

在当今数字化时代,音频语言模型的需求日益增长,尤其是在边缘设备上实现高效、准确的音频处理更是备受关注。Nexa AI推出的OmniAudio-2.6B为这一领域带来了新的突破和可能性。本文将对OmniAudio-2.6B进行全面深入的介绍,包括项目概述、技术原理、功能特点、应用场景、快速使用等方面,帮助大家更好地了解和应用这一先进的音频语言模型。
一、项目概述
OmniAudio – 2.6B 是一款高性能的多模态音频语言模型,参数量为 2.6B,能够高效处理文本和音频输入。它将 Gemma – 2 – 2B、WhisperTurbo 以及定制的 Projector 模块集成到一个统一框架中,突破了传统模型串联 ASR(自动语音识别)和 LLM(大语言模型)的架构限制,实现了更低延迟、更高效能的音频 – 文本一体化处理。这种一体化的设计使得音频信息能够直接在模型内部进行处理和转换,避免了传统架构中多次数据传输和处理带来的延迟和资源浪费。
二、技术原理
1、模型架构
Gemma – 2 – 2B:作为负责文本处理的基础语言模型,它拥有强大的语言理解和生成能力。其内部的神经网络结构经过精心设计和训练,能够对音频文本转换后的文本进行深入分析和理解。例如,在处理复杂的语义关系时,Gemma – 2 – 2B 可以准确地识别出词汇之间的逻辑联系,从而为后续的语言生成提供准确的基础。
-
WhisperTurbo:是优化后的音频编码器,能够生成高质量的音频嵌入。它通过对音频信号进行特征提取和编码,将音频信息转化为模型可处理的形式。WhisperTurbo 在处理音频信号时,能够捕捉到音频中的细微特征,如语音的语调、语速变化等,这些特征对于准确理解音频内容至关重要。
-
定制Projector模块:将 Whisper 的音频 token 转化为与 Gemma 文本嵌入对齐的序列,确保音频 – 文本模态的高效融合。它通过一种特殊的映射机制,使得音频和文本在向量空间中能够准确对应,同时保持语言模型的原始性能。这种对齐方式使得模型在处理音频输入时,能够像处理文本输入一样高效地进行语言理解和生成。
2、训练方法
-
预训练阶段:基于 MLSEnglish10K 转录数据集进行基础的音频 – 文本对齐能力训练。为了支持多任务应用,数据集中引入了特殊的 <|trans**cribe|>token,用以区分语音转文本和内容补全任务,确保模型在不同场景下性能的一致性。在预训练过程中,模型通过大量的音频 – 文本对数据学习,逐渐掌握音频和文本之间的对应关系,形成初步的音频处理和语言理解能力。
-
监督微调阶段(SFT):使用合成数据集进行指令调优。数据集同样以 MLSEnglish10K 为基础,结合专有模型对上下文进行扩展,生成丰富的 “音频 – 文本” 对。通过这种方式,模型具备了更强的音频输入语义理解和会话生成能力。例如,在处理特定领域的音频数据时,模型能够根据微调数据中的领域知识,准确理解音频中的专业术语和特定表达方式。
-
直接偏好优化(DPO):利用 GPT – 4O API 对模型初始输出进行评估,标注不正确的输出为 “拒绝”(rejected),并生成替代答案作为 “偏好”(preferred)参考。为了保持 Gemma – 2 的文本处理性能,额外增加了偏好训练步骤,使用 Gemma – 2 的原始文本作为 “标准” 训练模型,在处理音频输入时匹配其高水平表现。通过 DPO,模型能够不断优化自己的输出,使其更加符合人类的语言习惯和实际需求。
三、功能特点
1、处理速度快
在 2024 Mac Mini M4 Pro 上,使用 Nexa SDK 并采用 FP16 GGUF 格式时,模型可实现每秒 35.23 个令牌的处理速度,而在 Q4_K_M GGUF 格式下,可处理每秒 66 个令牌。相比之下,Qwen2 – Audio – 7B 在相似硬件上只能处理每秒 6.38 个令牌,展示出显著的速度优势,能够满足实时音频处理的需求。例如,在实时语音翻译场景中,快速的处理速度可以确保翻译结果几乎与语音同步输出,大大提高了沟通效率。
