

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
金融时报消息,OpenAI 表示,它有证据表明国内大模型平台DeepSeek 使用其模型来训练竞争对手。
大模型蒸馏是行业中训练模型的一种很普遍的方法。令人担忧的是,DeepSeek可能正在这样做以建立竞争对手模型,这是违反OpenAI的服务条款。
OpenAI拒绝进一步评论或提供证据的详细信息。
但有趣的是,OpenAI的CEO Sam Altman才刚刚赞扬了DeepSeek的R1模型,称其性能很强价格却非常便宜。

对于该消息在社交平台引发巨大讨论,有网友认为,这是很正常的事情。OpenAI 也曾使用从 Twitter 和其他网站及公司获取的数据来训练其模型。还记得马斯克关闭免费 API 访问的事件吗,因为数据被盗用了。

猜测一下 OpenAI 是否会直接公布他们发现的证据。我的猜测是他们不会公布任何东西,因为这只是他们为了维持市场预期和面子找的借口。
失败者会做任何事情来避免自己看起来不好!是的,OpenAI 从来没有从互联网或其他用户那里窃取训练数据。真是失败者。
讽刺的是,OpenAI 可能会因此变得更加封闭。不太可能会公开 o3 的思维链。这在他们的强化学习中已经相当明显了,正如论文中所描述的那样。
这就是世界的运作方式——你发明了一个轮胎,其他公司就会使用这个轮胎——他们为什么要重新从头发明一个轮胎呢?

他们当然这样做了。但他们的创新远远超越了任何美国的模式。与此同时,我们还在这里为身份争论不休。如果我们不开始团结起来推动这个国家向前发展,我们荒唐的分裂将会是我们的败亡之因。

这并不是什么新鲜事,已经知道好几天了。这也并不独特,有证据表明很多模型使用了由 ChatGPT 合成的数据。

这在人工智能领域不是不可避免的吗?你如何能允许人们使用这个模型,同时又阻止他们用它来训练自己的模型呢?知识产权并不是宇宙中固有的属性,实际上恰恰相反。
那要是这么说,OpenAI还窃取了谷歌在2017年发布的Transformer架构的论文《Attention is All You Need》。

哈哈……那 OpenAI 从哪里窃取他们的数据(和过程)的呢?他们表现得好像自己创造了原始数据。但是,OpenAI不能对你没有创作的东西声称拥有权。
我真的不在乎,只要我们能免费得到一个优秀的模型!如果中国人能做那件事,那你为什么不能呢?
我猜他们会试图禁止任何中国的 AI 应用,并强迫人们使用他们的产品。
前不久,DeepSeek发布的最新模型R1对美国市场造成了巨大冲击和损失,这让硅谷的投资者和科技公司感到非常意外。由于市场担心对昂贵AI硬件的大规模投资可能变得不必要,英伟达的股价在周一暴跌17%,市值蒸发了约5890亿美元。
大模型蒸馏的核心思想是将知识从一个复杂的、性能较高的教师模型转移到一个相对简单的学生模型。教师模型通常是一个经过充分训练、具有较高准确率和丰富知识的大型模型,它可以捕捉到数据中的各种复杂模式和关系。
而学生模型则是希望在保持一定性能的前提下,结构更加简单、算力需求更小,以便于在资源受限的设备上部署和运行。
在训练学生模型时,不仅会使用原始的训练数据和标注信息,还会利用教师模型的输出结果作为额外的监督信息。教师模型对输入数据进行推理后,会得到一个软标签(Soft Labels)分布,这个软标签包含了比原始硬标签更丰富的信息。
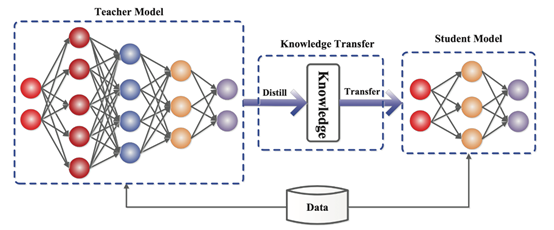
例如,在一个图像分类任务中,对于一张可能属于猫、狗、兔子三类的图片,如果真实标签是猫,硬标签就是 [1, 0, 0],而教师模型输出的软标签可能是 [0.8, 0.15, 0.05],这表明教师模型认为这张图片有 80% 的概率是猫,还有 15% 的概率是狗等,软标签能体现出模型对不同类别的
偏好程度。
学生模型在训练过程中,会同时学习拟合原始的硬标签和教师模型输出的软标签。通过最小化学生模型输出与教师模型输出之间的差异,以及学生模型输出与真实硬标签之间的差异,来调整自身的参数。
学生模型就能够学习到教师模型中的一些知识和特征,从而在结构更简单的情况下,尽可能地逼近教师模型的性能。
不过在实际应用中,蒸馏技术有多种变体和扩展。例如,除了使用教师模型的最终输出进行蒸馏外,还可以在模型的中间层进行知识传递,即让学生模型学习教师模型中间层的特征表示,这种方式被称为中间层蒸馏。
还有多教师蒸馏,即使用多个不同的教师模型来指导学生模型的训练,这样可以融合多个模型的知识,进一步提升学生模型的性能。
(文:AIGC开放社区)