

今天刷到Sebastian的blog,《Understanding Reasoning LLMs》,特此翻译一下,带给大家。
原文: https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
概述:
-
解释“推理模型”的含义
-
讨论推理模型的优缺点
-
概述DeepSeek R1的训练方法
-
描述构建和改进推理模型的四种主要方法
-
分享DeepSeek V3和R1发布后的LLM领域的看法
-
提供在小成本下训练推理模型的技巧
如何定义“推理模型”?
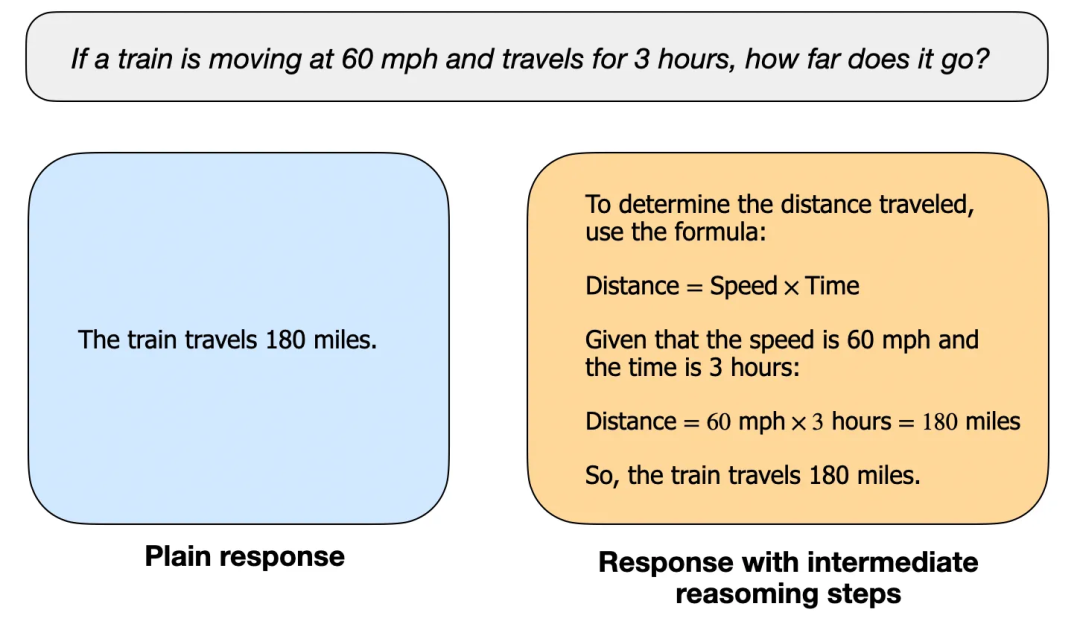
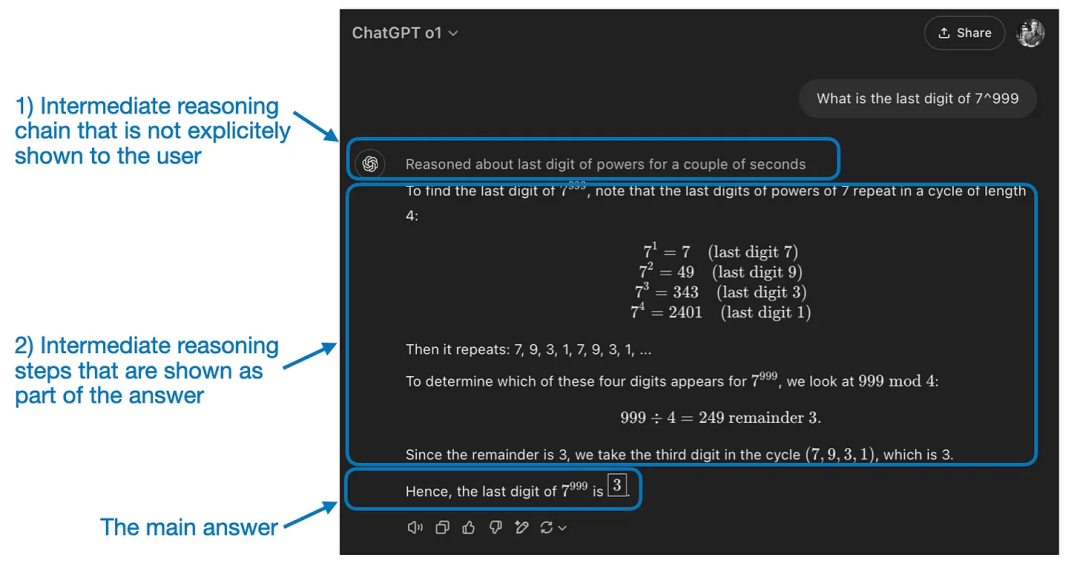
何时使用推理模型?