2、资源效率高
模型的紧凑设计有效减少了对云资源的依赖,使其成为功率和带宽受限的可穿戴设备、汽车系统及物联网设备的理想选择,降低了设备的运行成本和对网络的依赖。在一些网络信号不稳定的偏远地区,或者在电池续航有限的可穿戴设备上,OmniAudio – 2.6B 能够凭借其低资源消耗的特点,稳定地运行并提供准确的音频处理服务。
3、高准确性和灵活性
尽管 OmniAudio – 2.6B 专注于速度和效率,但其在准确性方面也表现不俗,适用于转录、翻译、摘要等多种任务。无论是实时语音处理还是复杂的语言任务,OmniAudio – 2.6B 都能够提供精准的结果。例如,在处理学术讲座的音频转录时,模型能够准确识别专业术语和复杂的句子结构,生成高质量的文字转录稿。
四、应用场景
1、智能家居
可以集成到智能家居设备中,如智能音箱、智能家电等,实现语音控制和交互。用户可以通过语音指令控制家电的开关、调节温度、查询信息等,提供更加便捷的智能家居体验。例如,用户只需说出 “打开客厅的灯”,智能音箱中的 OmniAudio – 2.6B 模型就能准确识别指令并控制灯光设备,让家居生活更加智能和便捷。
2、车载系统
在汽车中,OmniAudio – 2.6B 可以用于语音导航、语音娱乐系统、车辆状态查询等功能。驾驶员可以通过语音与车辆进行交互,提高驾驶安全性和便利性。比如,驾驶员在行驶过程中无需手动操作,只需说出 “导航到最近的加油站”,车载系统就能快速响应并规划路线,避免了分心驾驶带来的安全隐患。
3、远程医疗
在远程医疗领域,该模型可以用于实时转录医生与患者的对话、翻译医疗文件和语音指令等,提高医疗服务的效率和质量,方便医患之间的沟通。例如,在跨国远程会诊中,OmniAudio – 2.6B 可以实时翻译不同语言的对话,让医生和患者能够无障碍交流,确保诊断和治疗的准确性。
4、可穿戴设备
如智能手表、智能耳机等可穿戴设备可以利用 OmniAudio – 2.6B 实现语音助手功能,用户可以通过语音查询天气、设置提醒、发送短信等,为用户提供更加便捷的操作方式。比如,用户在运动时双手不方便操作,只需对着智能手表说出 “设置明天早上 7 点的闹钟”,手表就能快速完成设置,提升了用户体验。
五、快速使用
1、在线试用
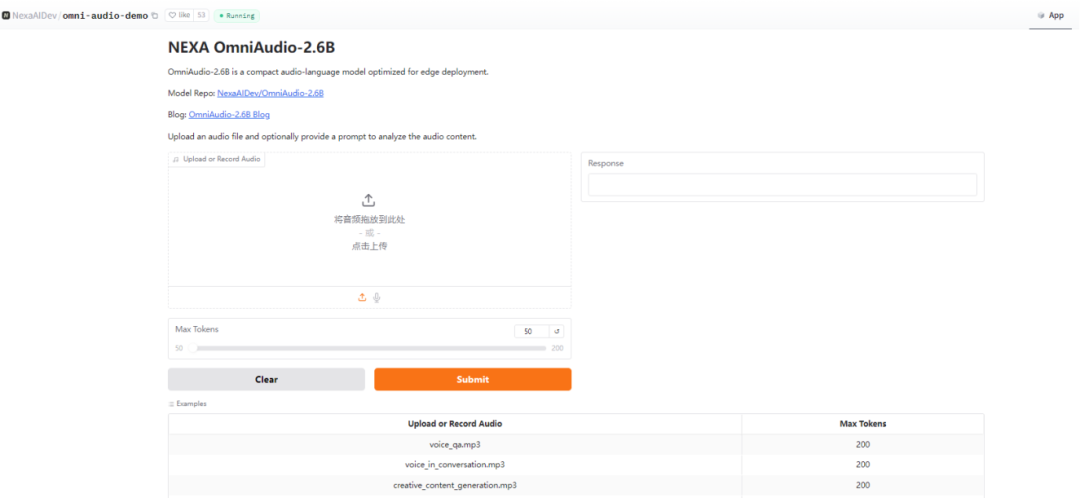
可以访问 Hugging Face Space 平台的 NexaAIDev/Omni – Audio – Demo 进行在线试用,快速体验模型的功能和效果。在这个平台上,用户无需复杂的安装和配置,只需按照界面提示输入音频或文本内容,即可获得模型的处理结果,方便快捷地了解模型的性能。
https://huggingface.co/spaces/NexaAIDev/omni-audio-demo
2、本地部署
第 1 步:安装 Nexa-SDK(本地设备端推理框架)
Nexa-SDK 是一个开源的本地设备端推理框架,支持文本生成、图像生成、视觉语言模型 (VLM)、音频语言模型、语音转文本 (ASR) 和文本转语音 (TTS) 功能。可通过 Python 包或可执行安装程序安装。
安装参考:https://github.com/NexaAI/nexa-sdk?tab=readme-ov-file#install-option-1-executable-installer
第 2 步:然后在您的终端中运行以下代码
nexa run omniaudio -st结语
OmniAudio-2.6B在音频语言建模领域迈出了重要的一步,通过将先进组件集成到一个统一框架中,实现了速度、效率和准确性的平衡,为边缘设备上的音频处理提供了强大的支持。随着技术的不断发展,相信OmniAudio-2.6B在未来会有更广泛的应用和进一步的优化升级。
模型地址:https://huggingface.co/nexaAIDev/omniaudio-2.6b
(文:小兵的AI视界)