


新智元报道
新智元报道
【新智元导读】基于一段文本提问时,人类和大模型会基于截然不同的思维模式给出问题。大模型喜欢那些需要详细解释才能回答的问题,而人类倾向于提出更直接、基于事实的问题。
如果要你负责企业培训,培训结束需要出一份考试题目,那如今你可以选择将培训材料交给大模型,由大模型来负责出题并给出参考答案。
不过由大模型给出的考题,和人类出的题目究竟有没有差别,以及有哪些差别?
最近,加州大学伯克利分校、沙特阿拉伯阿卜杜拉国王科技城(KACST)和华盛顿大学的研究人员发表了一项研究,首次系统评价了大模型提问的能力,并指出大模型和人类的提问模式存在显著差异。

论文地址:https://arxiv.org/pdf/2501.03491
评价提问的四个维度
这项研究基于维基百科的文本,将文本拆分为86万个段落,之后通过亚马逊Mechanical Turk众包平台,由人类参与者为每个段落撰写对应的题目及答案,人类给出的文本将作为评估大模型的基准。

图1:大模型出题并评价的模式
之后,研究人员将这些段落交给主流的大模型,包括闭源的GPT-4o和开源的LLaMA-3.1-70b-Instruct,由大模型根据段落内容及上下文提问,之后对问题的评价也由大模型进行。
对问题的评价共包含6个指标,分为2组。前三个标准评估问题本身,而第二组标准负责评估反映问题质量的潜在答案。首先介绍与答案无关的标准。
大模型vs.人类,问题差异在哪
研究结果显示,首先:在问题类型上,与人类相比,大模型更倾向于提出需要描述性、更长答案的问题,大约 44%的人工智能生成问题是这一类。
这可能是因为大模型在训练过程中接触到了大量描述性文本。而人类倾向于提出更直接、基于事实的问题,例如核查具体的事实和数字,或者人物、地点、事件等。
而在问题长度上,,大模型生成的问题长度更长,而且不同模型对问题长度的偏好有所不同,例如GPT-4o 生成的描述性问题更长。而人类生成的问题更短,且不同类型的问题间长度差异较大。