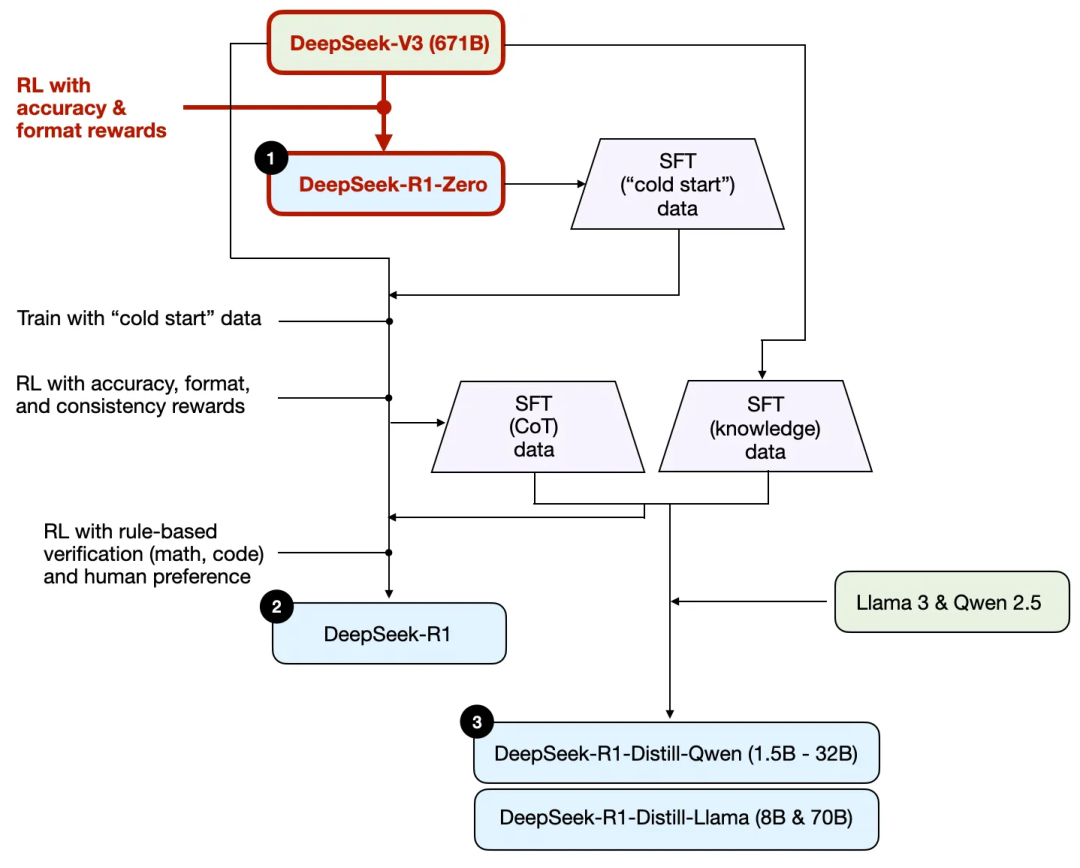
概述 DeepSeek 训练流程
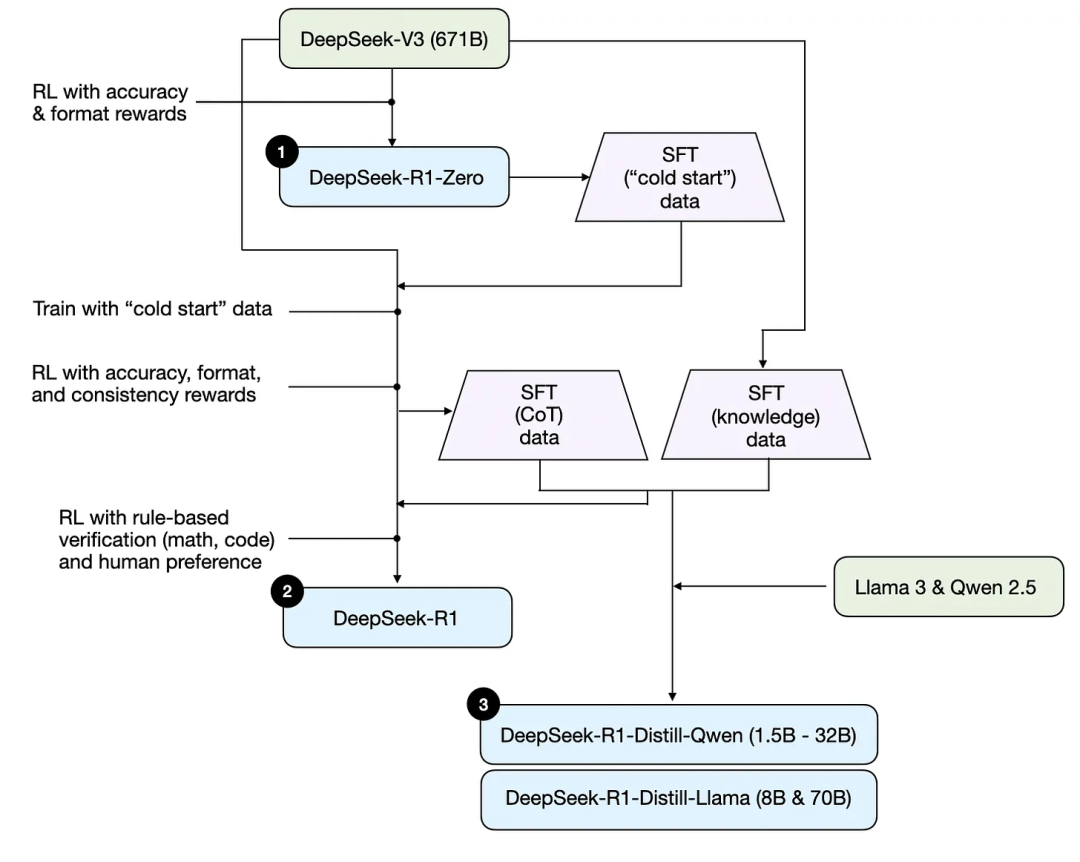
-
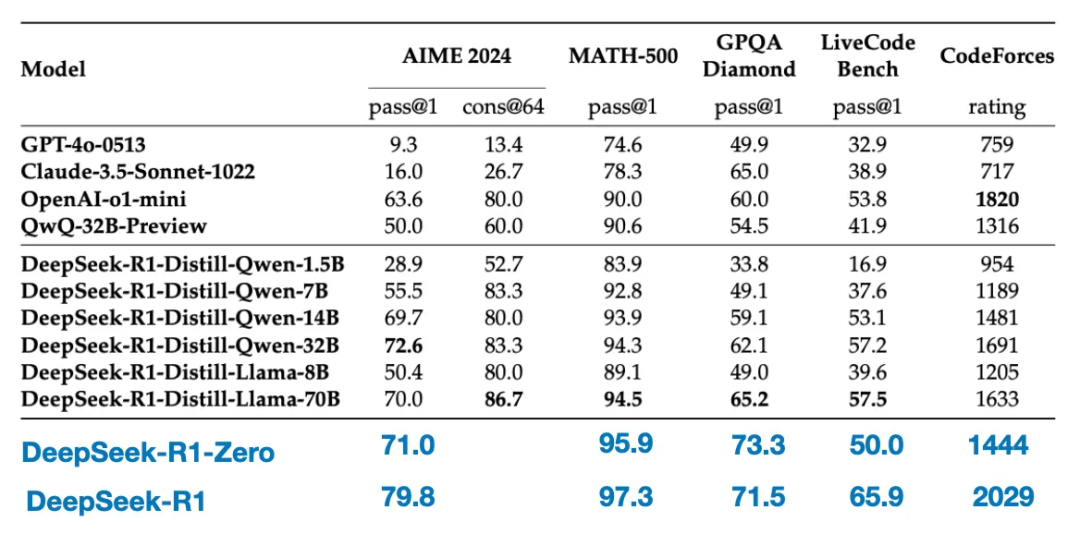
DeepSeek-R1-Zero:在DeepSeek-V3基模基础上,直接应用强化学习,不使用任何SFT数据进行冷启动。 -
DeepSeek-R1:在DeepSeek-V3基模基础上,先通过额外的SFT阶段和进一步的RL训练进一步精炼,改进了“冷启动”的R1-Zero模型。 -
