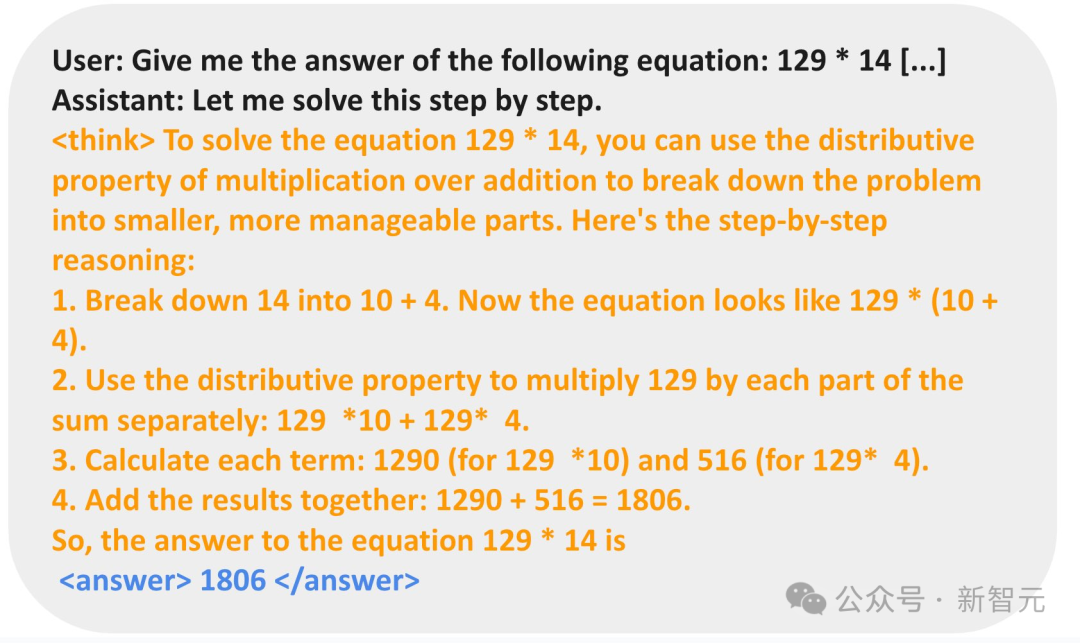
对于数字乘法任务,模型反而学习使用分布规则分解问题,并逐步解决

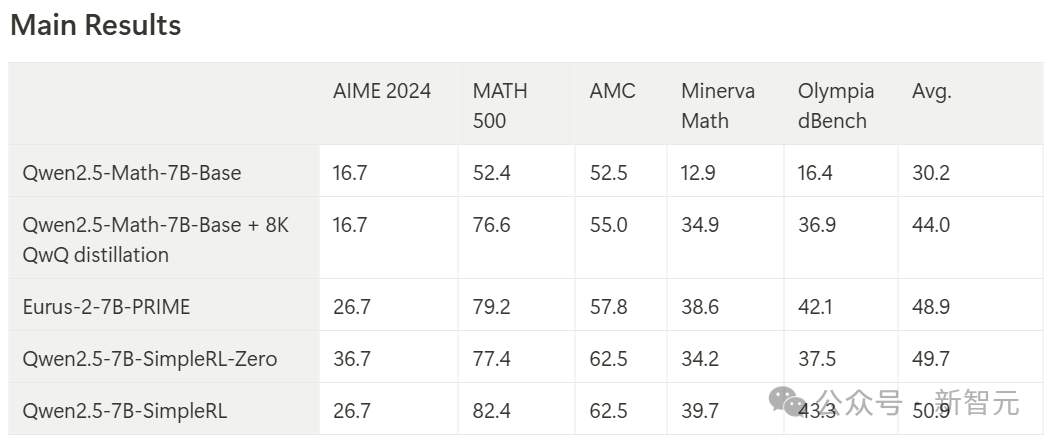
7B模型复刻,结果令人惊讶


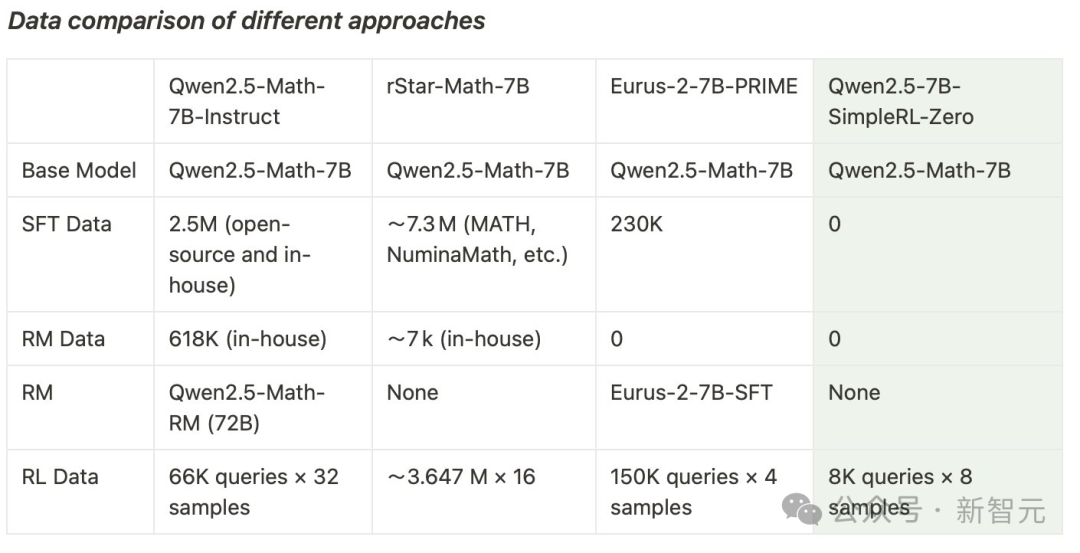