图2:大模型提问的问题长度,前两行是人类参与者的问题长度
而在上下文覆盖上,人类产生的问题能更全面地覆盖上下文信息,包括句子级别和词语级别。这意味着相比人类,大模型的提问难以更全面地覆盖所有文本,往往会揪着一个细节去提问。
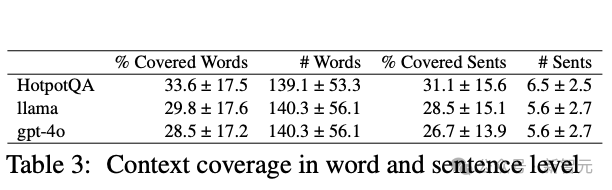
图3:大模型和人类提出问题对应的上下文在句子和单词层面的覆盖比
更值得关注的是,大模型更关注文本的前部和后部,而忽略中间部分,这一点之前的研究也有提及。
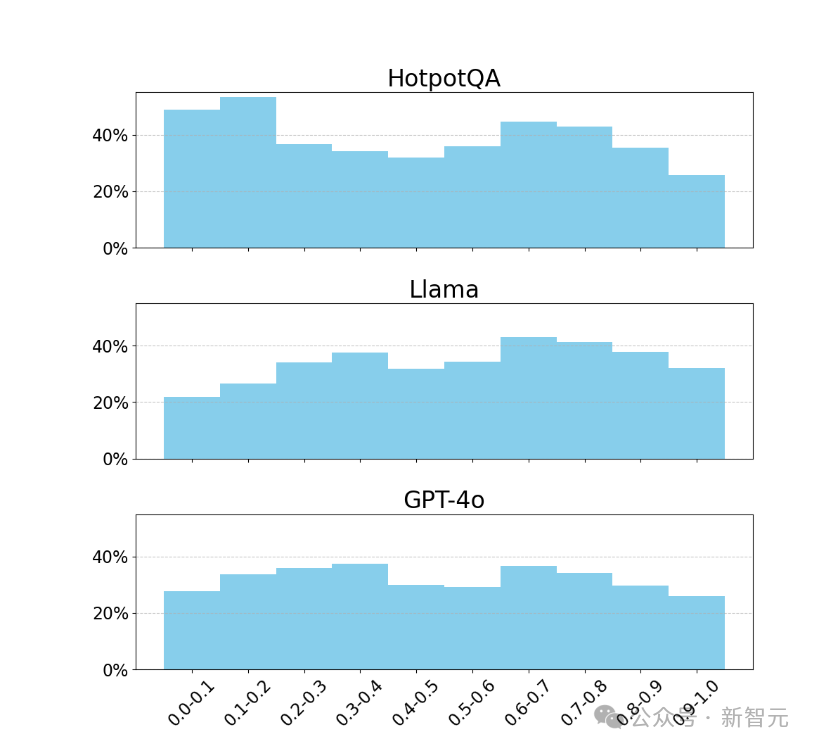
图4,大模型提问对不同位置的段落的覆盖情况
对于提出的问题是否可以被解答,需要根据上下文信息分别判断。如果提问所依据的文本包含了背景介绍,此时大模型生成的问题通常有清晰的答案。而如果文本中缺少上下文信息,缺乏常识的大模型生成的问题的可回答性会显著下降,甚至有些问题无法回答。
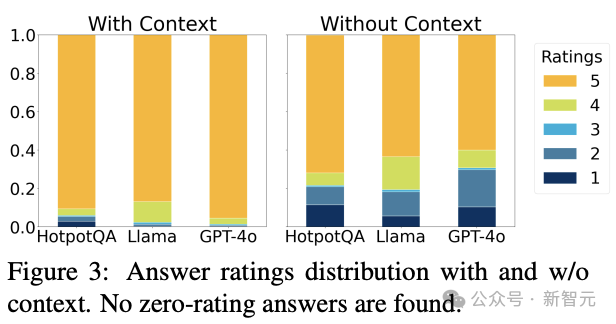
图5,对比文本包含上下文以及不包含上下文时,大模型提出的问题时具有可回答度的评分分布
类似的,由于生成模型的特性,大模型生成的问题通常需要更长的答案、包含更多细节。同时大模型生成的答案可压缩性较差:尽管可以压缩,但仍然需要比人类更长的答案。
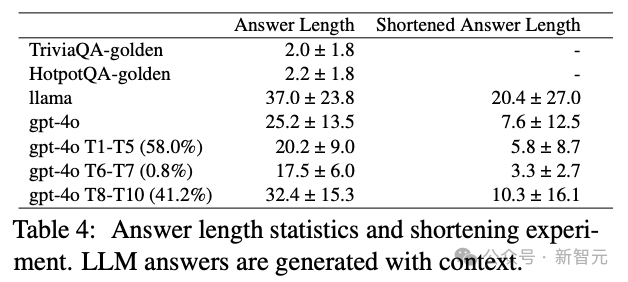
图6:大模型和人类提出问题对应的回答的长度
研究AI提问的意义
这项研究中,交给AI提问的只是一个段落,而非具有更丰富上下文的文章。未来的研究,需要考察的是大模型面对更长的文本,甚至是多篇长文本组成的书籍时会提出怎样的问题,并考察不同阅读难度、不同学科背景的文本。
如今AI生成的提问在商业产品中变得越来越普遍。例如,亚马逊的购物助手会建议与产品相关的问题,而 搜索引擎Perplexity和X的聊天机器人Grok则使用后续问题来帮助用户深入了解主题。
由于AI问题具有于区别于人类提问者的独特模式,我们就可以据此测试RAG系统,或识别AI系统何时在编造事实。
对大模型提问模式的了解,还可以帮助用户编写更好的提示词,无论是希望AI生成更类人的问题,还是要求有特定特征的问题。
随着人们越来越依赖大模型,本文最初描述的基于大模型出考试题,将会在未来变得越来越普遍,进而潜移默化地影响人类学生的思考模式,也许会让我们的下一代变得啰啰嗦嗦,或者看文章时只关注特定细节,尤其是头尾部的(考核中的重点)。
不过大模型的提问模式也是可以微调的,知道了大模型提问和人类的差异,我们就可以有针对性地进行改变。
(文:新智元)