DeepSeek-R1-Distill*:使用前面步骤中生成的SFT数据,对Qwen和Llama模型进行了微调,以增强其推理能力,纯SFT。
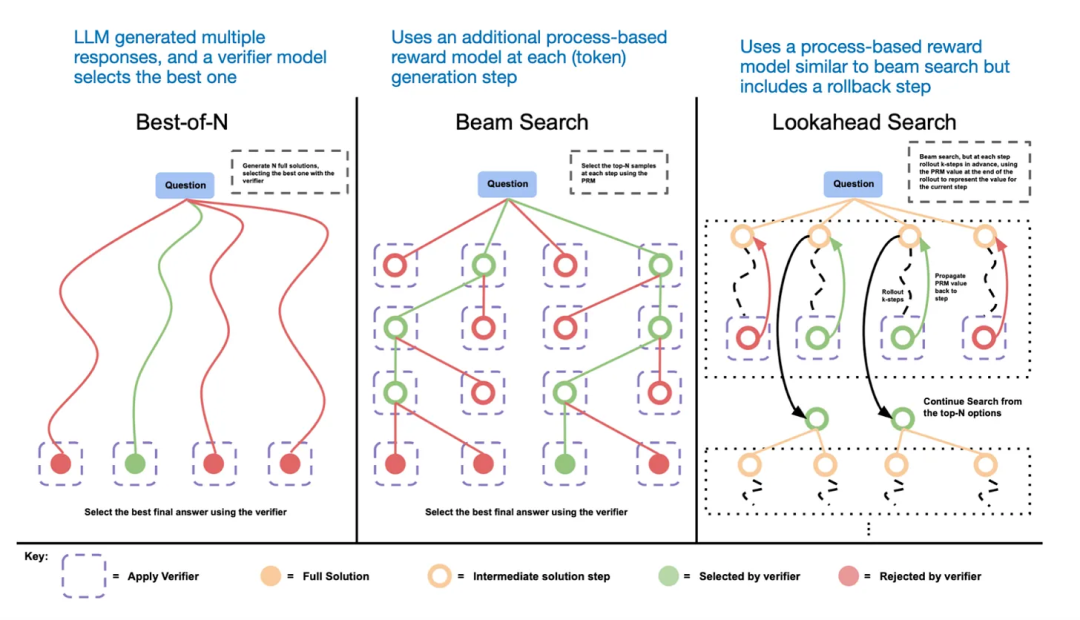
四种构建和改进推理模型的方法
Inference-time scaling

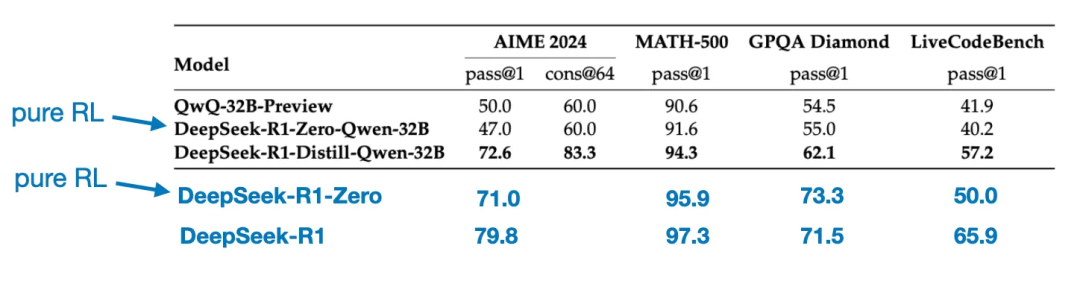
纯强化学习
-
准确性奖励,使用LeetCode编译器验证编码答案,并使用确定性系统评估数学回答。 -
格式奖励,依赖于一个LLM裁判,以确保回答遵循预期的格式,例如将推理步骤放在<think>标签内。

监督微调和强化学习