-
如果输出以指定格式提供最终答案且正确,获得+1的奖励 -
如果输出提供最终答案但不正确,奖励设为-0.5 -
如果输出未能提供最终答案,奖励设为-1
第一部分:SimpleRL-Zero(从头开始的强化学习)
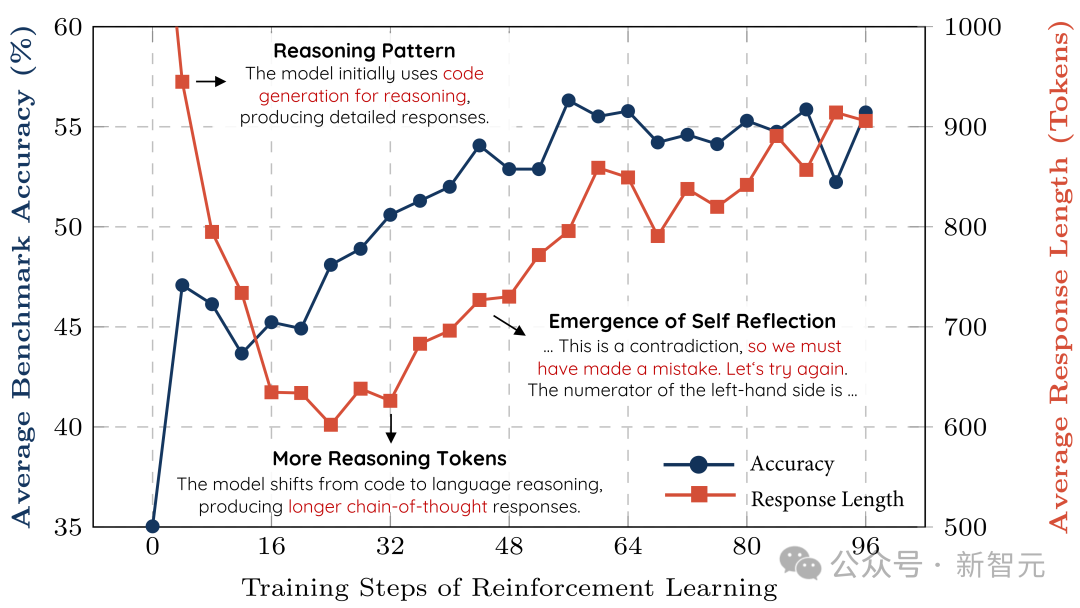
训练过程动态分析
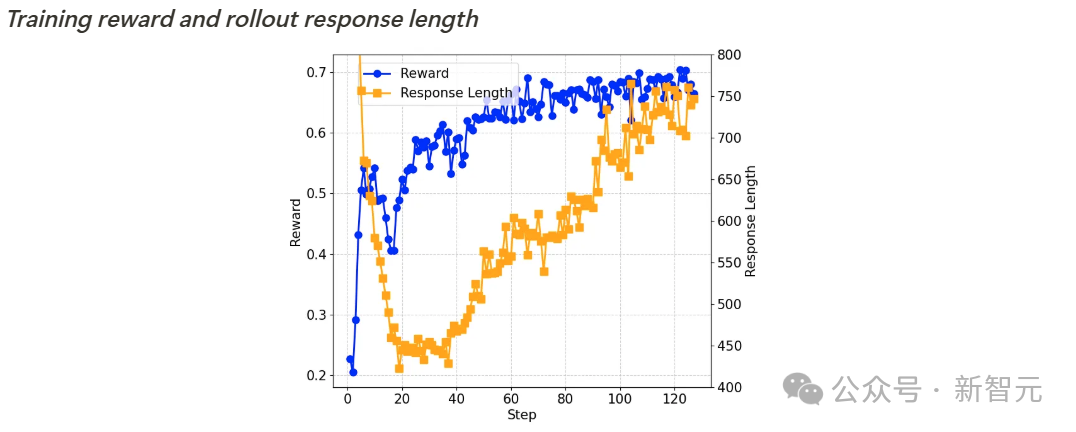
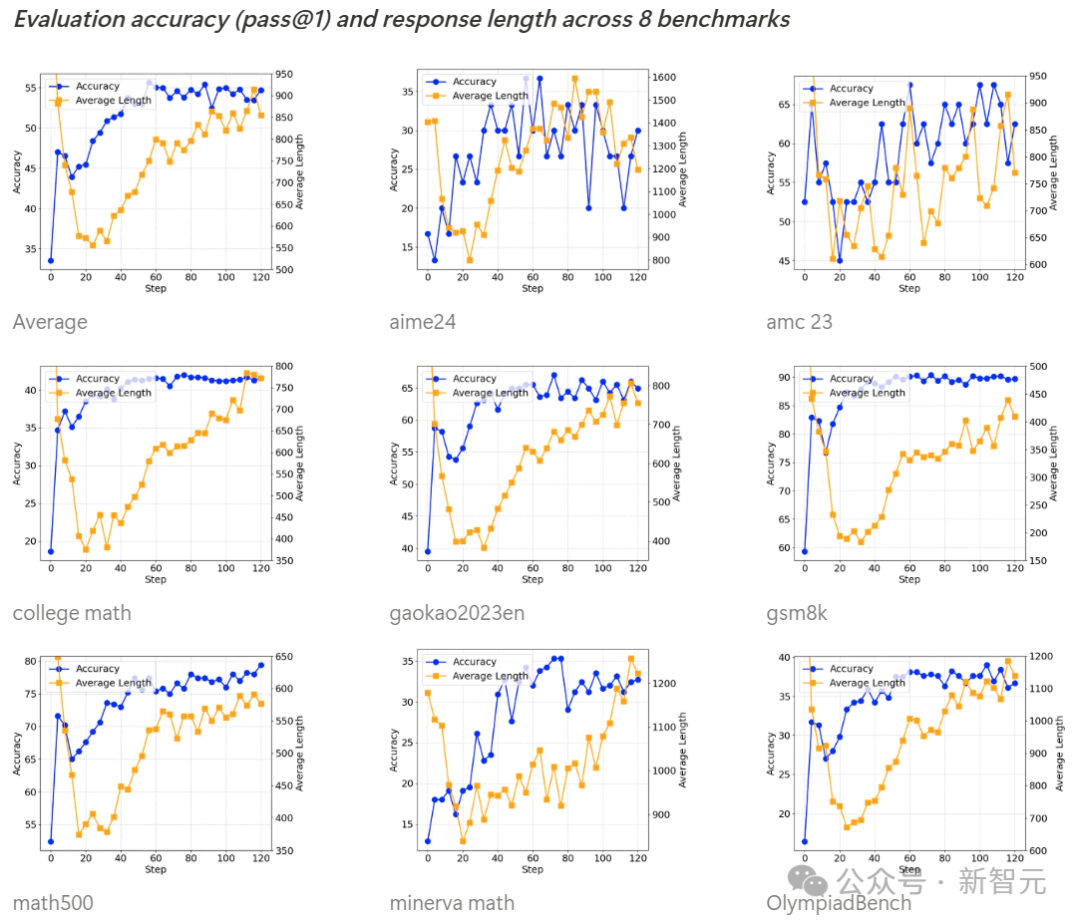
自我反思机制的涌现

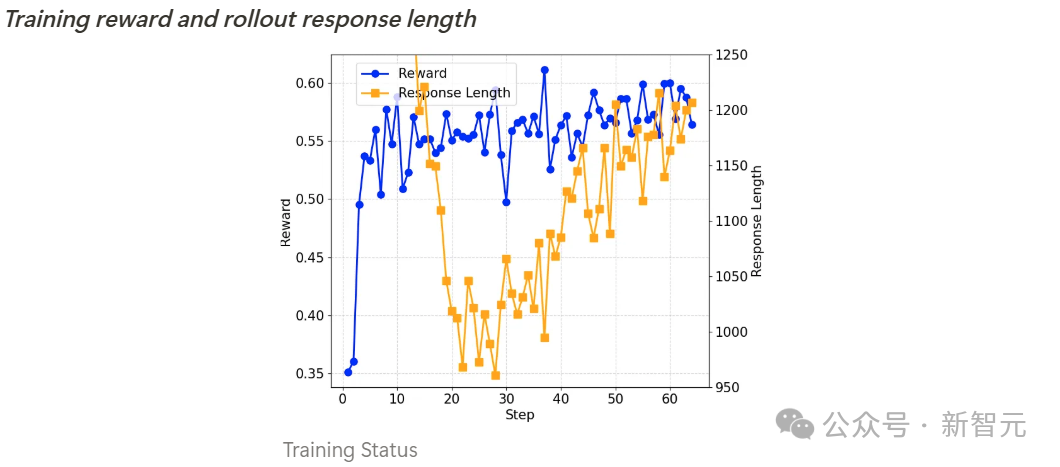
第二部分:SimpleRL(基于模仿预热的强化学习)