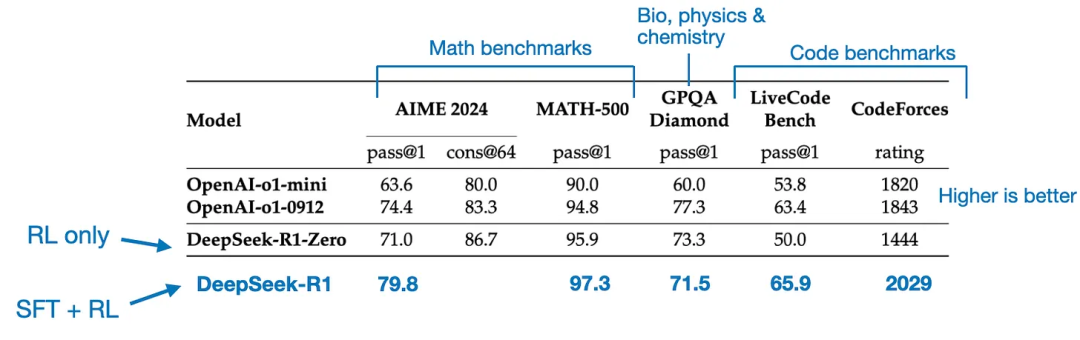
纯监督微调(SFT)和蒸馏
-
较小的模型更高效。这意味着它们运行成本更低,而且可以在较低端的硬件上运行,更吸引研究者和大模型爱好者。 -
纯SFT的方法研究。这些蒸馏模型作为一个有趣的基准,展示了纯监督微调(SFT)可以在没有强化学习的情况下将模型带到多远。
四种方法小结
-
推理时扩展不需要额外的训练,但会增加推理成本,随着用户数量或查询量的增加,大规模部署会变得更加昂贵。然而,对于已经表现强劲的模型来说,它仍然是一个不假思索的选择。我强烈怀疑o1利用了推理时扩展,这有助于解释为什么它在每个标记上的成本比DeepSeek-R1更高。 -
纯RL对于研究目的很有趣,因为它提供了关于推理作为一种新兴行为的见解。然而,在实际的模型训练中,RL + SFT是首选方法,因为它可以产生更强大的推理模型。 -
RL + SFT是构建高性能推理模型的关键方法。 -
蒸馏是一种有吸引力的方法,特别是用于创建更小、更高效的模型。然而,它的局限性在于蒸馏不能推动创新或产生下一代推理模型。例如,蒸馏总是依赖于一个现有的、更强的模型来生成监督微调(SFT)数据。
关于 DeepSeek R1 的思考
它与o1的比较
-
o1是否也是专家混合(MoE)? -
o1有多大? -
o1是否只是GPT-4o的一个稍微改进的版本,只有最少的RL + SFT和广泛的推理时扩展?