训练过程分析
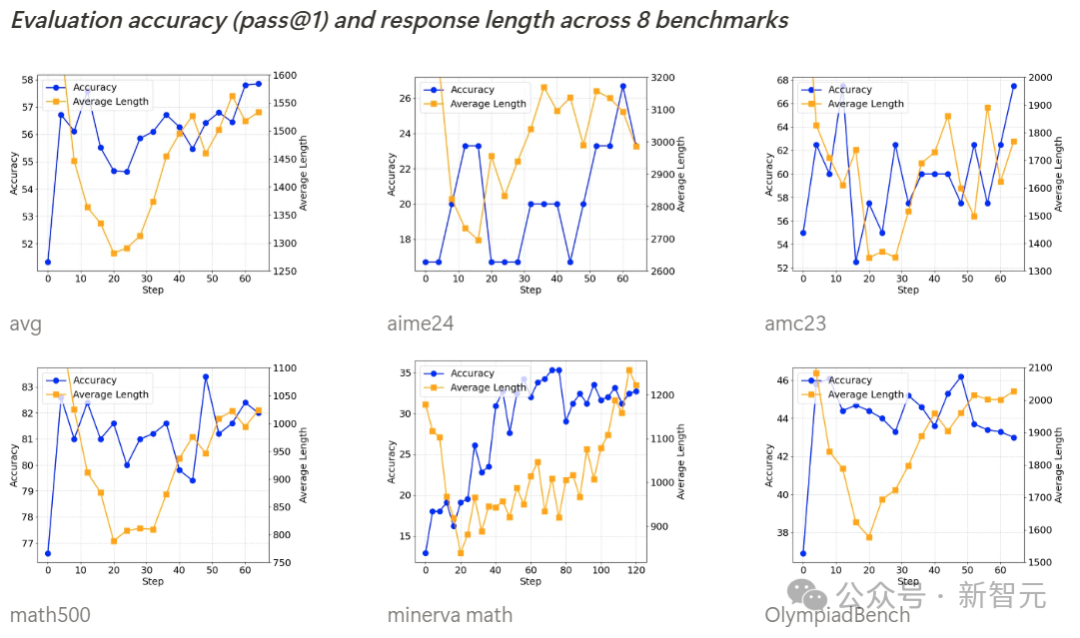
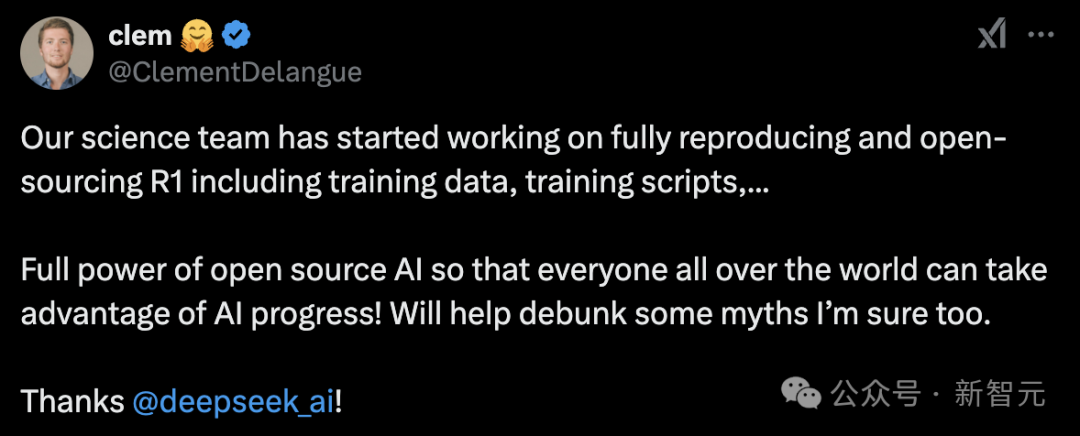
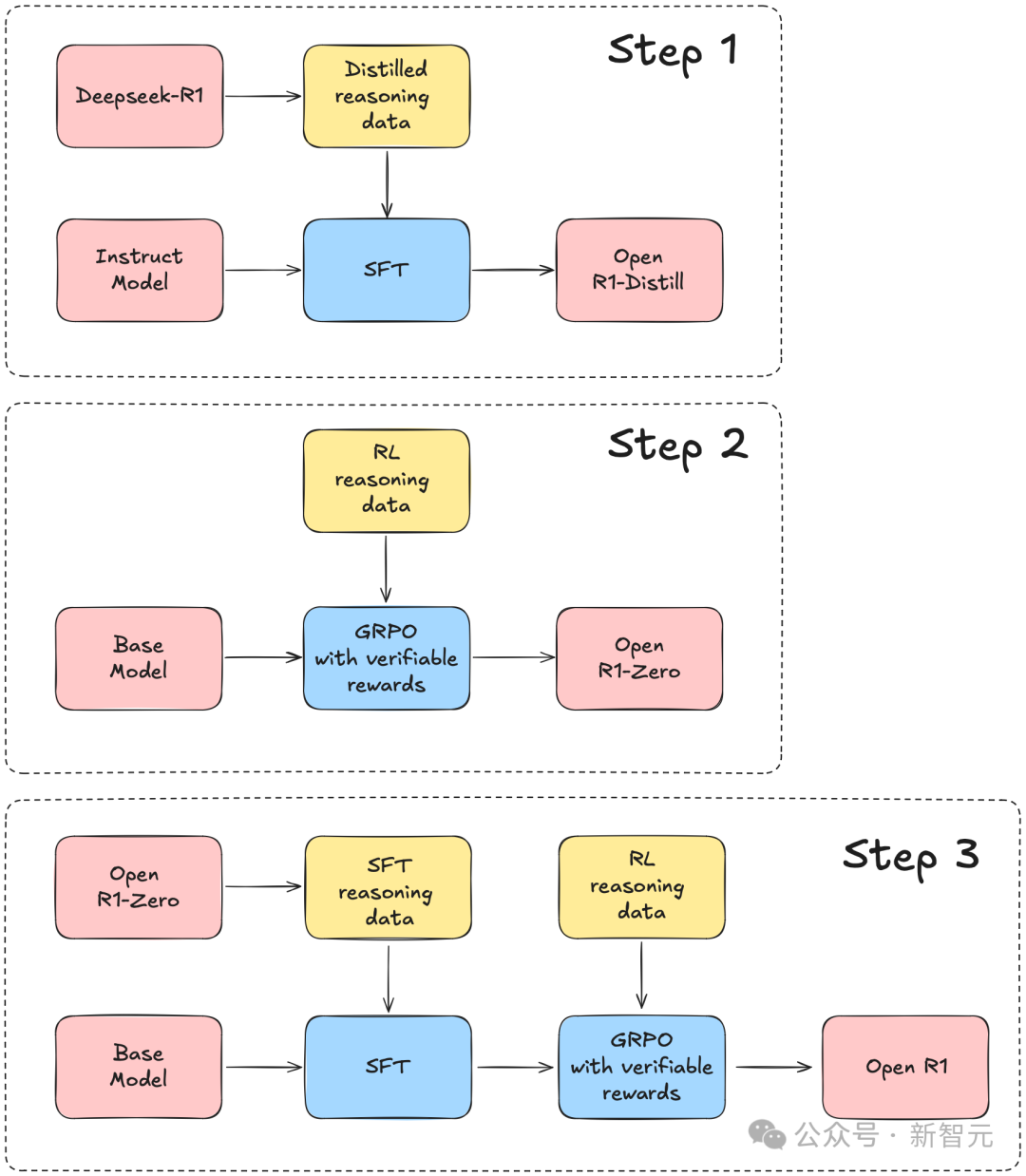
完全开源复刻,HuggingFace下场了
-
步骤 1:通过从DeepSeek-R1蒸馏高质量语料库,复现R1-Distill模型。 -
步骤 2:复现DeepSeek用于创建R1-Zero的纯强化学习(RL)流程。这可能需要为数学、推理和代码任务策划新的大规模数据集。 -
步骤 3:展示我们如何通过多阶段训练,从基础模型发展到经过RL调优的模型。
从斯坦福到MIT,R1成为首选


(文:新智元)