训练DeepSeek-R1的成本
在小成本下训练推理模型
好消息:蒸馏可以走很远
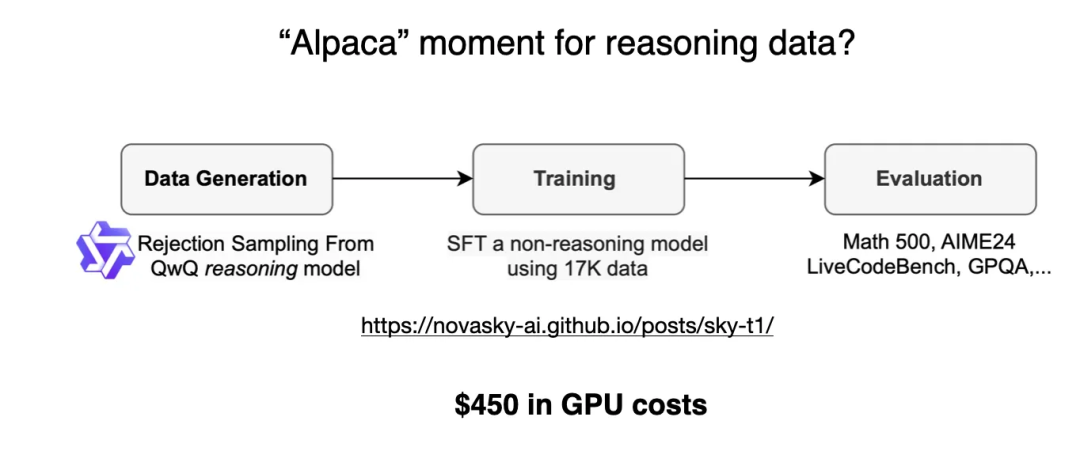
预算上的纯RL:TinyZero

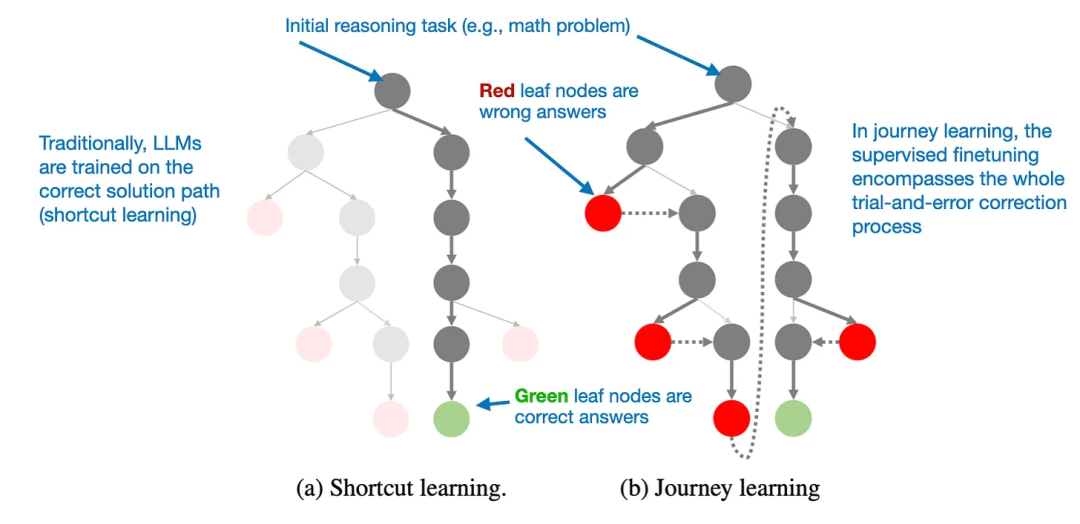
超越传统SFT:旅程学习
-
捷径学习指的是传统的指令微调方法,模型只使用正确的解决路径进行训练。 -
旅程学习则包括错误的解决路径,让模型从错误中学习。
写在最后
(文:机器学习算法与自然语言处理)